 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNEX: Neuron Explore-Exploit Scoring for Label-Free Chain-of-Thought Selection and Model Ranking
Feb 05, 2026Large language models increasingly spend inference compute sampling multiple chain-of-thought traces or searching over merged checkpoints. This shifts the bottleneck from generation to selection, often without supervision on the target distribution. We show entropy-based exploration proxies follow an inverted-U with accuracy, suggesting extra exploration can become redundant and induce overthinking. We propose NEX, a white-box label-free unsupervised scoring framework that views reasoning as alternating E-phase (exploration) and X-phase (exploitation). NEX detects E-phase as spikes in newly activated MLP neurons per token from sparse activation caches, then uses a sticky two-state HMM to infer E-X phases and credits E-introduced neurons by whether they are reused in the following X span. These signals yield interpretable neuron weights and a single Good-Mass Fraction score to rank candidate responses and merged variants without task answers. Across reasoning benchmarks and Qwen3 merge families, NEX computed on a small unlabeled activation set predicts downstream accuracy and identifies better variants; we further validate the E-X signal with human annotations and provide causal evidence via "Effective-vs-Redundant" neuron transfer.
Consolidation or Adaptation? PRISM: Disentangling SFT and RL Data via Gradient Concentration
Jan 12, 2026While Hybrid Supervised Fine-Tuning (SFT) followed by Reinforcement Learning (RL) has become the standard paradigm for training LLM agents, effective mechanisms for data allocation between these stages remain largely underexplored. Current data arbitration strategies often rely on surface-level heuristics that fail to diagnose intrinsic learning needs. Since SFT targets pattern consolidation through imitation while RL drives structural adaptation via exploration, misaligning data with these functional roles causes severe optimization interference. We propose PRISM, a dynamics-aware framework grounded in Schema Theory that arbitrates data based on its degree of cognitive conflict with the model's existing knowledge. By analyzing the spatial geometric structure of gradients, PRISM identifies data triggering high spatial concentration as high-conflict signals that require RL for structural restructuring. In contrast, data yielding diffuse updates is routed to SFT for efficient consolidation. Extensive experiments on WebShop and ALFWorld demonstrate that PRISM achieves a Pareto improvement, outperforming state-of-the-art hybrid methods while reducing computational costs by up to 3.22$\times$. Our findings suggest that disentangling data based on internal optimization regimes is crucial for scalable and robust agent alignment.
ARM: Role-Conditioned Neuron Transplantation for Training-Free Generalist LLM Agent Merging
Jan 12, 2026Interactive large language model agents have advanced rapidly, but most remain specialized to a single environment and fail to adapt robustly to other environments. Model merging offers a training-free alternative by integrating multiple experts into a single model. In this paper, we propose Agent-Role Merging (ARM), an activation-guided, role-conditioned neuron transplantation method for model merging in LLM agents. ARM improves existing merging methods from static natural language tasks to multi-turn agent scenarios, and over the generalization ability across various interactive environments. This is achieved with a well designed 3-step framework: 1) constructing merged backbones, 2) selection based on its role-conditioned activation analysis, and 3) neuron transplantation for fine-grained refinements. Without gradient-based optimization, ARM improves cross-benchmark generalization while enjoying efficiency. Across diverse domains, the model obtained via ARM merging outperforms prior model merging methods and domain-specific expert models, while demonstrating strong out-of-domain generalization.
MAESTRO: Meta-learning Adaptive Estimation of Scalarization Trade-offs for Reward Optimization
Jan 12, 2026Group-Relative Policy Optimization (GRPO) has emerged as an efficient paradigm for aligning Large Language Models (LLMs), yet its efficacy is primarily confined to domains with verifiable ground truths. Extending GRPO to open-domain settings remains a critical challenge, as unconstrained generation entails multi-faceted and often conflicting objectives - such as creativity versus factuality - where rigid, static reward scalarization is inherently suboptimal. To address this, we propose MAESTRO (Meta-learning Adaptive Estimation of Scalarization Trade-offs for Reward Optimization), which introduces a meta-cognitive orchestration layer that treats reward scalarization as a dynamic latent policy, leveraging the model's terminal hidden states as a semantic bottleneck to perceive task-specific priorities. We formulate this as a contextual bandit problem within a bi-level optimization framework, where a lightweight Conductor network co-evolves with the policy by utilizing group-relative advantages as a meta-reward signal. Across seven benchmarks, MAESTRO consistently outperforms single-reward and static multi-objective baselines, while preserving the efficiency advantages of GRPO, and in some settings even reducing redundant generation.
