 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiable SpaTiaL: Symbolic Learning and Reasoning with Geometric Temporal Logic for Manipulation Tasks
Apr 03, 2026Executing complex manipulation in cluttered environments requires satisfying coupled geometric and temporal constraints. Although Spatio-Temporal Logic (SpaTiaL) offers a principled specification framework, its use in gradient-based optimization is limited by non-differentiable geometric operations. Existing differentiable temporal logics focus on the robot's internal state and neglect interactive object-environment relations, while spatial logic approaches that capture such interactions rely on discrete geometry engines that break the computational graph and preclude exact gradient propagation. To overcome this limitation, we propose Differentiable SpaTiaL, a fully tensorized toolbox that constructs smooth, autograd-compatible geometric primitives directly over polygonal sets. To the best of our knowledge, this is the first end-to-end differentiable symbolic spatio-temporal logic toolbox. By analytically deriving differentiable relaxations of key spatial predicates--including signed distance, intersection, containment, and directional relations--we enable an end-to-end differentiable mapping from high-level semantic specifications to low-level geometric configurations, without invoking external discrete solvers. This fully differentiable formulation unlocks two core capabilities: (i) massively parallel trajectory optimization under rigorous spatio-temporal constraints, and (ii) direct learning of spatial logic parameters from demonstrations via backpropagation. Experimental results validate the effectiveness and scalability of the proposed framework.Code Available: https://github.com/plen1lune/DiffSpaTiaL
Conformalized Signal Temporal Logic Inference under Covariate Shift
Mar 28, 2026Signal Temporal Logic (STL) inference learns interpretable logical rules for temporal behaviors in dynamical systems. To ensure the correctness of learned STL formulas, recent approaches have incorporated conformal prediction as a statistical tool for uncertainty quantification. However, most existing methods rely on the assumption that calibration and testing data are identically distributed and exchangeable, an assumption that is frequently violated in real-world settings. This paper proposes a conformalized STL inference framework that explicitly addresses covariate shift between training and deployment trajectories dataset. From a technical standpoint, the approach first employs a template-free, differentiable STL inference method to learn an initial model, and subsequently refines it using a limited deployment side dataset to promote distribution alignment. To provide validity guarantees under distribution shift, the framework estimates the likelihood ratio between training and deployment distributions and integrates it into an STL-robustness-based weighted conformal prediction scheme. Experimental results on trajectory datasets demonstrate that the proposed framework preserves the interpretability of STL formulas while significantly improving symbolic learning reliability at deployment time.
NL2SpaTiaL: Generating Geometric Spatio-Temporal Logic Specifications from Natural Language for Manipulation Tasks
