 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Correspondence for Deformable Objects
May 14, 2024
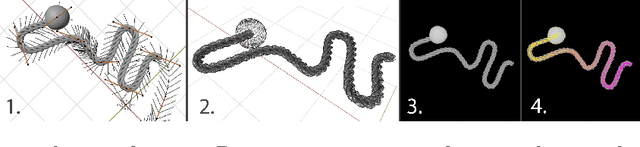


We investigate the problem of pixelwise correspondence for deformable objects, namely cloth and rope, by comparing both classical and learning-based methods. We choose cloth and rope because they are traditionally some of the most difficult deformable objects to analytically model with their large configuration space, and they are meaningful in the context of robotic tasks like cloth folding, rope knot-tying, T-shirt folding, curtain closing, etc. The correspondence problem is heavily motivated in robotics, with wide-ranging applications including semantic grasping, object tracking, and manipulation policies built on top of correspondences. We present an exhaustive survey of existing classical methods for doing correspondence via feature-matching, including SIFT, SURF, and ORB, and two recently published learning-based methods including TimeCycle and Dense Object Nets. We make three main contributions: (1) a framework for simulating and rendering synthetic images of deformable objects, with qualitative results demonstrating transfer between our simulated and real domains (2) a new learning-based correspondence method extending Dense Object Nets, and (3) a standardized comparison across state-of-the-art correspondence methods. Our proposed method provides a flexible, general formulation for learning temporally and spatially continuous correspondences for nonrigid (and rigid) objects. We report root mean squared error statistics for all methods and find that Dense Object Nets outperforms baseline classical methods for correspondence, and our proposed extension of Dense Object Nets performs similarly.
Learning to Fold Real Garments with One Arm: A Case Study in Cloud-Based Robotics Research
Apr 21, 2022


Autonomous fabric manipulation is a longstanding challenge in robotics, but evaluating progress is difficult due to the cost and diversity of robot hardware. Using Reach, a cloud robotics platform that enables low-latency remote execution of control policies on physical robots, we present the first systematic benchmarking of fabric manipulation algorithms on physical hardware. We develop 4 novel learning-based algorithms that model expert actions, keypoints, reward functions, and dynamic motions, and we compare these against 4 learning-free and inverse dynamics algorithms on the task of folding a crumpled T-shirt with a single robot arm. The entire lifecycle of data collection, model training, and policy evaluation is performed remotely without physical access to the robot workcell. Results suggest a new algorithm combining imitation learning with analytic methods achieves 84% of human-level performance on the folding task. See https://sites.google.com/berkeley.edu/cloudfolding for all data, code, models, and supplemental material.
Implicit Kinematic Policies: Unifying Joint and Cartesian Action Spaces in End-to-End Robot Learning
Mar 03, 2022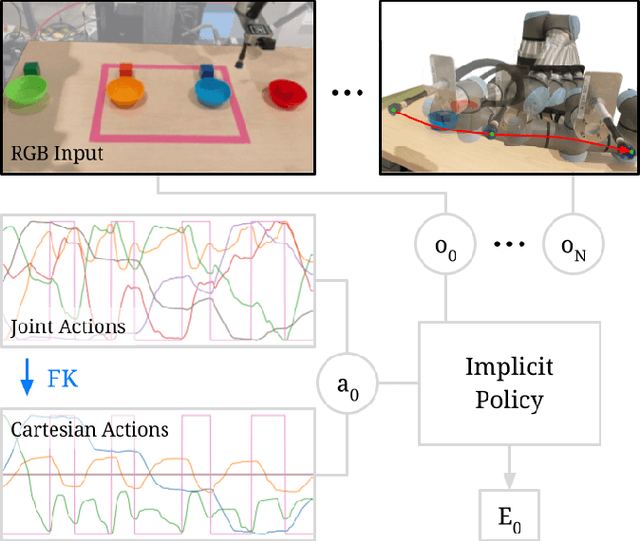
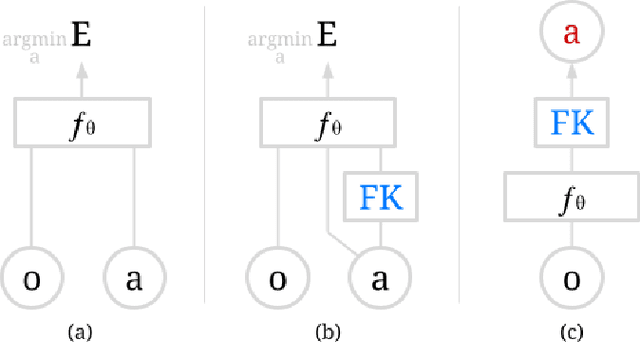
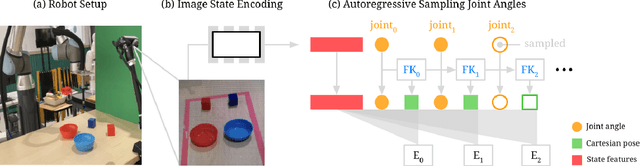
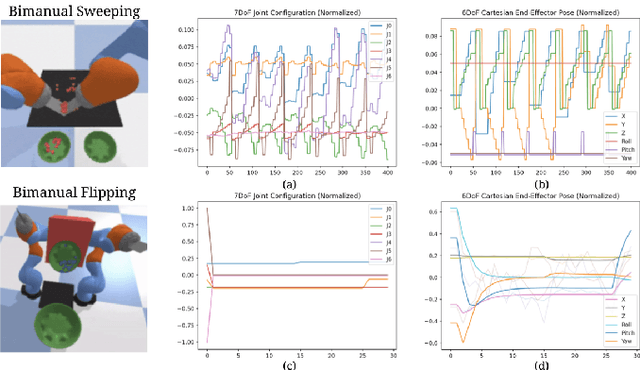
