 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAESTRO: Meta-learning Adaptive Estimation of Scalarization Trade-offs for Reward Optimization
Jan 12, 2026Group-Relative Policy Optimization (GRPO) has emerged as an efficient paradigm for aligning Large Language Models (LLMs), yet its efficacy is primarily confined to domains with verifiable ground truths. Extending GRPO to open-domain settings remains a critical challenge, as unconstrained generation entails multi-faceted and often conflicting objectives - such as creativity versus factuality - where rigid, static reward scalarization is inherently suboptimal. To address this, we propose MAESTRO (Meta-learning Adaptive Estimation of Scalarization Trade-offs for Reward Optimization), which introduces a meta-cognitive orchestration layer that treats reward scalarization as a dynamic latent policy, leveraging the model's terminal hidden states as a semantic bottleneck to perceive task-specific priorities. We formulate this as a contextual bandit problem within a bi-level optimization framework, where a lightweight Conductor network co-evolves with the policy by utilizing group-relative advantages as a meta-reward signal. Across seven benchmarks, MAESTRO consistently outperforms single-reward and static multi-objective baselines, while preserving the efficiency advantages of GRPO, and in some settings even reducing redundant generation.
Consolidation or Adaptation? PRISM: Disentangling SFT and RL Data via Gradient Concentration
Jan 12, 2026While Hybrid Supervised Fine-Tuning (SFT) followed by Reinforcement Learning (RL) has become the standard paradigm for training LLM agents, effective mechanisms for data allocation between these stages remain largely underexplored. Current data arbitration strategies often rely on surface-level heuristics that fail to diagnose intrinsic learning needs. Since SFT targets pattern consolidation through imitation while RL drives structural adaptation via exploration, misaligning data with these functional roles causes severe optimization interference. We propose PRISM, a dynamics-aware framework grounded in Schema Theory that arbitrates data based on its degree of cognitive conflict with the model's existing knowledge. By analyzing the spatial geometric structure of gradients, PRISM identifies data triggering high spatial concentration as high-conflict signals that require RL for structural restructuring. In contrast, data yielding diffuse updates is routed to SFT for efficient consolidation. Extensive experiments on WebShop and ALFWorld demonstrate that PRISM achieves a Pareto improvement, outperforming state-of-the-art hybrid methods while reducing computational costs by up to 3.22$\times$. Our findings suggest that disentangling data based on internal optimization regimes is crucial for scalable and robust agent alignment.
Self-Route: Automatic Mode Switching via Capability Estimation for Efficient Reasoning
May 27, 2025While reasoning-augmented large language models (RLLMs) significantly enhance complex task performance through extended reasoning chains, they inevitably introduce substantial unnecessary token consumption, particularly for simpler problems where Short Chain-of-Thought (Short CoT) suffices. This overthinking phenomenon leads to inefficient resource usage without proportional accuracy gains. To address this issue, we propose Self-Route, a dynamic reasoning framework that automatically selects between general and reasoning modes based on model capability estimation. Our approach introduces a lightweight pre-inference stage to extract capability-aware embeddings from hidden layer representations, enabling real-time evaluation of the model's ability to solve problems. We further construct Gradient-10K, a model difficulty estimation-based dataset with dense complexity sampling, to train the router for precise capability boundary detection. Extensive experiments demonstrate that Self-Route achieves comparable accuracy to reasoning models while reducing token consumption by 30-55\% across diverse benchmarks. The proposed framework demonstrates consistent effectiveness across models with different parameter scales and reasoning paradigms, highlighting its general applicability and practical value.
Benchmarking and Pushing the Multi-Bias Elimination Boundary of LLMs via Causal Effect Estimation-guided Debiasing
May 22, 2025Despite significant progress, recent studies have indicated that current large language models (LLMs) may still utilize bias during inference, leading to the poor generalizability of LLMs. Some benchmarks are proposed to investigate the generalizability of LLMs, with each piece of data typically containing one type of controlled bias. However, a single piece of data may contain multiple types of biases in practical applications. To bridge this gap, we propose a multi-bias benchmark where each piece of data contains five types of biases. The evaluations conducted on this benchmark reveal that the performance of existing LLMs and debiasing methods is unsatisfying, highlighting the challenge of eliminating multiple types of biases simultaneously. To overcome this challenge, we propose a causal effect estimation-guided multi-bias elimination method (CMBE). This method first estimates the causal effect of multiple types of biases simultaneously. Subsequently, we eliminate the causal effect of biases from the total causal effect exerted by both the semantic information and biases during inference. Experimental results show that CMBE can effectively eliminate multiple types of bias simultaneously to enhance the generalizability of LLMs.
UFO-RL: Uncertainty-Focused Optimization for Efficient Reinforcement Learning Data Selection
May 18, 2025Scaling RL for LLMs is computationally expensive, largely due to multi-sampling for policy optimization and evaluation, making efficient data selection crucial. Inspired by the Zone of Proximal Development (ZPD) theory, we hypothesize LLMs learn best from data within their potential comprehension zone. Addressing the limitation of conventional, computationally intensive multi-sampling methods for data assessment, we introduce UFO-RL. This novel framework uses a computationally efficient single-pass uncertainty estimation to identify informative data instances, achieving up to 185x faster data evaluation. UFO-RL leverages this metric to select data within the estimated ZPD for training. Experiments show that training with just 10% of data selected by UFO-RL yields performance comparable to or surpassing full-data training, reducing overall training time by up to 16x while enhancing stability and generalization. UFO-RL offers a practical and highly efficient strategy for scaling RL fine-tuning of LLMs by focusing learning on valuable data.
