 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuda: Natural Language Queries for Visual Data Analytics
Paper and Code
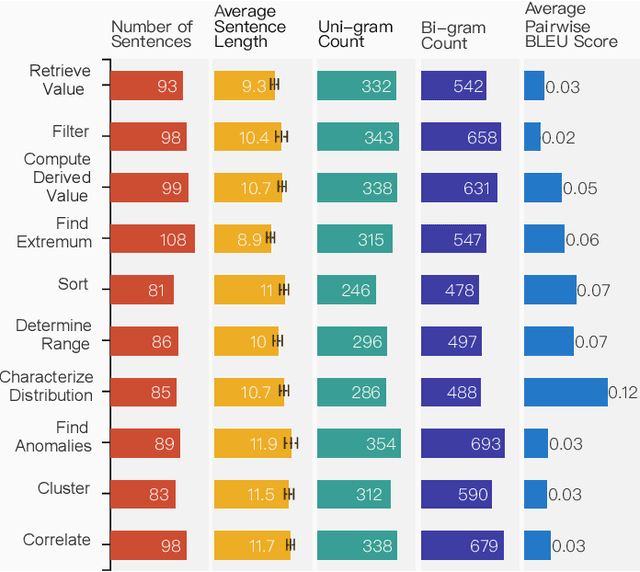
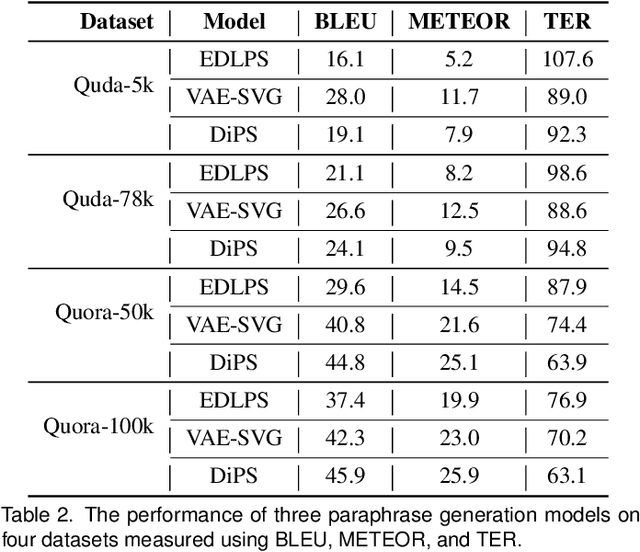
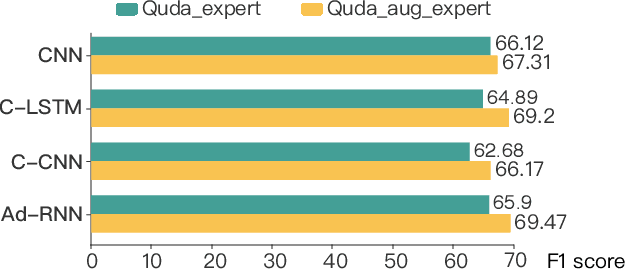
Visualization-oriented natural language interfaces (V-NLIs) have been explored and developed in recent years. One challenge faced by V-NLIs is in the formation of effective design decisions that usually requires a deep understanding of user queries. Learning-based approaches have shown potential in V-NLIs and reached state-of-the-art performance in various NLP tasks. However, because of the lack of sufficient training samples that cater to visual data analytics, cutting-edge techniques have rarely been employed to facilitate the development of V-NLIs. We present a new dataset, called Quda, to help V-NLIs understand free-form natural language. Our dataset contains 14;035 diverse user queries annotated with 10 low-level analytic tasks that assist in the deployment of state-of-the-art techniques for parsing complex human language. We achieve this goal by first gathering seed queries with data analysts who are target users of V-NLIs. Then we employ extensive crowd force for paraphrase generation and validation. We demonstrate the usefulness of Quda in building V-NLIs by creating a prototype that makes effective design decisions for free-form user queries. We also show that Quda can be beneficial for a wide range of applications in the visualization community by analyzing the design tasks described in academic publications.