Do LLMs Signal When They're Right? Evidence from Neuron Agreement
Oct 30, 2025Large language models (LLMs) commonly boost reasoning via sample-evaluate-ensemble decoders, achieving label free gains without ground truth. However, prevailing strategies score candidates using only external outputs such as token probabilities, entropies, or self evaluations, and these signals can be poorly calibrated after post training. We instead analyze internal behavior based on neuron activations and uncover three findings: (1) external signals are low dimensional projections of richer internal dynamics; (2) correct responses activate substantially fewer unique neurons than incorrect ones throughout generation; and (3) activations from correct responses exhibit stronger cross sample agreement, whereas incorrect ones diverge. Motivated by these observations, we propose Neuron Agreement Decoding (NAD), an unsupervised best-of-N method that selects candidates using activation sparsity and cross sample neuron agreement, operating solely on internal signals and without requiring comparable textual outputs. NAD enables early correctness prediction within the first 32 generated tokens and supports aggressive early stopping. Across math and science benchmarks with verifiable answers, NAD matches majority voting; on open ended coding benchmarks where majority voting is inapplicable, NAD consistently outperforms Avg@64. By pruning unpromising trajectories early, NAD reduces token usage by 99% with minimal loss in generation quality, showing that internal signals provide reliable, scalable, and efficient guidance for label free ensemble decoding.
PuzzleClone: An SMT-Powered Framework for Synthesizing Verifiable Data
Aug 21, 2025High-quality mathematical and logical datasets with verifiable answers are essential for strengthening the reasoning capabilities of large language models (LLMs). While recent data augmentation techniques have facilitated the creation of large-scale benchmarks, existing LLM-generated datasets often suffer from limited reliability, diversity, and scalability. To address these challenges, we introduce PuzzleClone, a formal framework for synthesizing verifiable data at scale using Satisfiability Modulo Theories (SMT). Our approach features three key innovations: (1) encoding seed puzzles into structured logical specifications, (2) generating scalable variants through systematic variable and constraint randomization, and (3) ensuring validity via a reproduction mechanism. Applying PuzzleClone, we construct a curated benchmark comprising over 83K diverse and programmatically validated puzzles. The generated puzzles span a wide spectrum of difficulty and formats, posing significant challenges to current state-of-the-art models. We conduct post training (SFT and RL) on PuzzleClone datasets. Experimental results show that training on PuzzleClone yields substantial improvements not only on PuzzleClone testset but also on logic and mathematical benchmarks. Post training raises PuzzleClone average from 14.4 to 56.2 and delivers consistent improvements across 7 logic and mathematical benchmarks up to 12.5 absolute percentage points (AMC2023 from 52.5 to 65.0). Our code and data are available at https://github.com/puzzleclone.
Com$^2$: A Causal-Guided Benchmark for Exploring Complex Commonsense Reasoning in Large Language Models
Jun 08, 2025Large language models (LLMs) have mastered abundant simple and explicit commonsense knowledge through pre-training, enabling them to achieve human-like performance in simple commonsense reasoning. Nevertheless, LLMs struggle to reason with complex and implicit commonsense knowledge that is derived from simple ones (such as understanding the long-term effects of certain events), an aspect humans tend to focus on more. Existing works focus on complex tasks like math and code, while complex commonsense reasoning remains underexplored due to its uncertainty and lack of structure. To fill this gap and align with real-world concerns, we propose a benchmark Com$^2$ focusing on complex commonsense reasoning. We first incorporate causal event graphs to serve as structured complex commonsense. Then we adopt causal theory~(e.g., intervention) to modify the causal event graphs and obtain different scenarios that meet human concerns. Finally, an LLM is employed to synthesize examples with slow thinking, which is guided by the logical relationships in the modified causal graphs. Furthermore, we use detective stories to construct a more challenging subset. Experiments show that LLMs struggle in reasoning depth and breadth, while post-training and slow thinking can alleviate this. The code and data are available at https://github.com/Waste-Wood/Com2.
