 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePLUME: Probabilistic Latent Unified World Modeling and Parameter Estimation for Multi-Finger Manipulation
Jun 09, 2026Dexterous manipulation with multi-finger hands can be sensitive to physical parameters such as object shape, pose, and friction coefficients. While simulation enables large-scale data collection with known parameter values, simulation-trained policies must still handle uncertainty at deployment, where the true parameters and therefore the true dynamics are unknown. Standard domain randomization strategies may be insufficient for precise tasks like screwdriver turning, as manipulation strategies may need to change depending on specific parameter values. To address this, we propose Probabilistic Latent Unified world Modeling and parameter Estimation (PLUME), a world model that jointly learns to evolve a belief over parameter values as well as the system dynamics conditioned on those parameters. We learn a latent space to jointly represent multiple qualitatively different physical parameters along with rewards, themselves functions of partially-observable variables, to inform planning. Our novel learning framework leads to efficient alignment of the world model to true dynamics through online parameter inference as opposed to re-training or fine-tuning. We evaluate our method on simulated screwdriver turning, valve turning, bucket lifting, and disk flicking tasks, as well as a hardware screwdriver turning task, where we achieve successful zero-shot transfer of our simulation-trained policy and outperform state-of-the-art offline reinforcement learning and world-model-augmented behavior cloning baselines. Please see our website at https://plume-world-model.github.io for videos.
Geometrically Plausible Object Pose Refinement using Differentiable Simulation
Mar 22, 2026State-of-the-art object pose estimation methods are prone to generating geometrically infeasible pose hypotheses. This problem is prevalent in dexterous manipulation, where estimated poses often intersect with the robotic hand or are not lying on a support surface. We propose a multi-modal pose refinement approach that combines differentiable physics simulation, differentiable rendering and visuo-tactile sensing to optimize object poses for both spatial accuracy and physical consistency. Simulated experiments show that our approach reduces the intersection volume error between the object and robotic hand by 73\% when the initial estimate is accurate and by over 87\% under high initial uncertainty, significantly outperforming standard ICP-based baselines. Furthermore, the improvement in geometric plausibility is accompanied by a concurrent reduction in translation and orientation errors. Achieving pose estimation that is grounded in physical reality while remaining faithful to multi-modal sensor inputs is a critical step toward robust in-hand manipulation.
SUBTA: A Framework for Supported User-Guided Bimanual Teleoperation in Structured Assembly
Mar 11, 2026In human-robot collaboration, shared autonomy enhances human performance through precise, intuitive support. Effective robotic assistance requires accurately inferring human intentions and understanding task structures to determine optimal support timing and methods. In this paper, we present SUBTA, a supported teleoperation system for bimanual assembly that couples learned intention estimation, scene-graph task planning, and context-dependent motion assists. We validate our approach through a user study (N=12) comparing standard teleoperation, motion-support only, and SUBTA. Linear mixed-effects analysis revealed that SUBTA significantly outperformed standard teleoperation in position accuracy (p<0.001, d=1.18) and orientation accuracy (p<0.001, d=1.75), while reducing mental demand (p=0.002, d=1.34). Post-experiment ratings indicate clearer, more trustworthy visual feedback and predictable interventions in SUBTA. The results demonstrate that SUBTA greatly improves both effectiveness and user experience in teleoperation.
VisuoTactile 6D Pose Estimation of an In-Hand Object using Vision and Tactile Sensor Data
Jan 04, 2026Knowledge of the 6D pose of an object can benefit in-hand object manipulation. In-hand 6D object pose estimation is challenging because of heavy occlusion produced by the robot's grippers, which can have an adverse effect on methods that rely on vision data only. Many robots are equipped with tactile sensors at their fingertips that could be used to complement vision data. In this paper, we present a method that uses both tactile and vision data to estimate the pose of an object grasped in a robot's hand. To address challenges like lack of standard representation for tactile data and sensor fusion, we propose the use of point clouds to represent object surfaces in contact with the tactile sensor and present a network architecture based on pixel-wise dense fusion. We also extend NVIDIA's Deep Learning Dataset Synthesizer to produce synthetic photo-realistic vision data and corresponding tactile point clouds. Results suggest that using tactile data in addition to vision data improves the 6D pose estimate, and our network generalizes successfully from synthetic training to real physical robots.
