 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePretraining-finetuning Framework for Efficient Co-design: A Case Study on Quadruped Robot Parkour
Jul 09, 2024
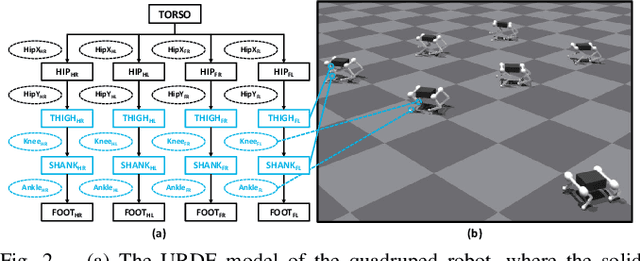

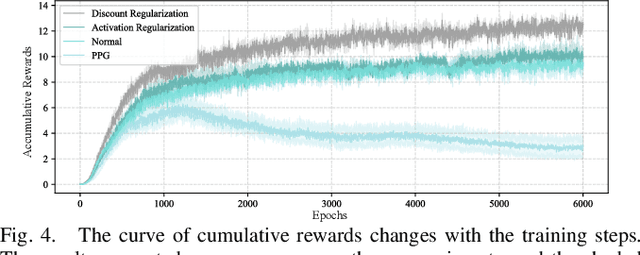
In nature, animals with exceptional locomotion abilities, such as cougars, often possess asymmetric fore and hind legs, with their powerful hind legs acting as reservoirs of energy for leaps. This observation inspired us: could optimize the leg length of quadruped robots endow them with similar locomotive capabilities? In this paper, we propose an approach that co-optimizes the mechanical structure and control policy to boost the locomotive prowess of quadruped robots. Specifically, we introduce a novel pretraining-finetuning framework, which not only guarantees optimal control strategies for each mechanical candidate but also ensures time efficiency. Additionally, we have devised an innovative training method for our pretraining network, integrating spatial domain randomization with regularization methods, markedly improving the network's generalizability. Our experimental results indicate that the proposed pretraining-finetuning framework significantly enhances the overall co-design performance with less time consumption. Moreover, the co-design strategy substantially exceeds the conventional method of independently optimizing control strategies, further improving the robot's locomotive performance and providing an innovative approach to enhancing the extreme parkour capabilities of quadruped robots.
Pre-trained Transformer-Enabled Strategies with Human-Guided Fine-Tuning for End-to-end Navigation of Autonomous Vehicles
Feb 20, 2024Autonomous driving (AD) technology, leveraging artificial intelligence, strives for vehicle automation. End-toend strategies, emerging to simplify traditional driving systems by integrating perception, decision-making, and control, offer new avenues for advanced driving functionalities. Despite their potential, current challenges include data efficiency, training complexities, and poor generalization. This study addresses these issues with a novel end-to-end AD training model, enhancing system adaptability and intelligence. The model incorporates a Transformer module into the policy network, undergoing initial behavior cloning (BC) pre-training for update gradients. Subsequently, fine-tuning through reinforcement learning with human guidance (RLHG) adapts the model to specific driving environments, aiming to surpass the performance limits of imitation learning (IL). The fine-tuning process involves human interactions, guiding the model to acquire more efficient and safer driving behaviors through supervision, intervention, demonstration, and reward feedback. Simulation results demonstrate that this framework accelerates learning, achieving precise control and significantly enhancing safety and reliability. Compared to other advanced baseline methods, the proposed approach excels in challenging AD tasks. The introduction of the Transformer module and human-guided fine-tuning provides valuable insights and methods for research and applications in the AD field.
