 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Learning- and Model-Based Planning and Control of In-Hand Manipulation
Sep 20, 2022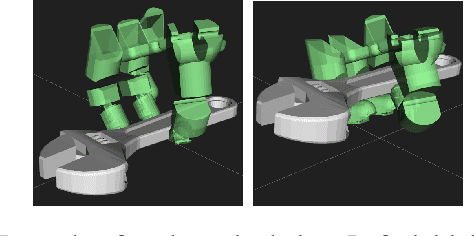
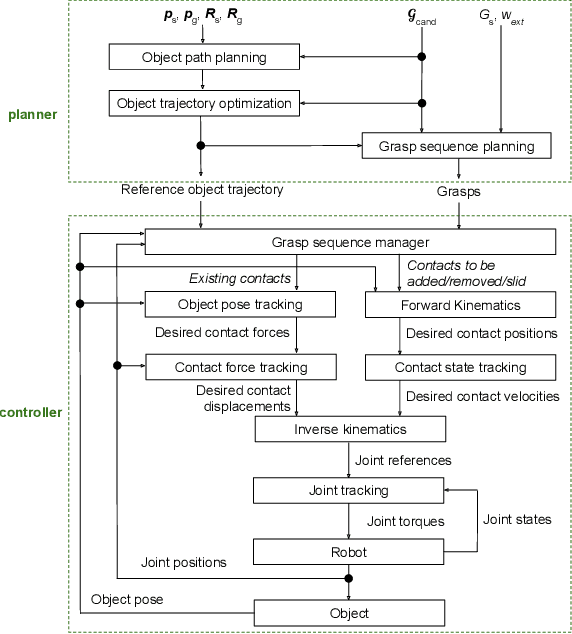
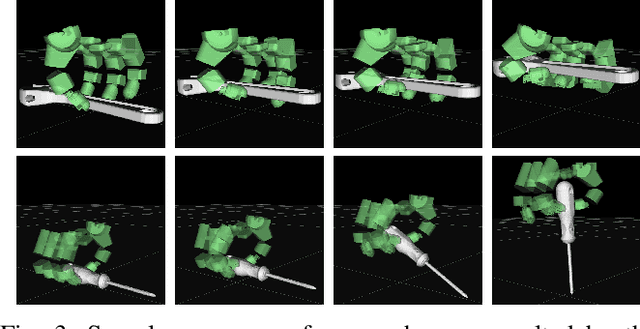
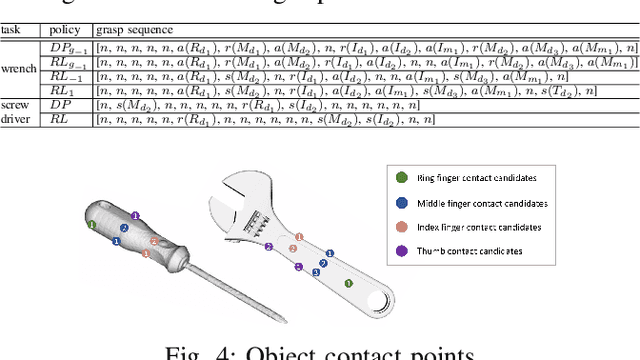
This paper presents a hierarchical framework for planning and control of in-hand manipulation of a rigid object involving grasp changes using fully-actuated multifingered robotic hands. While the framework can be applied to the general dexterous manipulation, we focus on a more complex definition of in-hand manipulation, where at the goal pose the hand has to reach a grasp suitable for using the object as a tool. The high level planner determines the object trajectory as well as the grasp changes, i.e. adding, removing, or sliding fingers, to be executed by the low-level controller. While the grasp sequence is planned online by a learning-based policy to adapt to variations, the trajectory planner and the low-level controller for object tracking and contact force control are exclusively model-based to robustly realize the plan. By infusing the knowledge about the physics of the problem and the low-level controller into the grasp planner, it learns to successfully generate grasps similar to those generated by model-based optimization approaches, obviating the high computation cost of online running of such methods to account for variations. By performing experiments in physics simulation for realistic tool use scenarios, we show the success of our method on different tool-use tasks and dexterous hand models. Additionally, we show that this hybrid method offers more robustness to trajectory and task variations compared to a model-based method.