Information Gain-Guided Causal Intervention for Autonomous Debiasing Large Language Models
Apr 17, 2025Despite significant progress, recent studies indicate that current large language models (LLMs) may still capture dataset biases and utilize them during inference, leading to the poor generalizability of LLMs. However, due to the diversity of dataset biases and the insufficient nature of bias suppression based on in-context learning, the effectiveness of previous prior knowledge-based debiasing methods and in-context learning based automatic debiasing methods is limited. To address these challenges, we explore the combination of causal mechanisms with information theory and propose an information gain-guided causal intervention debiasing (IGCIDB) framework. This framework first utilizes an information gain-guided causal intervention method to automatically and autonomously balance the distribution of instruction-tuning dataset. Subsequently, it employs a standard supervised fine-tuning process to train LLMs on the debiased dataset. Experimental results show that IGCIDB can effectively debias LLM to improve its generalizability across different tasks.
Causal-Guided Active Learning for Debiasing Large Language Models
Aug 23, 2024Although achieving promising performance, recent analyses show that current generative large language models (LLMs) may still capture dataset biases and utilize them for generation, leading to poor generalizability and harmfulness of LLMs. However, due to the diversity of dataset biases and the over-optimization problem, previous prior-knowledge-based debiasing methods and fine-tuning-based debiasing methods may not be suitable for current LLMs. To address this issue, we explore combining active learning with the causal mechanisms and propose a casual-guided active learning (CAL) framework, which utilizes LLMs itself to automatically and autonomously identify informative biased samples and induce the bias patterns. Then a cost-effective and efficient in-context learning based method is employed to prevent LLMs from utilizing dataset biases during generation. Experimental results show that CAL can effectively recognize typical biased instances and induce various bias patterns for debiasing LLMs.
Towards Generalizable and Faithful Logic Reasoning over Natural Language via Resolution Refutation
Apr 03, 2024



Large language models (LLMs) have achieved significant performance in various natural language reasoning tasks. However, they still struggle with performing first-order logic reasoning over formal logical theories expressed in natural language. This is because the previous LLMs-based reasoning systems have the theoretical incompleteness issue. As a result, it can only address a limited set of simple reasoning problems, which significantly decreases their generalization ability. To address this issue, we propose a novel framework, named Generalizable and Faithful Reasoner (GFaiR), which introduces the paradigm of resolution refutation. Resolution refutation has the capability to solve all first-order logic reasoning problems by extending reasoning rules and employing the principle of proof by contradiction, so our system's completeness can be improved by introducing resolution refutation. Experimental results demonstrate that our system outperforms previous works by achieving state-of-the-art performances in complex scenarios while maintaining performances in simple scenarios. Besides, we observe that GFaiR is faithful to its reasoning process.
Deciphering the lmpact of Pretraining Data on Large Language Models through Machine Unlearning
Feb 18, 2024
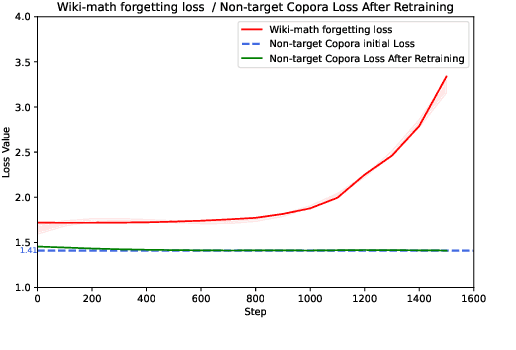

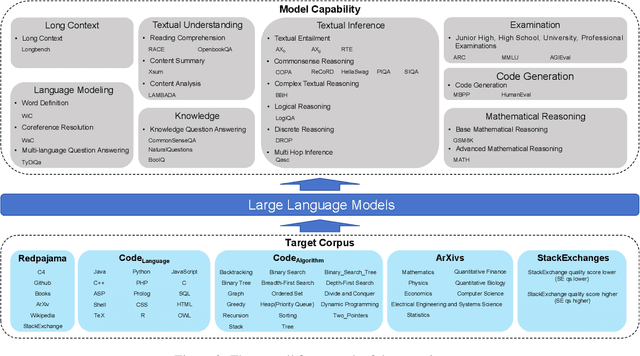
Through pretraining on a corpus with various sources, Large Language Models (LLMs) have gained impressive performance. However, the impact of each component of the pretraining corpus remains opaque. As a result, the organization of the pretraining corpus is still empirical and may deviate from the optimal. To address this issue, we systematically analyze the impact of 48 datasets from 5 major categories of pretraining data of LLMs and measure their impacts on LLMs using benchmarks about nine major categories of model capabilities. Our analyses provide empirical results about the contribution of multiple corpora on the performances of LLMs, along with their joint impact patterns, including complementary, orthogonal, and correlational relationships. We also identify a set of ``high-impact data'' such as Books that is significantly related to a set of model capabilities. These findings provide insights into the organization of data to support more efficient pretraining of LLMs.