 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBalancing Knowledge Updates: Toward Unified Modular Editing in LLMs
Oct 31, 2025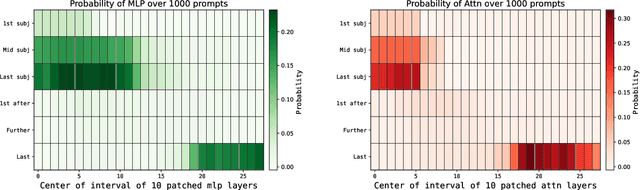
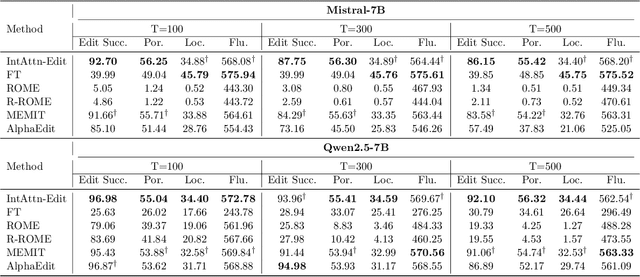
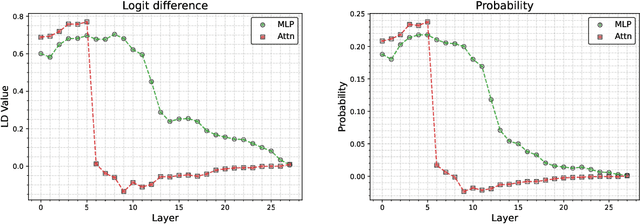
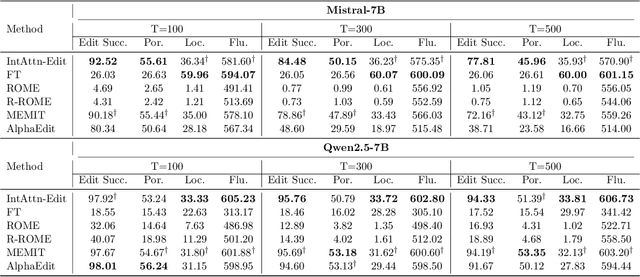
Knowledge editing has emerged as an efficient approach for updating factual knowledge in large language models (LLMs). It typically locates knowledge storage modules and then modifies their parameters. However, most existing methods focus on the weights of multilayer perceptron (MLP) modules, which are often identified as the main repositories of factual information. Other components, such as attention (Attn) modules, are often ignored during editing. This imbalance can leave residual outdated knowledge and limit editing effectiveness. We perform comprehensive knowledge localization experiments on advanced LLMs and find that Attn modules play a substantial role in factual knowledge storage and retrieval, especially in earlier layers. Based on these insights, we propose IntAttn-Edit, a method that extends the associative memory paradigm to jointly update both MLP and Attn modules. Our approach uses a knowledge balancing strategy that allocates update magnitudes in proportion to each module's measured contribution to knowledge storage. Experiments on standard benchmarks show that IntAttn-Edit achieves higher edit success, better generalization, and stronger knowledge preservation than prior methods. Further analysis shows that the balancing strategy keeps editing performance within an optimal range across diverse settings.
UFO-RL: Uncertainty-Focused Optimization for Efficient Reinforcement Learning Data Selection
May 18, 2025Scaling RL for LLMs is computationally expensive, largely due to multi-sampling for policy optimization and evaluation, making efficient data selection crucial. Inspired by the Zone of Proximal Development (ZPD) theory, we hypothesize LLMs learn best from data within their potential comprehension zone. Addressing the limitation of conventional, computationally intensive multi-sampling methods for data assessment, we introduce UFO-RL. This novel framework uses a computationally efficient single-pass uncertainty estimation to identify informative data instances, achieving up to 185x faster data evaluation. UFO-RL leverages this metric to select data within the estimated ZPD for training. Experiments show that training with just 10% of data selected by UFO-RL yields performance comparable to or surpassing full-data training, reducing overall training time by up to 16x while enhancing stability and generalization. UFO-RL offers a practical and highly efficient strategy for scaling RL fine-tuning of LLMs by focusing learning on valuable data.