Dec 15, 2025Spatio-Temporal Logic (SpaTiaL) offers a principled formalism for expressing geometric spatial requirements-an essential component of robotic manipulation, where object locations, neighborhood relations, pose constraints, and interactions directly determine task success. Yet prior works have largely relied on standard temporal logic (TL), which models only robot trajectories and overlooks object-level interactions. Existing datasets built from randomly generated TL formulas paired with natural-language descriptions therefore cover temporal operators but fail to represent the layered spatial relations that manipulation tasks depend on. To address this gap, we introduce a dataset generation framework that synthesizes SpaTiaL specifications and converts them into natural-language descriptions through a deterministic, semantics-preserving back-translation procedure. This pipeline produces the NL2SpaTiaL dataset, aligning natural language with multi-level spatial relations and temporal objectives to reflect the compositional structure of manipulation tasks. Building on this foundation, we propose a translation-verification framework equipped with a language-based semantic checker that ensures the generated SpaTiaL formulas faithfully encode the semantics specified by the input description. Experiments across a suite of manipulation tasks show that SpaTiaL-based representations yield more interpretable, verifiable, and compositional grounding for instruction following. Project website: https://sites.google.com/view/nl2spatial
Bridging Deep Reinforcement Learning and Motion Planning for Model-Free Navigation in Cluttered Environments
Apr 09, 2025



Deep Reinforcement Learning (DRL) has emerged as a powerful model-free paradigm for learning optimal policies. However, in real-world navigation tasks, DRL methods often suffer from insufficient exploration, particularly in cluttered environments with sparse rewards or complex dynamics under system disturbances. To address this challenge, we bridge general graph-based motion planning with DRL, enabling agents to explore cluttered spaces more effectively and achieve desired navigation performance. Specifically, we design a dense reward function grounded in a graph structure that spans the entire state space. This graph provides rich guidance, steering the agent toward optimal strategies. We validate our approach in challenging environments, demonstrating substantial improvements in exploration efficiency and task success rates. The project website is available at: https://plen1lune.github.io/overcome_exploration/
TLINet: Differentiable Neural Network Temporal Logic Inference
May 14, 2024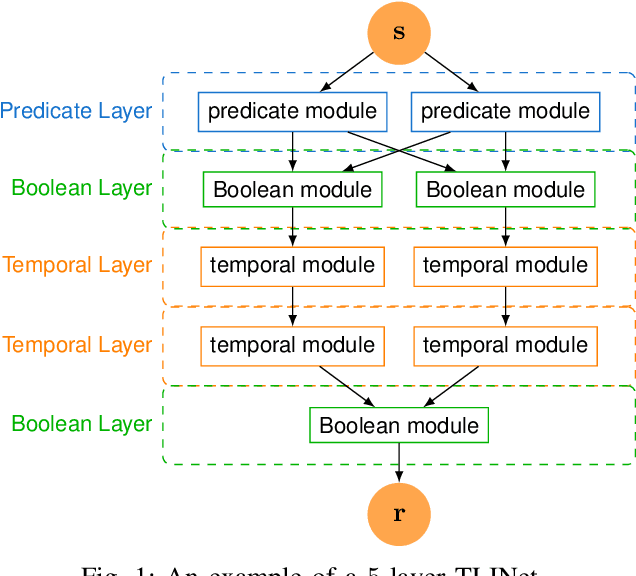
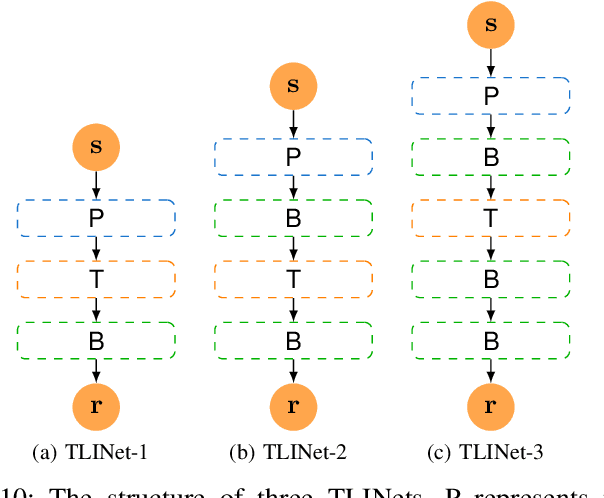
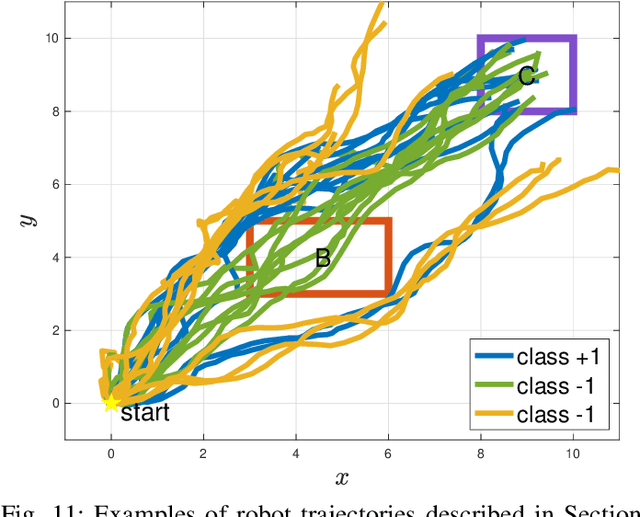
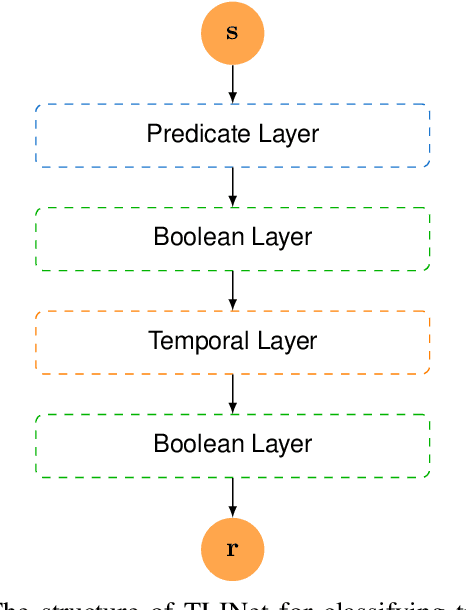