Integrated Drill Boom Hole-Seeking Control via Reinforcement Learning
Dec 04, 2023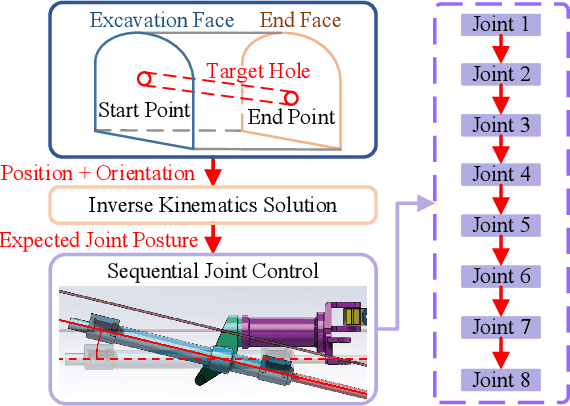
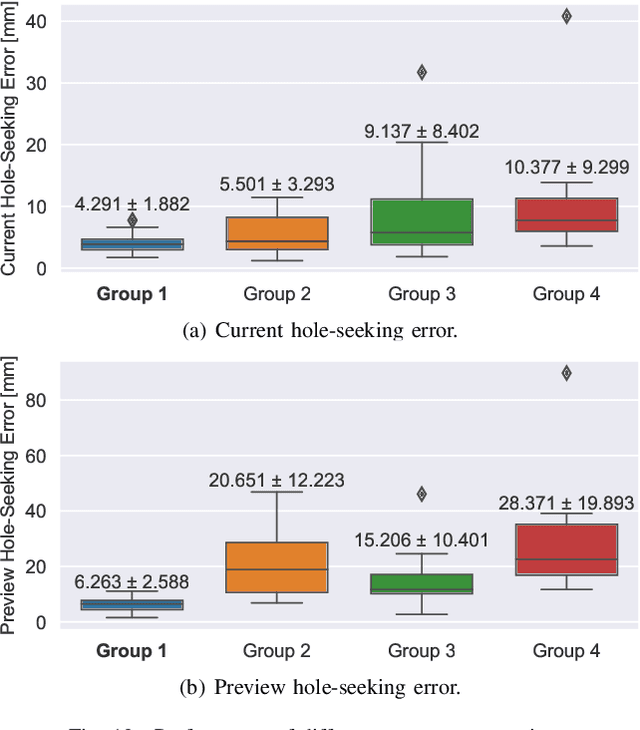
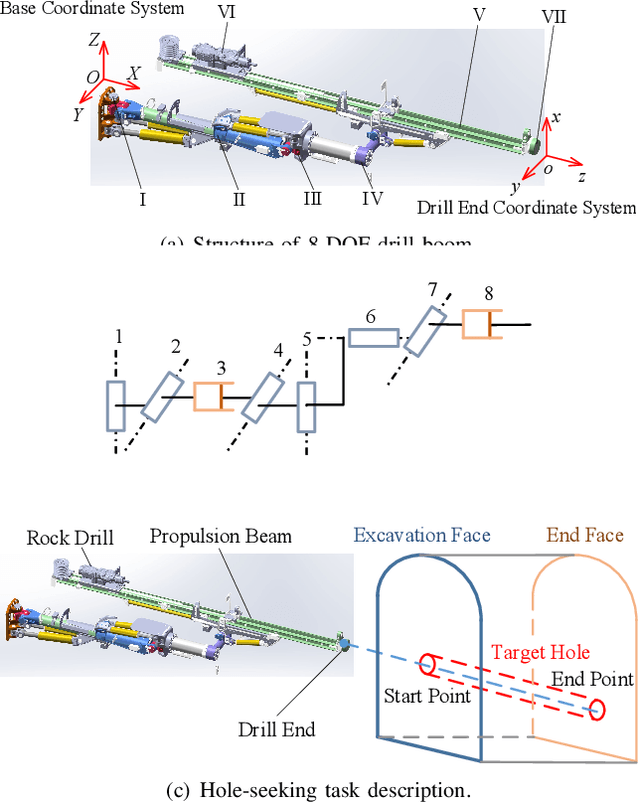
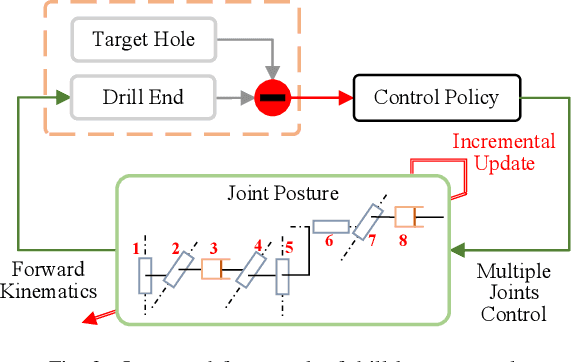
Intelligent drill boom hole-seeking is a promising technology for enhancing drilling efficiency, mitigating potential safety hazards, and relieving human operators. Most existing intelligent drill boom control methods rely on a hierarchical control framework based on inverse kinematics. However, these methods are generally time-consuming due to the computational complexity of inverse kinematics and the inefficiency of the sequential execution of multiple joints. To tackle these challenges, this study proposes an integrated drill boom control method based on Reinforcement Learning (RL). We develop an integrated drill boom control framework that utilizes a parameterized policy to directly generate control inputs for all joints at each time step, taking advantage of joint posture and target hole information. By formulating the hole-seeking task as a Markov decision process, contemporary mainstream RL algorithms can be directly employed to learn a hole-seeking policy, thus eliminating the need for inverse kinematics solutions and promoting cooperative multi-joint control. To enhance the drilling accuracy throughout the entire drilling process, we devise a state representation that combines Denavit-Hartenberg joint information and preview hole-seeking discrepancy data. Simulation results show that the proposed method significantly outperforms traditional methods in terms of hole-seeking accuracy and time efficiency.