Pre-trained Transformer-Enabled Strategies with Human-Guided Fine-Tuning for End-to-end Navigation of Autonomous Vehicles
Feb 20, 2024Autonomous driving (AD) technology, leveraging artificial intelligence, strives for vehicle automation. End-toend strategies, emerging to simplify traditional driving systems by integrating perception, decision-making, and control, offer new avenues for advanced driving functionalities. Despite their potential, current challenges include data efficiency, training complexities, and poor generalization. This study addresses these issues with a novel end-to-end AD training model, enhancing system adaptability and intelligence. The model incorporates a Transformer module into the policy network, undergoing initial behavior cloning (BC) pre-training for update gradients. Subsequently, fine-tuning through reinforcement learning with human guidance (RLHG) adapts the model to specific driving environments, aiming to surpass the performance limits of imitation learning (IL). The fine-tuning process involves human interactions, guiding the model to acquire more efficient and safer driving behaviors through supervision, intervention, demonstration, and reward feedback. Simulation results demonstrate that this framework accelerates learning, achieving precise control and significantly enhancing safety and reliability. Compared to other advanced baseline methods, the proposed approach excels in challenging AD tasks. The introduction of the Transformer module and human-guided fine-tuning provides valuable insights and methods for research and applications in the AD field.
A Novel Truncated Norm Regularization Method for Multi-channel Color Image Denoising
Jul 16, 2023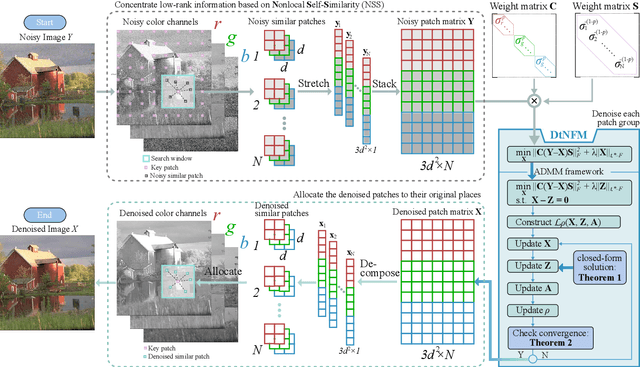
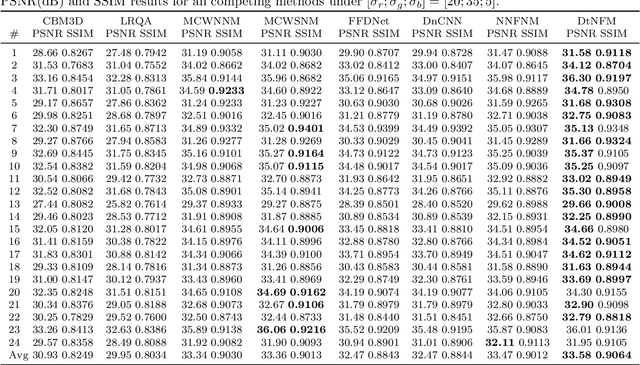
Due to the high flexibility and remarkable performance, low-rank approximation methods has been widely studied for color image denoising. However, those methods mostly ignore either the cross-channel difference or the spatial variation of noise, which limits their capacity in real world color image denoising. To overcome those drawbacks, this paper is proposed to denoise color images with a double-weighted truncated nuclear norm minus truncated Frobenius norm minimization (DtNFM) method. Through exploiting the nonlocal self-similarity of the noisy image, the similar structures are gathered and a series of similar patch matrices are constructed. For each group, the DtNFM model is conducted for estimating its denoised version. The denoised image would be obtained by concatenating all the denoised patch matrices. The proposed DtNFM model has two merits. First, it models and utilizes both the cross-channel difference and the spatial variation of noise. This provides sufficient flexibility for handling the complex distribution of noise in real world images. Second, the proposed DtNFM model provides a close approximation to the underlying clean matrix since it can treat different rank components flexibly. To solve the problem resulted from DtNFM model, an accurate and effective algorithm is proposed by exploiting the framework of the alternating direction method of multipliers (ADMM). The generated subproblems are discussed in detail. And their global optima can be easily obtained in closed-form. Rigorous mathematical derivation proves that the solution sequences generated by the algorithm converge to a single critical point. Extensive experiments on synthetic and real noise datasets demonstrate that the proposed method outperforms many state-of-the-art color image denoising methods.