There has been a growing interest in extracting formal descriptions of the system behaviors from data. Signal Temporal Logic (STL) is an expressive formal language used to describe spatial-temporal properties with interpretability. This paper introduces TLINet, a neural-symbolic framework for learning STL formulas. The computation in TLINet is differentiable, enabling the usage of off-the-shelf gradient-based tools during the learning process. In contrast to existing approaches, we introduce approximation methods for max operator designed specifically for temporal logic-based gradient techniques, ensuring the correctness of STL satisfaction evaluation. Our framework not only learns the structure but also the parameters of STL formulas, allowing flexible combinations of operators and various logical structures. We validate TLINet against state-of-the-art baselines, demonstrating that our approach outperforms these baselines in terms of interpretability, compactness, rich expressibility, and computational efficiency.
Hierarchical Deep Learning for Intention Estimation of Teleoperation Manipulation in Assembly Tasks
Mar 28, 2024



In human-robot collaboration, shared control presents an opportunity to teleoperate robotic manipulation to improve the efficiency of manufacturing and assembly processes. Robots are expected to assist in executing the user's intentions. To this end, robust and prompt intention estimation is needed, relying on behavioral observations. The framework presents an intention estimation technique at hierarchical levels i.e., low-level actions and high-level tasks, by incorporating multi-scale hierarchical information in neural networks. Technically, we employ hierarchical dependency loss to boost overall accuracy. Furthermore, we propose a multi-window method that assigns proper hierarchical prediction windows of input data. An analysis of the predictive power with various inputs demonstrates the predominance of the deep hierarchical model in the sense of prediction accuracy and early intention identification. We implement the algorithm on a virtual reality (VR) setup to teleoperate robotic hands in a simulation with various assembly tasks to show the effectiveness of online estimation.
Model-free Motion Planning of Autonomous Agents for Complex Tasks in Partially Observable Environments
Apr 30, 2023Motion planning of autonomous agents in partially known environments with incomplete information is a challenging problem, particularly for complex tasks. This paper proposes a model-free reinforcement learning approach to address this problem. We formulate motion planning as a probabilistic-labeled partially observable Markov decision process (PL-POMDP) problem and use linear temporal logic (LTL) to express the complex task. The LTL formula is then converted to a limit-deterministic generalized B\"uchi automaton (LDGBA). The problem is redefined as finding an optimal policy on the product of PL-POMDP with LDGBA based on model-checking techniques to satisfy the complex task. We implement deep Q learning with long short-term memory (LSTM) to process the observation history and task recognition. Our contributions include the proposed method, the utilization of LTL and LDGBA, and the LSTM-enhanced deep Q learning. We demonstrate the applicability of the proposed method by conducting simulations in various environments, including grid worlds, a virtual office, and a multi-agent warehouse. The simulation results demonstrate that our proposed method effectively addresses environment, action, and observation uncertainties. This indicates its potential for real-world applications, including the control of unmanned aerial vehicles (UAVs).