Self-Route: Automatic Mode Switching via Capability Estimation for Efficient Reasoning
May 27, 2025While reasoning-augmented large language models (RLLMs) significantly enhance complex task performance through extended reasoning chains, they inevitably introduce substantial unnecessary token consumption, particularly for simpler problems where Short Chain-of-Thought (Short CoT) suffices. This overthinking phenomenon leads to inefficient resource usage without proportional accuracy gains. To address this issue, we propose Self-Route, a dynamic reasoning framework that automatically selects between general and reasoning modes based on model capability estimation. Our approach introduces a lightweight pre-inference stage to extract capability-aware embeddings from hidden layer representations, enabling real-time evaluation of the model's ability to solve problems. We further construct Gradient-10K, a model difficulty estimation-based dataset with dense complexity sampling, to train the router for precise capability boundary detection. Extensive experiments demonstrate that Self-Route achieves comparable accuracy to reasoning models while reducing token consumption by 30-55\% across diverse benchmarks. The proposed framework demonstrates consistent effectiveness across models with different parameter scales and reasoning paradigms, highlighting its general applicability and practical value.
UFO-RL: Uncertainty-Focused Optimization for Efficient Reinforcement Learning Data Selection
May 18, 2025Scaling RL for LLMs is computationally expensive, largely due to multi-sampling for policy optimization and evaluation, making efficient data selection crucial. Inspired by the Zone of Proximal Development (ZPD) theory, we hypothesize LLMs learn best from data within their potential comprehension zone. Addressing the limitation of conventional, computationally intensive multi-sampling methods for data assessment, we introduce UFO-RL. This novel framework uses a computationally efficient single-pass uncertainty estimation to identify informative data instances, achieving up to 185x faster data evaluation. UFO-RL leverages this metric to select data within the estimated ZPD for training. Experiments show that training with just 10% of data selected by UFO-RL yields performance comparable to or surpassing full-data training, reducing overall training time by up to 16x while enhancing stability and generalization. UFO-RL offers a practical and highly efficient strategy for scaling RL fine-tuning of LLMs by focusing learning on valuable data.