Multi-channel Nuclear Norm Minus Frobenius Norm Minimization for Color Image Denoising
Sep 16, 2022
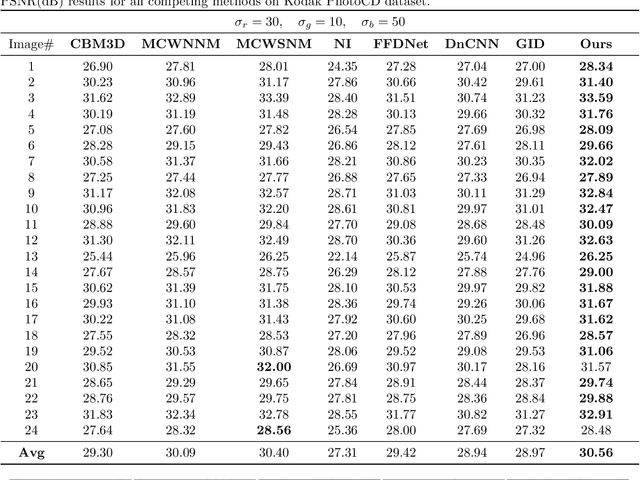
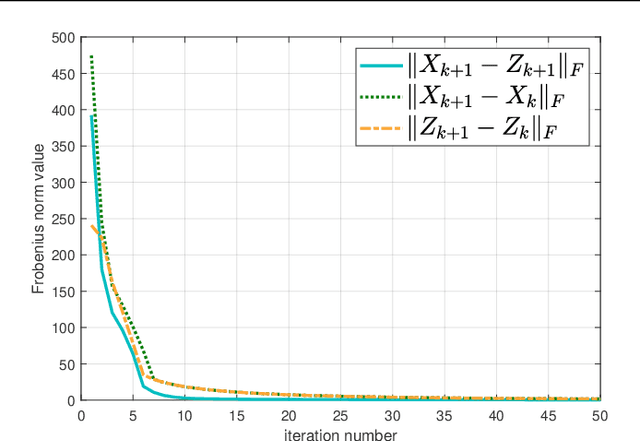
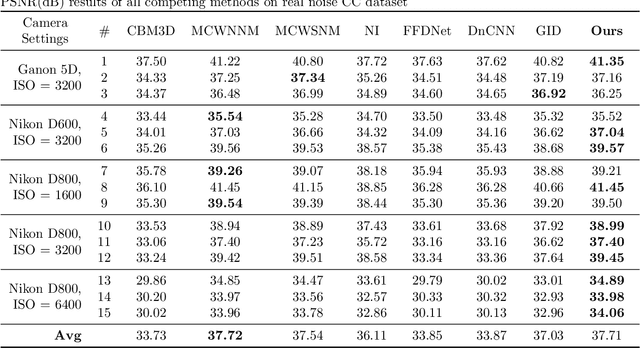
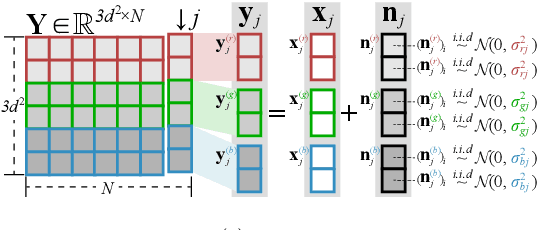
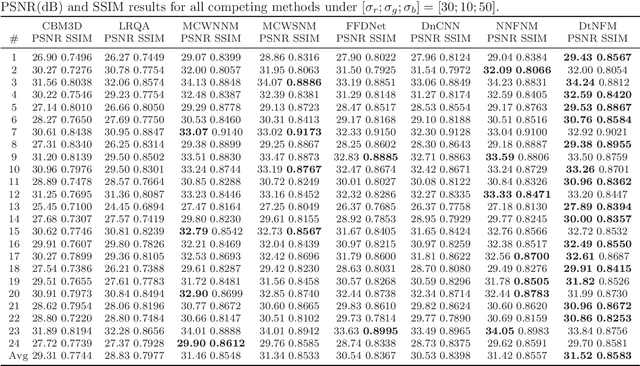
Color image denoising is frequently encountered in various image processing and computer vision tasks. One traditional strategy is to convert the RGB image to a less correlated color space and denoise each channel of the new space separately. However, such a strategy can not fully exploit the correlated information between channels and is inadequate to obtain satisfactory results. To address this issue, this paper proposes a new multi-channel optimization model for color image denoising under the nuclear norm minus Frobenius norm minimization framework. Specifically, based on the block-matching, the color image is decomposed into overlapping RGB patches. For each patch, we stack its similar neighbors to form the corresponding patch matrix. The proposed model is performed on the patch matrix to recover its noise-free version. During the recovery process, a) a weight matrix is introduced to fully utilize the noise difference between channels; b) the singular values are shrunk adaptively without additionally assigning weights. With them, the proposed model can achieve promising results while keeping simplicity. To solve the proposed model, an accurate and effective algorithm is built based on the alternating direction method of multipliers framework. The solution of each updating step can be analytically expressed in closed-from. Rigorous theoretical analysis proves the solution sequences generated by the proposed algorithm converge to their respective stationary points. Experimental results on both synthetic and real noise datasets demonstrate the proposed model outperforms state-of-the-art models.