Efficient LQR-CBF-RRT*: Safe and Optimal Motion Planning
Apr 04, 2023



Control Barrier Functions (CBF) are a powerful tool for designing safety-critical controllers and motion planners. The safety requirements are encoded as a continuously differentiable function that maps from state variables to a real value, in which the sign of its output determines whether safety is violated. In practice, the CBFs can be used to enforce safety by imposing itself as a constraint in a Quadratic Program (QP) solved point-wise in time. However, this approach costs computational resources and could lead to infeasibility in solving the QP. In this paper, we propose a novel motion planning framework that combines sampling-based methods with Linear Quadratic Regulator (LQR) and CBFs. Our approach does not require solving the QPs for control synthesis and avoids explicit collision checking during samplings. Instead, it uses LQR to generate optimal controls and CBF to reject unsafe trajectories. To improve sampling efficiency, we employ the Cross-Entropy Method (CEM) for importance sampling (IS) to sample configurations that will enhance the path with higher probability and store computed optimal gain matrices in a hash table to avoid re-computation during rewiring procedure. We demonstrate the effectiveness of our method on nonlinear control affine systems in simulation.
Learning Minimally-Violating Continuous Control for Infeasible Linear Temporal Logic Specifications
Oct 06, 2022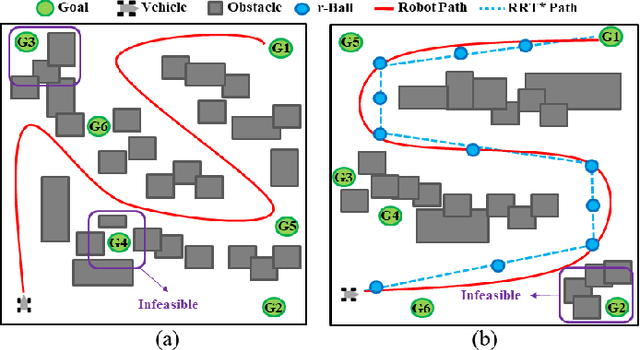
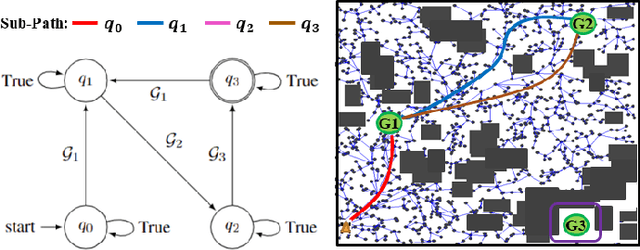
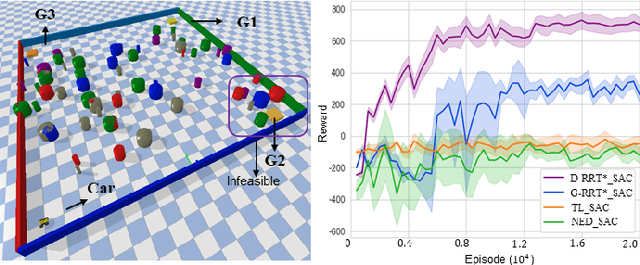
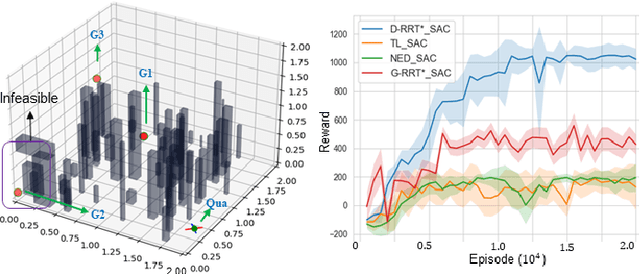
This paper explores continuous-time control synthesis for target-driven navigation to satisfy complex high-level tasks expressed as linear temporal logic (LTL). We propose a model-free framework using deep reinforcement learning (DRL) where the underlying dynamic system is unknown (an opaque box). Unlike prior work, this paper considers scenarios where the given LTL specification might be infeasible and therefore cannot be accomplished globally. Instead of modifying the given LTL formula, we provide a general DRL-based approach to satisfy it with minimal violation. %\mminline{Need to decide if we're comfortable calling these "guarantees" due to the stochastic policy. I'm not repeating this comment everywhere that says "guarantees" but there are multiple places.} To do this, we transform a previously multi-objective DRL problem, which requires simultaneous automata satisfaction and minimum violation cost, into a single objective. By guiding the DRL agent with a sampling-based path planning algorithm for the potentially infeasible LTL task, the proposed approach mitigates the myopic tendencies of DRL, which are often an issue when learning general LTL tasks that can have long or infinite horizons. This is achieved by decomposing an infeasible LTL formula into several reach-avoid sub-tasks with shorter horizons, which can be trained in a modular DRL architecture. Furthermore, we overcome the challenge of the exploration process for DRL in complex and cluttered environments by using path planners to design rewards that are dense in the configuration space. The benefits of the presented approach are demonstrated through testing on various complex nonlinear systems and compared with state-of-the-art baselines. The Video demonstration can be found on YouTube Channel:\url{https://youtu.be/jBhx6Nv224E}.