Action representation is an important yet often overlooked aspect in end-to-end robot learning with deep networks. Choosing one action space over another (e.g. target joint positions, or Cartesian end-effector poses) can result in surprisingly stark performance differences between various downstream tasks -- and as a result, considerable research has been devoted to finding the right action space for a given application. However, in this work, we instead investigate how our models can discover and learn for themselves which action space to use. Leveraging recent work on implicit behavioral cloning, which takes both observations and actions as input, we demonstrate that it is possible to present the same action in multiple different spaces to the same policy -- allowing it to learn inductive patterns from each space. Specifically, we study the benefits of combining Cartesian and joint action spaces in the context of learning manipulation skills. To this end, we present Implicit Kinematic Policies (IKP), which incorporates the kinematic chain as a differentiable module within the deep network. Quantitative experiments across several simulated continuous control tasks -- from scooping piles of small objects, to lifting boxes with elbows, to precise block insertion with miscalibrated robots -- suggest IKP not only learns complex prehensile and non-prehensile manipulation from pixels better than baseline alternatives, but also can learn to compensate for small joint encoder offset errors. Finally, we also run qualitative experiments on a real UR5e to demonstrate the feasibility of our algorithm on a physical robotic system with real data. See https://tinyurl.com/4wz3nf86 for code and supplementary material.
VisuoSpatial Foresight for Physical Sequential Fabric Manipulation
Feb 19, 2021
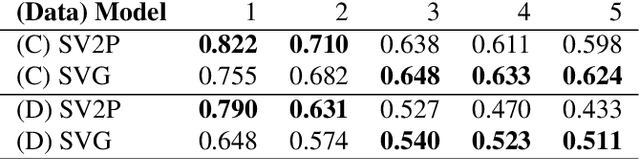
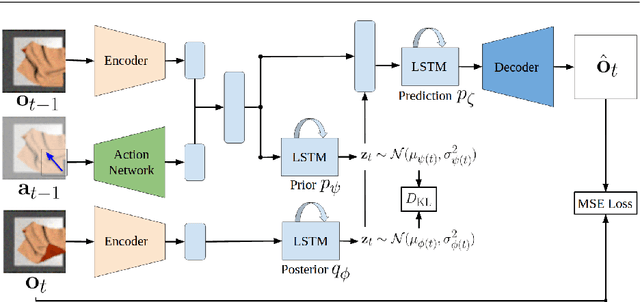
Robotic fabric manipulation has applications in home robotics, textiles, senior care and surgery. Existing fabric manipulation techniques, however, are designed for specific tasks, making it difficult to generalize across different but related tasks. We build upon the Visual Foresight framework to learn fabric dynamics that can be efficiently reused to accomplish different sequential fabric manipulation tasks with a single goal-conditioned policy. We extend our earlier work on VisuoSpatial Foresight (VSF), which learns visual dynamics on domain randomized RGB images and depth maps simultaneously and completely in simulation. In this earlier work, we evaluated VSF on multi-step fabric smoothing and folding tasks against 5 baseline methods in simulation and on the da Vinci Research Kit (dVRK) surgical robot without any demonstrations at train or test time. A key finding was that depth sensing significantly improves performance: RGBD data yields an 80% improvement in fabric folding success rate in simulation over pure RGB data. In this work, we vary 4 components of VSF, including data generation, the choice of visual dynamics model, cost function, and optimization procedure. Results suggest that training visual dynamics models using longer, corner-based actions can improve the efficiency of fabric folding by 76% and enable a physical sequential fabric folding task that VSF could not previously perform with 90% reliability. Code, data, videos, and supplementary material are available at https://sites.google.com/view/fabric-vsf/.