Optimal Probabilistic Motion Planning with Partially Infeasible LTL Constraints
Jul 28, 2020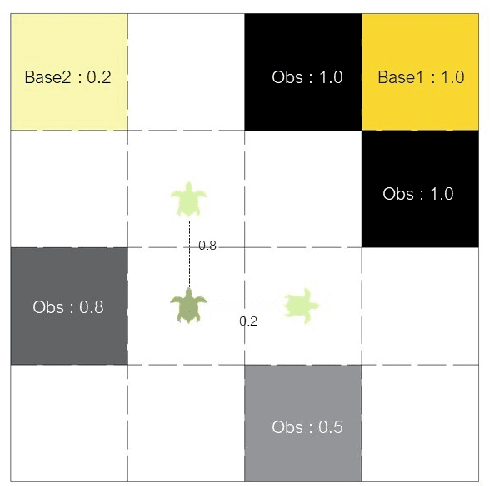
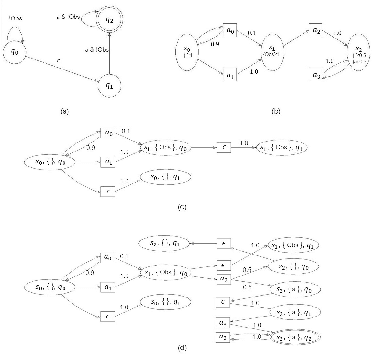
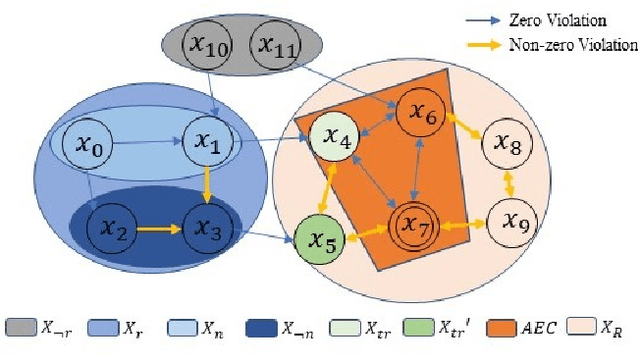
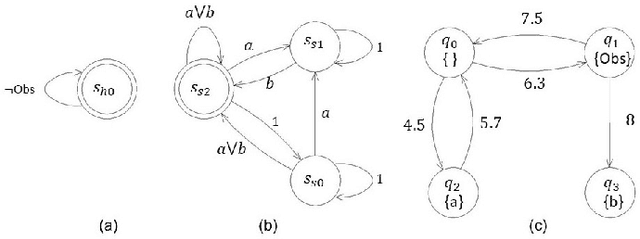
This paper studies optimal probabilistic motion planning of a mobile agent in an uncertain environment where pre-specified tasks might not be fully realized. The agent's motion is modeled by a probabilistic labeled Markov decision process (MDP). A relaxed product MDP is developed, which allows the agent to revise its motion plan to not strictly follow the desired LTL constraints whenever the task is found to be infeasible. To evaluate the revised motion plan, a utility function composed of violation and implementation cost is developed, where the violation cost function is designed to quantify the differences between the revised and the desired motion plan, and the implementation cost are designed to bias the selection towards cost-efficient plans. Based on the developed utility function, a multi-objective optimization problem is formulated to jointly consider the implementation cost, the violation cost, and the satisfaction probability of tasks. Cost optimization in both prefix and suffix of the agent trajectory is then solved via coupled linear programs. Simulation results are provided to demonstrate its effectiveness.