* Accepted for publication in IEEE Robotics and Automation Letters (RA-L), January 2022. Presented at ICRA 2022. This is the author's version of the manuscript
Diffusing Trajectory Optimization Problems for Recovery During Multi-Finger Manipulation
Oct 08, 2025Multi-fingered hands are emerging as powerful platforms for performing fine manipulation tasks, including tool use. However, environmental perturbations or execution errors can impede task performance, motivating the use of recovery behaviors that enable normal task execution to resume. In this work, we take advantage of recent advances in diffusion models to construct a framework that autonomously identifies when recovery is necessary and optimizes contact-rich trajectories to recover. We use a diffusion model trained on the task to estimate when states are not conducive to task execution, framed as an out-of-distribution detection problem. We then use diffusion sampling to project these states in-distribution and use trajectory optimization to plan contact-rich recovery trajectories. We also propose a novel diffusion-based approach that distills this process to efficiently diffuse the full parameterization, including constraints, goal state, and initialization, of the recovery trajectory optimization problem, saving time during online execution. We compare our method to a reinforcement learning baseline and other methods that do not explicitly plan contact interactions, including on a hardware screwdriver-turning task where we show that recovering using our method improves task performance by 96% and that ours is the only method evaluated that can attempt recovery without causing catastrophic task failure. Videos can be found at https://dtourrecovery.github.io/.
GeoDEx: A Unified Geometric Framework for Tactile Dexterous and Extrinsic Manipulation under Force Uncertainty
May 01, 2025Sense of touch that allows robots to detect contact and measure interaction forces enables them to perform challenging tasks such as grasping fragile objects or using tools. Tactile sensors in theory can equip the robots with such capabilities. However, accuracy of the measured forces is not on a par with those of the force sensors due to the potential calibration challenges and noise. This has limited the values these sensors can offer in manipulation applications that require force control. In this paper, we introduce GeoDEx, a unified estimation, planning, and control framework using geometric primitives such as plane, cone and ellipsoid, which enables dexterous as well as extrinsic manipulation in the presence of uncertain force readings. Through various experimental results, we show that while relying on direct inaccurate and noisy force readings from tactile sensors results in unstable or failed manipulation, our method enables successful grasping and extrinsic manipulation of different objects. Additionally, compared to directly running optimization using SOCP (Second Order Cone Programming), planning and force estimation using our framework achieves a 14x speed-up.
Diffusion-Informed Probabilistic Contact Search for Multi-Finger Manipulation
Oct 01, 2024
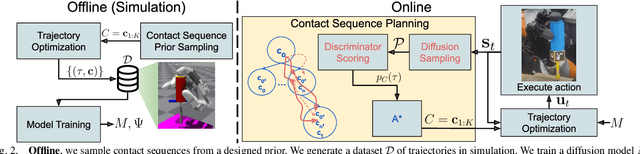
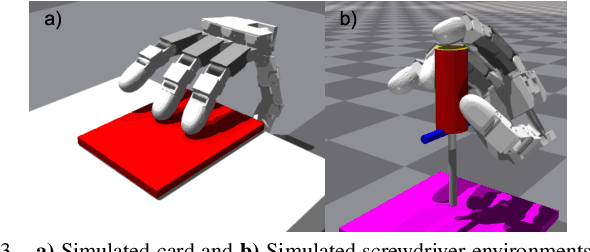
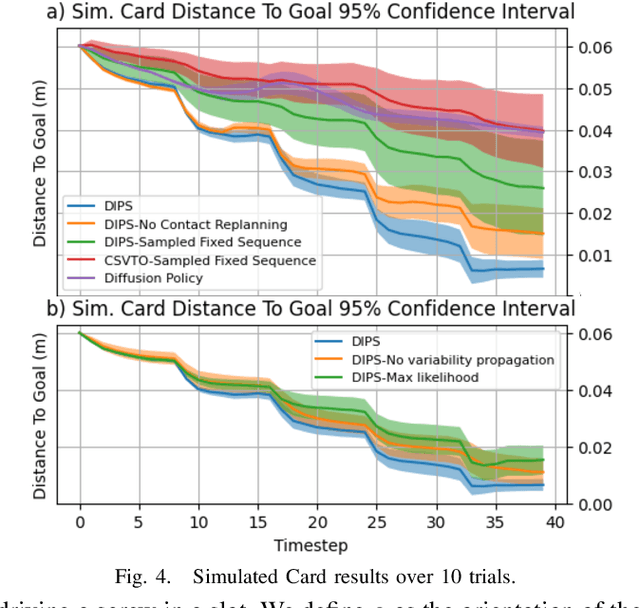
Planning contact-rich interactions for multi-finger manipulation is challenging due to the high-dimensionality and hybrid nature of dynamics. Recent advances in data-driven methods have shown promise, but are sensitive to the quality of training data. Combining learning with classical methods like trajectory optimization and search adds additional structure to the problem and domain knowledge in the form of constraints, which can lead to outperforming the data on which models are trained. We present Diffusion-Informed Probabilistic Contact Search (DIPS), which uses an A* search to plan a sequence of contact modes informed by a diffusion model. We train the diffusion model on a dataset of demonstrations consisting of contact modes and trajectories generated by a trajectory optimizer given those modes. In addition, we use a particle filter-inspired method to reason about variability in diffusion sampling arising from model error, estimating likelihoods of trajectories using a learned discriminator. We show that our method outperforms ablations that do not reason about variability and can plan contact sequences that outperform those found in training data across multiple tasks. We evaluate on simulated tabletop card sliding and screwdriver turning tasks, as well as the screwdriver task in hardware to show that our combined learning and planning approach transfers to the real world.