WSSS4LUAD: Grand Challenge on Weakly-supervised Tissue Semantic Segmentation for Lung Adenocarcinoma
Apr 14, 2022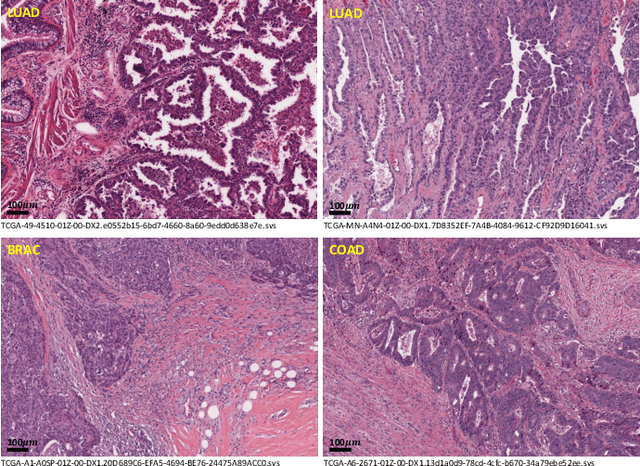
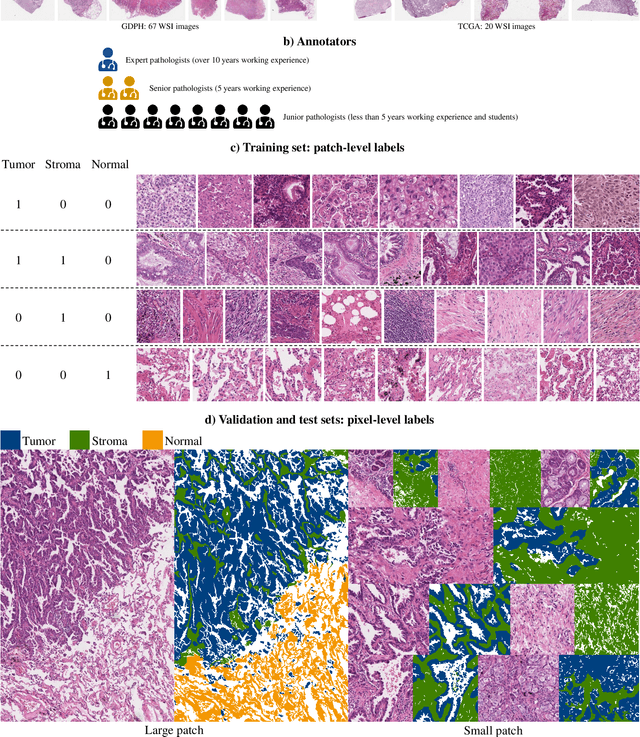
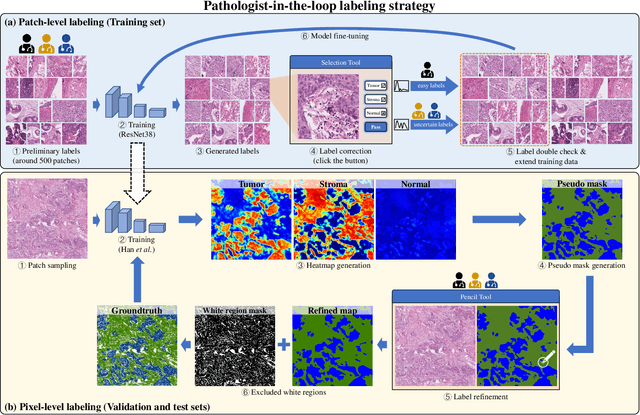
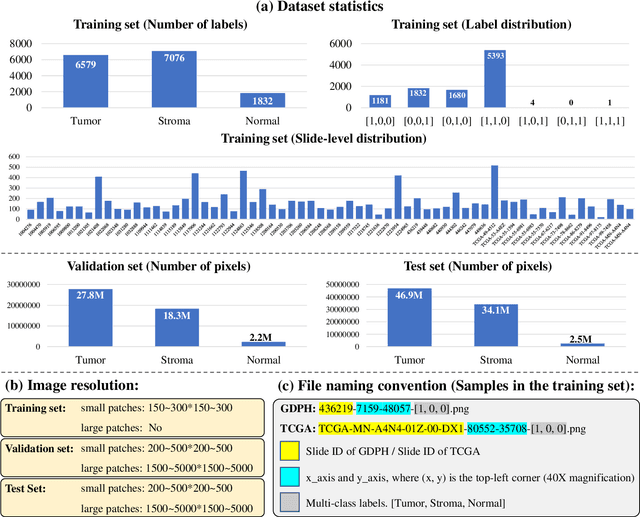
Lung cancer is the leading cause of cancer death worldwide, and adenocarcinoma (LUAD) is the most common subtype. Exploiting the potential value of the histopathology images can promote precision medicine in oncology. Tissue segmentation is the basic upstream task of histopathology image analysis. Existing deep learning models have achieved superior segmentation performance but require sufficient pixel-level annotations, which is time-consuming and expensive. To enrich the label resources of LUAD and to alleviate the annotation efforts, we organize this challenge WSSS4LUAD to call for the outstanding weakly-supervised semantic segmentation (WSSS) techniques for histopathology images of LUAD. Participants have to design the algorithm to segment tumor epithelial, tumor-associated stroma and normal tissue with only patch-level labels. This challenge includes 10,091 patch-level annotations (the training set) and over 130 million labeled pixels (the validation and test sets), from 87 WSIs (67 from GDPH, 20 from TCGA). All the labels were generated by a pathologist-in-the-loop pipeline with the help of AI models and checked by the label review board. Among 532 registrations, 28 teams submitted the results in the test phase with