VisuoSpatial Foresight for Physical Sequential Fabric Manipulation
Feb 19, 2021
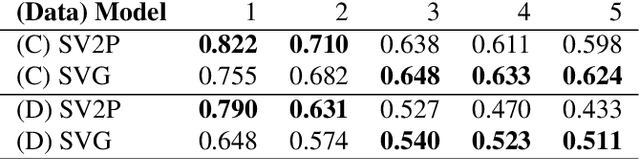
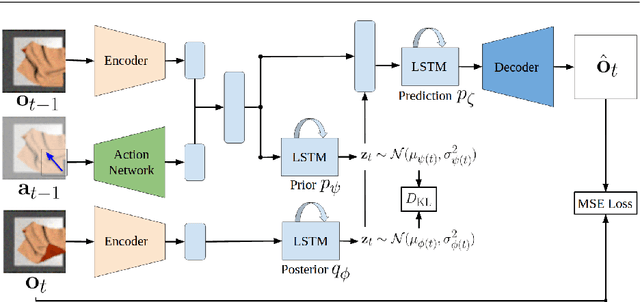
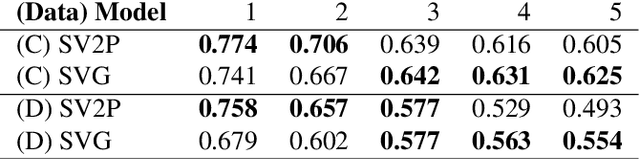
Robotic fabric manipulation has applications in home robotics, textiles, senior care and surgery. Existing fabric manipulation techniques, however, are designed for specific tasks, making it difficult to generalize across different but related tasks. We build upon the Visual Foresight framework to learn fabric dynamics that can be efficiently reused to accomplish different sequential fabric manipulation tasks with a single goal-conditioned policy. We extend our earlier work on VisuoSpatial Foresight (VSF), which learns visual dynamics on domain randomized RGB images and depth maps simultaneously and completely in simulation. In this earlier work, we evaluated VSF on multi-step fabric smoothing and folding tasks against 5 baseline methods in simulation and on the da Vinci Research Kit (dVRK) surgical robot without any demonstrations at train or test time. A key finding was that depth sensing significantly improves performance: RGBD data yields an 80% improvement in fabric folding success rate in simulation over pure RGB data. In this work, we vary 4 components of VSF, including data generation, the choice of visual dynamics model, cost function, and optimization procedure. Results suggest that training visual dynamics models using longer, corner-based actions can improve the efficiency of fabric folding by 76% and enable a physical sequential fabric folding task that VSF could not previously perform with 90% reliability. Code, data, videos, and supplementary material are available at https://sites.google.com/view/fabric-vsf/.
Learning Whole-Body Human-Robot Haptic Interaction in Social Contexts
May 26, 2020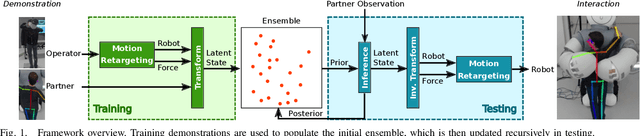
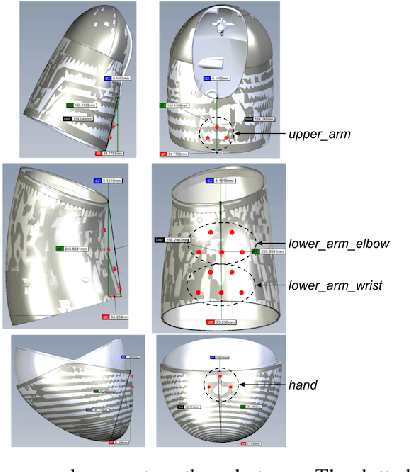
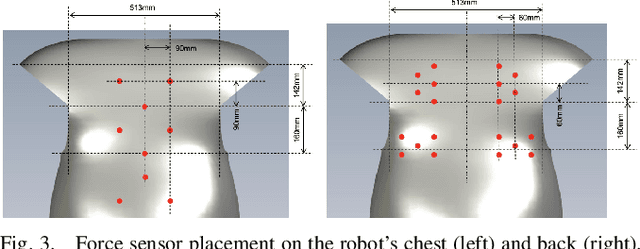
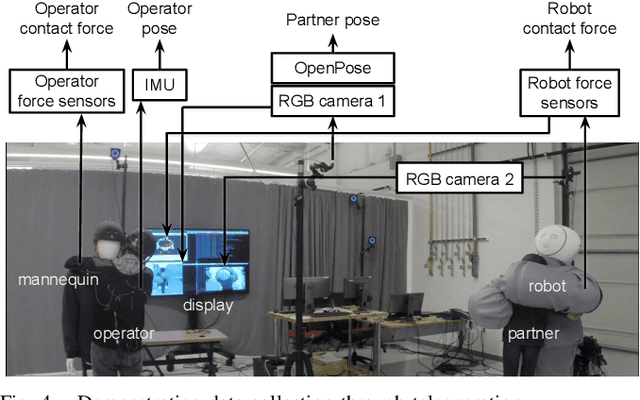