Joint Resource Estimation and Trajectory Optimization for eVTOL-involved CR network: A Monte Carlo Tree Search-based Approach
Apr 25, 2025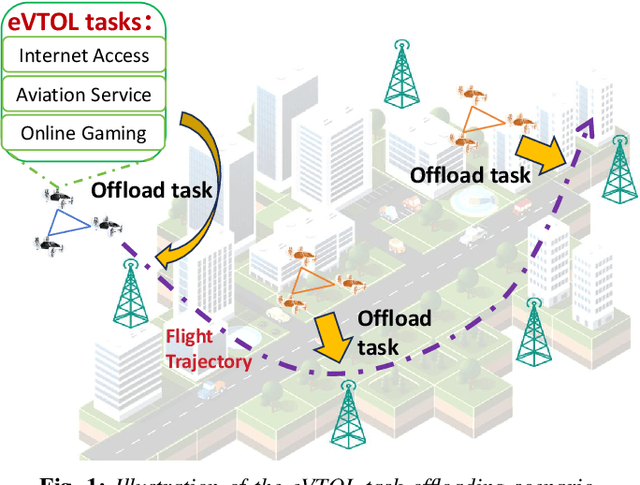
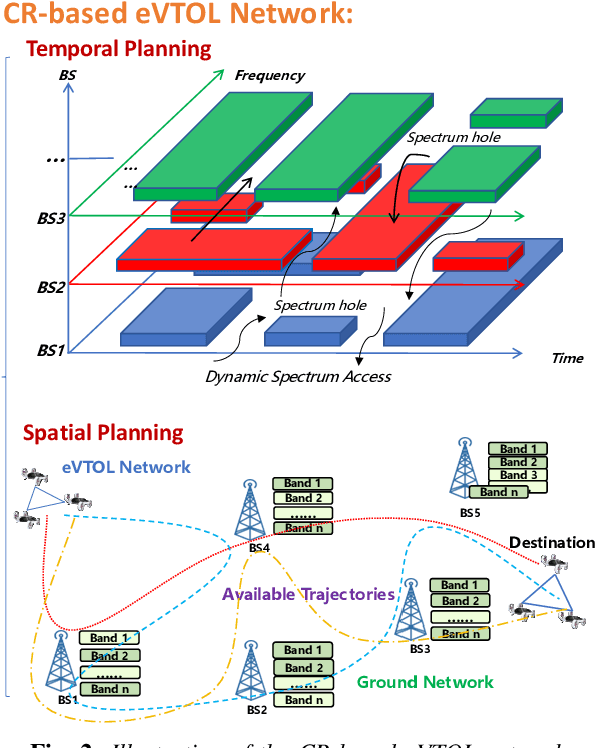
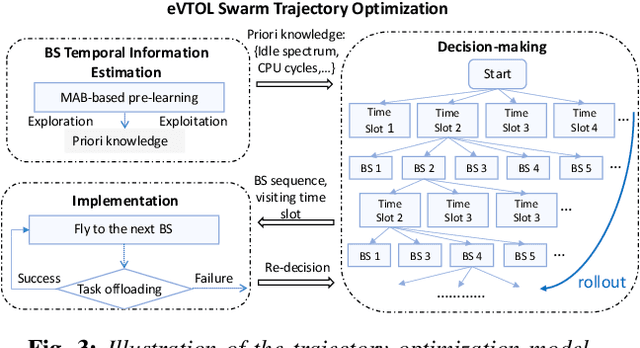
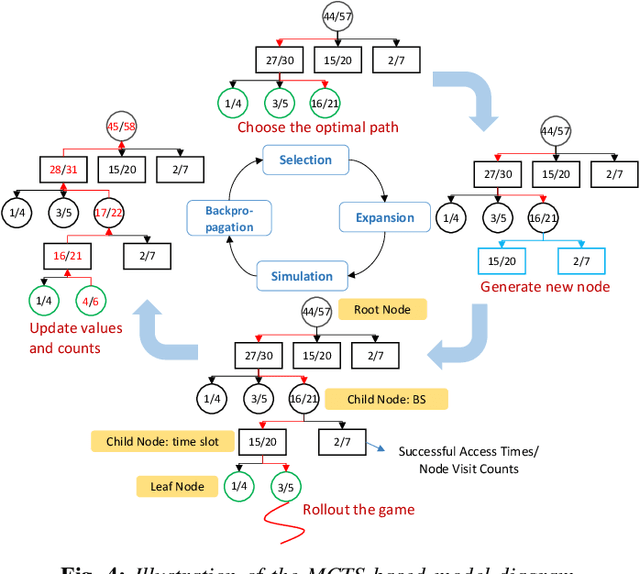
Electric Vertical Take-Off and Landing (eVTOL) aircraft, pivotal to Advanced Air Mobility (AAM), are emerging as a transformative transportation paradigm with the potential to redefine urban and regional mobility. While these systems offer unprecedented efficiency in transporting people and goods, they rely heavily on computation capability, safety-critical operations such as real-time navigation, environmental sensing, and trajectory tracking--necessitating robust offboard computational support. A widely adopted solution involves offloading these tasks to terrestrial base stations (BSs) along the flight path. However, air-to-ground connectivity is often constrained by spectrum conflicts with terrestrial users, which poses a significant challenge to maintaining reliable task execution. Cognitive radio (CR) techniques offer promising capabilities for dynamic spectrum access, making them a natural fit for addressing this issue. Existing studies often overlook the time-varying nature of BS resources, such as spectrum availability and CPU cycles, which leads to inaccurate trajectory planning, suboptimal offloading success rates, excessive energy consumption, and operational delays. To address these challenges, we propose a trajectory optimization framework for eVTOL swarms that maximizes task offloading success probability while minimizing both energy consumption and resource competition (e.g., spectrum and CPU cycles) with primary terrestrial users. The proposed algorithm integrates a Multi-Armed Bandit (MAB) model to dynamically estimate BS resource availability and a Monte Carlo Tree Search (MCTS) algorithm to determine optimal offloading decisions, selecting both the BSs and access time windows that align with energy and temporal constraints.