over 1,000 submissions. Finally, the first place team achieved mIoU of 0.8413 (tumor: 0.8389, stroma: 0.7931, normal: 0.8919). According to the technical reports of the top-tier teams, CAM is still the most popular approach in WSSS. Cutmix data augmentation has been widely adopted to generate more reliable samples. With the success of this challenge, we believe that WSSS approaches with patch-level annotations can be a complement to the traditional pixel annotations while reducing the annotation efforts. The entire dataset has been released to encourage more researches on computational pathology in LUAD and more novel WSSS techniques.
Separable-HoverNet and Instance-YOLO for Colon Nuclei Identification and Counting
Mar 01, 2022Nuclear segmentation, classification and quantification within Haematoxylin & Eosin stained histology images enables the extraction of interpretable cell-based features that can be used in downstream explainable models in computational pathology (CPath). However, automatic recognition of different nuclei is faced with a major challenge in that there are several different types of nuclei, some of them exhibiting large intraclass variability. In this work, we propose an approach that combine Separable-HoverNet and Instance-YOLOv5 to indentify colon nuclei small and unbalanced. Our approach can achieve mPQ+ 0.389 on the Segmentation and Classification-Preliminary Test Dataset and r2 0.599 on the Cellular Composition-Preliminary Test Dataset on ISBI 2022 CoNIC Challenge.