Learning Signal Temporal Logic through Neural Network for Interpretable Classification
Oct 04, 2022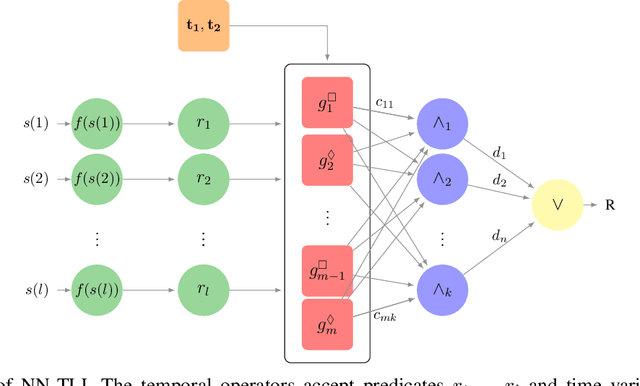
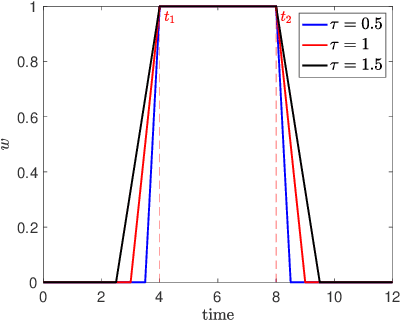
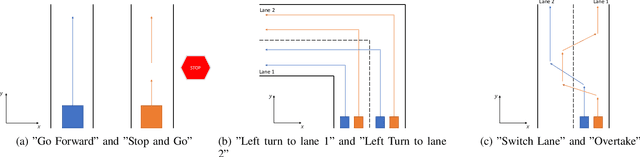
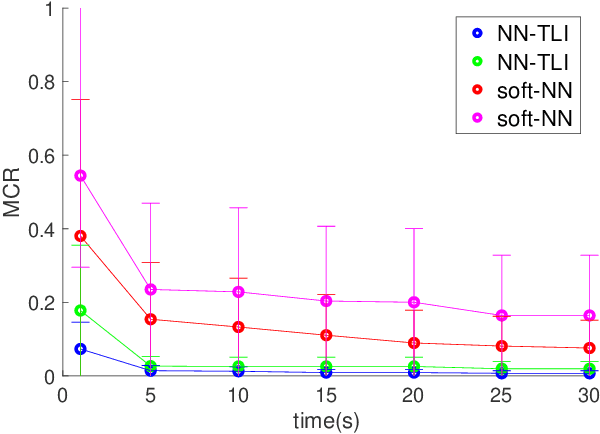
Machine learning techniques using neural networks have achieved promising success for time-series data classification. However, the models that they produce are challenging to verify and interpret. In this paper, we propose an explainable neural-symbolic framework for the classification of time-series behaviors. In particular, we use an expressive formal language, namely Signal Temporal Logic (STL), to constrain the search of the computation graph for a neural network. We design a novel time function and sparse softmax function to improve the soundness and precision of the neural-STL framework. As a result, we can efficiently learn a compact STL formula for the classification of time-series data through off-the-shelf gradient-based tools. We demonstrate the computational efficiency, compactness, and interpretability of the proposed method through driving scenarios and naval surveillance case studies, compared with state-of-the-art baselines.