This paper presents a learning-from-demonstration (LfD) framework for teaching human-robot social interactions that involve whole-body haptic interaction, i.e. direct human-robot contact over the full robot body. The performance of existing LfD frameworks suffers in such interactions due to the high dimensionality and spatiotemporal sparsity of the demonstration data. We show that by leveraging this sparsity, we can reduce the data dimensionality without incurring a significant accuracy penalty, and introduce three strategies for doing so. By combining these techniques with an LfD framework for learning multimodal human-robot interactions, we can model the spatiotemporal relationship between the tactile and kinesthetic information during whole-body haptic interactions. Using a teleoperated bimanual robot equipped with 61 force sensors, we experimentally demonstrate that a model trained with 121 sample hugs from 4 participants generalizes well to unseen inputs and human partners.
Learning to Smooth and Fold Real Fabric Using Dense Object Descriptors Trained on Synthetic Color Images
Mar 28, 2020
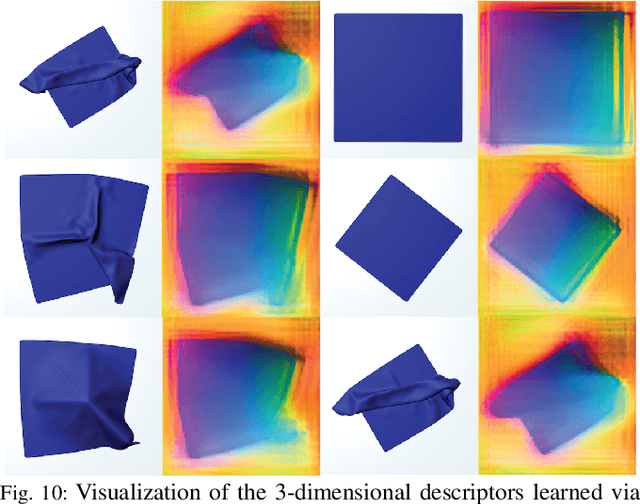


Robotic fabric manipulation is challenging due to the infinite dimensional configuration space and complex dynamics. In this paper, we learn visual representations of deformable fabric by training dense object descriptors that capture correspondences across images of fabric in various configurations. The learned descriptors capture higher level geometric structure, facilitating design of explainable policies. We demonstrate that the learned representation facilitates multistep fabric smoothing and folding tasks on two real physical systems, the da Vinci surgical robot and the ABB YuMi given high level demonstrations from a supervisor. The system achieves a 78.8% average task success rate across six fabric manipulation tasks. See https://tinyurl.com/fabric-descriptors for supplementary material and videos.