Receding Horizon Control Based Online Motion Planning with Partially Infeasible LTL Specifications
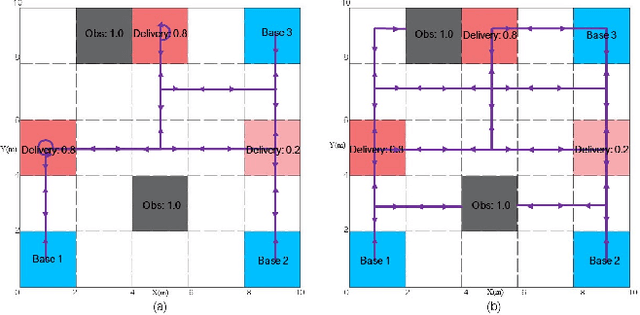
Jul 23, 2020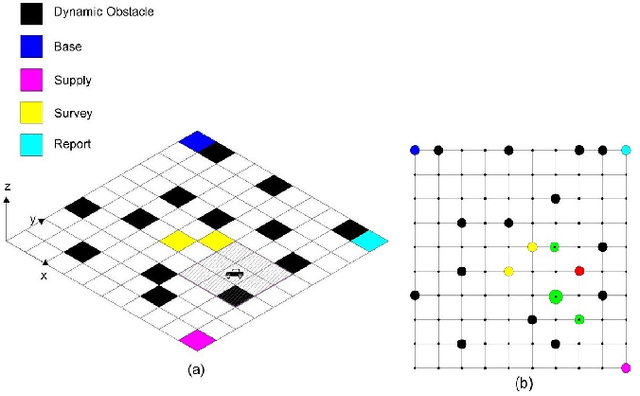
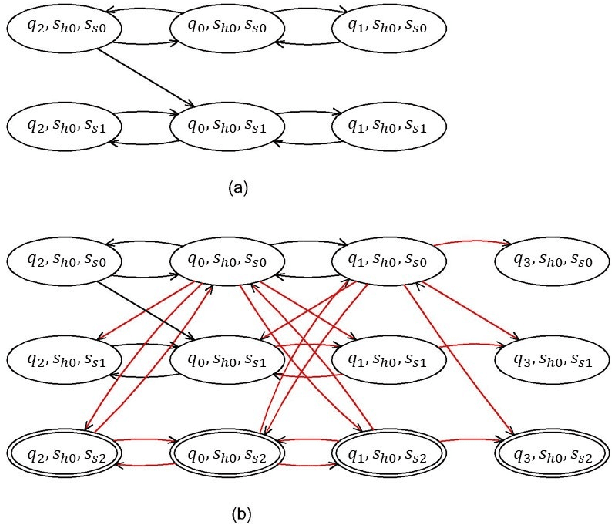
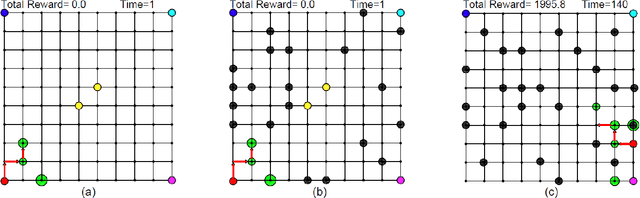
This work considers online optimal motion planning of an autonomous agent subject to linear temporal logic (LTL) constraints. The environment is dynamic in the sense of containing mobile obstacles and time-varying areas of interest (i.e., time-varying reward and workspace properties) to be visited by the agent. Since user-specified tasks may not be fully realized (i.e., partially infeasible), this work considers hard and soft LTL constraints, where hard constraints enforce safety requirement (e.g. avoid obstacles) while soft constraints represent tasks that can be relaxed to not strictly follow user specifications. The motion planning of the agent is to generate policies, in decreasing order of priority, to 1) formally guarantee the satisfaction of safety constraints; 2) mostly satisfy soft constraints (i.e., minimize the violation cost if desired tasks are partially infeasible); and 3) optimize the objective of rewards collection (i.e., visiting dynamic areas of more interests). To achieve these objectives, a relaxed product automaton, which allows the agent to not strictly follow the desired LTL constraints, is constructed. A utility function is developed to quantify the differences between the revised and the desired motion plan, and the accumulated rewards are designed to bias the motion plan towards those areas of more interests. Receding horizon control is synthesized with an LTL formula to maximize the accumulated utilities over a finite horizon, while ensuring that safety constraints are fully satisfied and soft constraints are mostly satisfied. Simulation and experiment results are provided to demonstrate the effectiveness of the developed motion strategy.