ResPilot: Teleoperated Finger Gaiting via Gaussian Process Residual Learning
Sep 13, 2024Dexterous robot hand teleoperation allows for long-range transfer of human manipulation expertise, and could simultaneously provide a way for humans to teach these skills to robots. However, current methods struggle to reproduce the functional workspace of the human hand, often limiting them to simple grasping tasks. We present a novel method for finger-gaited manipulation with multi-fingered robot hands. Our method provides the operator enhanced flexibility in making contacts by expanding the reachable workspace of the robot hand through residual Gaussian Process learning. We also assist the operator in maintaining stable contacts with the object by allowing them to constrain fingertips of the hand to move in concert. Extensive quantitative evaluations show that our method significantly increases the reachable workspace of the robot hand and enables the completion of novel dexterous finger gaiting tasks. Project website: http://respilot-hri.github.io
Multi-finger Manipulation via Trajectory Optimization with Differentiable Rolling and Geometric Constraints
Aug 23, 2024Parameterizing finger rolling and finger-object contacts in a differentiable manner is important for formulating dexterous manipulation as a trajectory optimization problem. In contrast to previous methods which often assume simplified geometries of the robot and object or do not explicitly model finger rolling, we propose a method to further extend the capabilities of dexterous manipulation by accounting for non-trivial geometries of both the robot and the object. By integrating the object's Signed Distance Field (SDF) with a sampling method, our method estimates contact and rolling-related variables and includes those in a trajectory optimization framework. This formulation naturally allows for the emergence of finger-rolling behaviors, enabling the robot to locally adjust the contact points. Our method is tested in a peg alignment task and a screwdriver turning task, where it outperforms the baselines in terms of achieving desired object configurations and avoiding dropping the object. We also successfully apply our method to a real-world screwdriver turning task, demonstrating its robustness to the sim2real gap.
HyperTaxel: Hyper-Resolution for Taxel-Based Tactile Signals Through Contrastive Learning
Aug 15, 2024

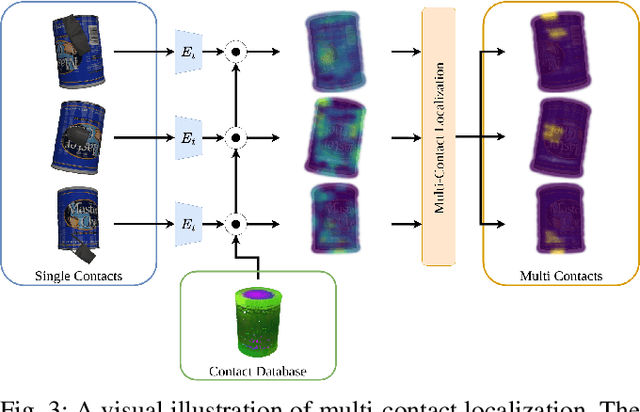

To achieve dexterity comparable to that of humans, robots must intelligently process tactile sensor data. Taxel-based tactile signals often have low spatial-resolution, with non-standardized representations. In this paper, we propose a novel framework, HyperTaxel, for learning a geometrically-informed representation of taxel-based tactile signals to address challenges associated with their spatial resolution. We use this representation and a contrastive learning objective to encode and map sparse low-resolution taxel signals to high-resolution contact surfaces. To address the uncertainty inherent in these signals, we leverage joint probability distributions across multiple simultaneous contacts to improve taxel hyper-resolution. We evaluate our representation by comparing it with two baselines and present results that suggest our representation outperforms the baselines. Furthermore, we present qualitative results that demonstrate the learned representation captures the geometric features of the contact surface, such as flatness, curvature, and edges, and generalizes across different objects and sensor configurations. Moreover, we present results that suggest our representation improves the performance of various downstream tasks, such as surface classification, 6D in-hand pose estimation, and sim-to-real transfer.