VisuoSpatial Foresight for Multi-Step, Multi-Task Fabric Manipulation
Mar 19, 2020
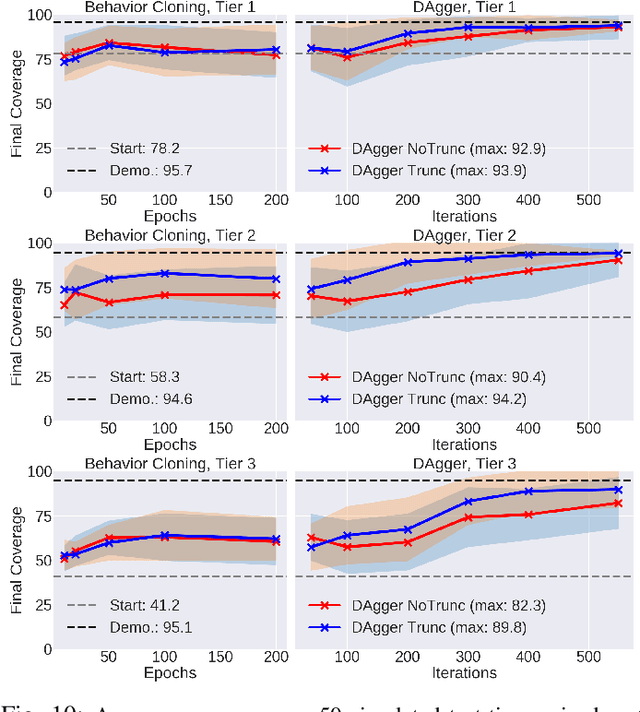
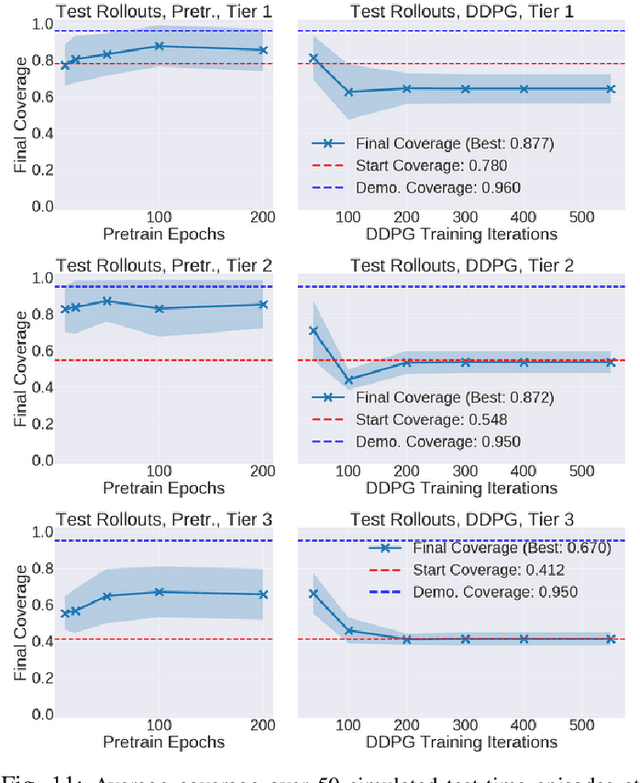
Robotic fabric manipulation has applications in cloth and cable management, senior care, surgery and more. Existing fabric manipulation techniques, however, are designed for specific tasks, making it difficult to generalize across different but related tasks. We address this problem by extending the recently proposed Visual Foresight framework to learn fabric dynamics, which can be efficiently reused to accomplish a variety of different fabric manipulation tasks with a single goal-conditioned policy. We introduce VisuoSpatial Foresight (VSF), which extends prior work by learning visual dynamics on domain randomized RGB images and depth maps simultaneously and completely in simulation. We experimentally evaluate VSF on multi-step fabric smoothing and folding tasks both in simulation and on the da Vinci Research Kit (dVRK) surgical robot without any demonstrations at train or test time. Furthermore, we find that leveraging depth significantly improves performance for cloth manipulation tasks, and results suggest that leveraging RGBD data for video prediction and planning yields an 80% improvement in fabric folding success rate over pure RGB data. Supplementary material is available at https://sites.google.com/view/fabric-vsf/.
Deep Imitation Learning of Sequential Fabric Smoothing Policies
Sep 23, 2019



Sequential pulling policies to flatten and smooth fabrics have applications from surgery to manufacturing to home tasks such as bed making and folding clothes. Due to the complexity of fabric states and dynamics, we apply deep imitation learning to learn policies that, given color or depth images of a rectangular fabric sample, estimate pick points and pull vectors to spread the fabric to maximize coverage. To generate data, we develop a fabric simulator and an algorithmic demonstrator that has access to complete state information. We train policies in simulation using domain randomization and dataset aggregation (DAgger) on three tiers of difficulty in the initial randomized configuration. We present results comparing five baseline policies to learned policies and report systematic comparisons of color vs. depth images as inputs. In simulation, learned policies achieve comparable or superior performance to analytic baselines. In 120 physical experiments with the da Vinci Research Kit (dVRK) surgical robot, policies trained in simulation attain 86% and 69% final coverage for color and depth inputs, respectively, suggesting the feasibility of learning fabric smoothing policies from simulation. Supplementary material is available at https://sites.google.com/view/ fabric-smoothing.