NoisyCUR: An algorithm for two-cost budgeted matrix completion
Apr 16, 2021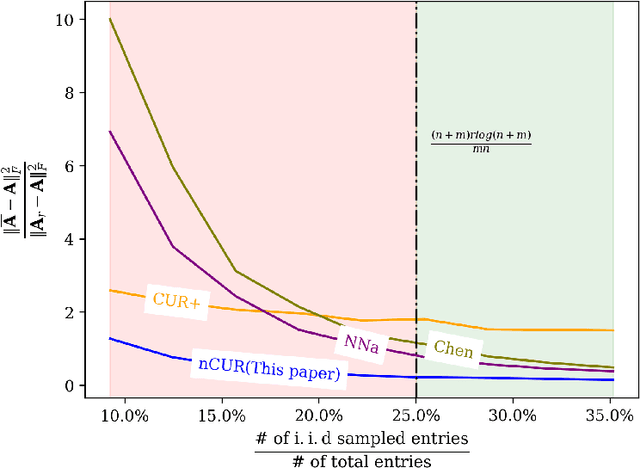
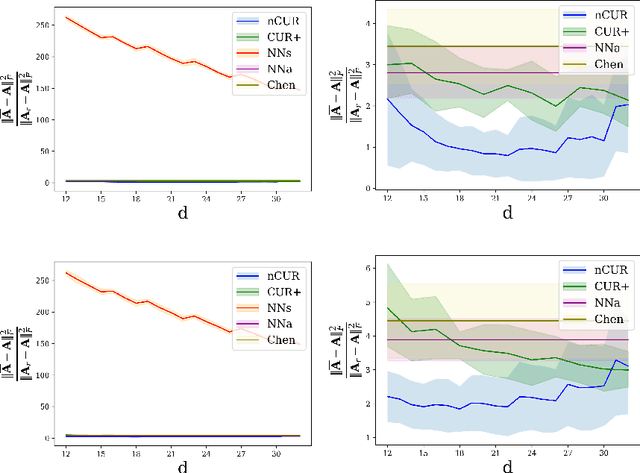
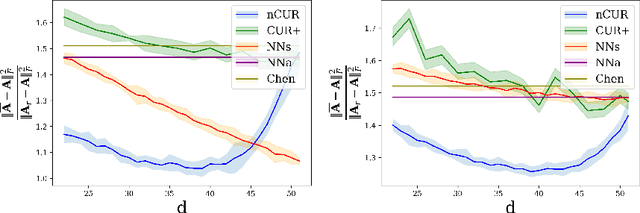
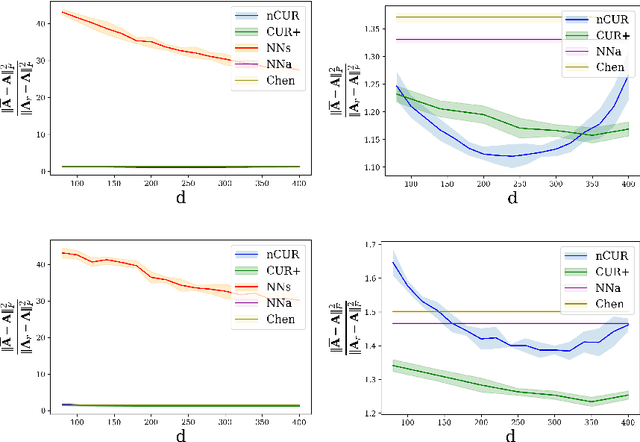
Matrix completion is a ubiquitous tool in machine learning and data analysis. Most work in this area has focused on the number of observations necessary to obtain an accurate low-rank approximation. In practice, however, the cost of observations is an important limiting factor, and experimentalists may have on hand multiple modes of observation with differing noise-vs-cost trade-offs. This paper considers matrix completion subject to such constraints: a budget is imposed and the experimentalist's goal is to allocate this budget between two sampling modalities in order to recover an accurate low-rank approximation. Specifically, we consider that it is possible to obtain low noise, high cost observations of individual entries or high noise, low cost observations of entire columns. We introduce a regression-based completion algorithm for this setting and experimentally verify the performance of our approach on both synthetic and real data sets. When the budget is low, our algorithm outperforms standard completion algorithms. When the budget is high, our algorithm has comparable error to standard nuclear norm completion algorithms and requires much less computational effort.