MMGSD: Multi-Modal Gaussian Shape Descriptors for Correspondence Matching in 1D and 2D Deformable Objects
Oct 09, 2020

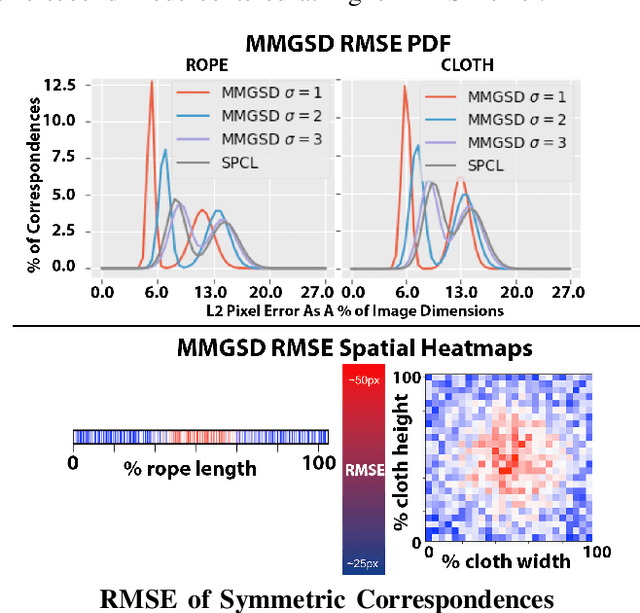
We explore learning pixelwise correspondences between images of deformable objects in different configurations. Traditional correspondence matching approaches such as SIFT, SURF, and ORB can fail to provide sufficient contextual information for fine-grained manipulation. We propose Multi-Modal Gaussian Shape Descriptor (MMGSD), a new visual representation of deformable objects which extends ideas from dense object descriptors to predict all symmetric correspondences between different object configurations. MMGSD is learned in a self-supervised manner from synthetic data and produces correspondence heatmaps with measurable uncertainty. In simulation, experiments suggest that MMGSD can achieve an RMSE of 32.4 and 31.3 for square cloth and braided synthetic nylon rope respectively. The results demonstrate an average of 47.7% improvement over a provided baseline based on contrastive learning, symmetric pixel-wise contrastive loss (SPCL), as opposed to MMGSD which enforces distributional continuity.
Learning to Smooth and Fold Real Fabric Using Dense Object Descriptors Trained on Synthetic Color Images
Mar 28, 2020
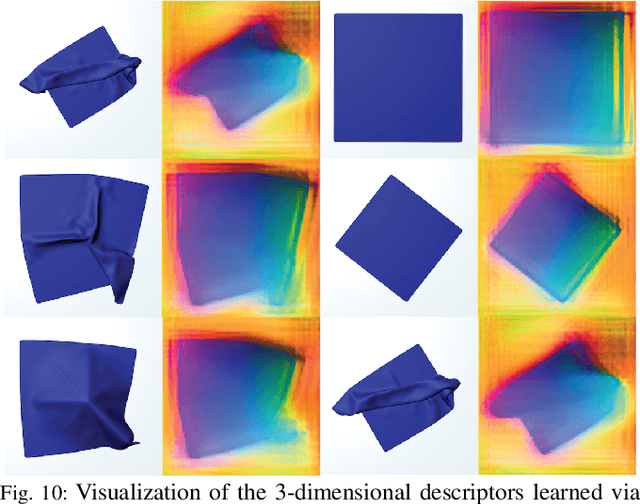


Robotic fabric manipulation is challenging due to the infinite dimensional configuration space and complex dynamics. In this paper, we learn visual representations of deformable fabric by training dense object descriptors that capture correspondences across images of fabric in various configurations. The learned descriptors capture higher level geometric structure, facilitating design of explainable policies. We demonstrate that the learned representation facilitates multistep fabric smoothing and folding tasks on two real physical systems, the da Vinci surgical robot and the ABB YuMi given high level demonstrations from a supervisor. The system achieves a 78.8% average task success rate across six fabric manipulation tasks. See https://tinyurl.com/fabric-descriptors for supplementary material and videos.
VisuoSpatial Foresight for Multi-Step, Multi-Task Fabric Manipulation
Mar 19, 2020
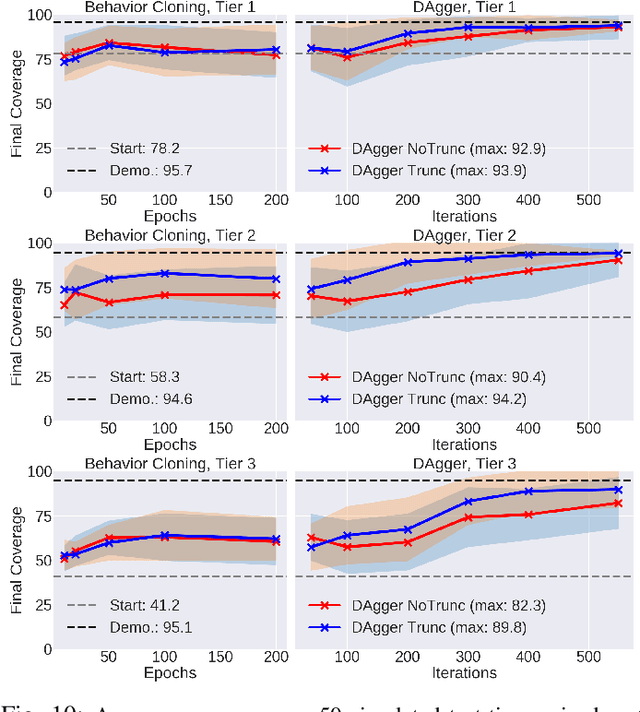
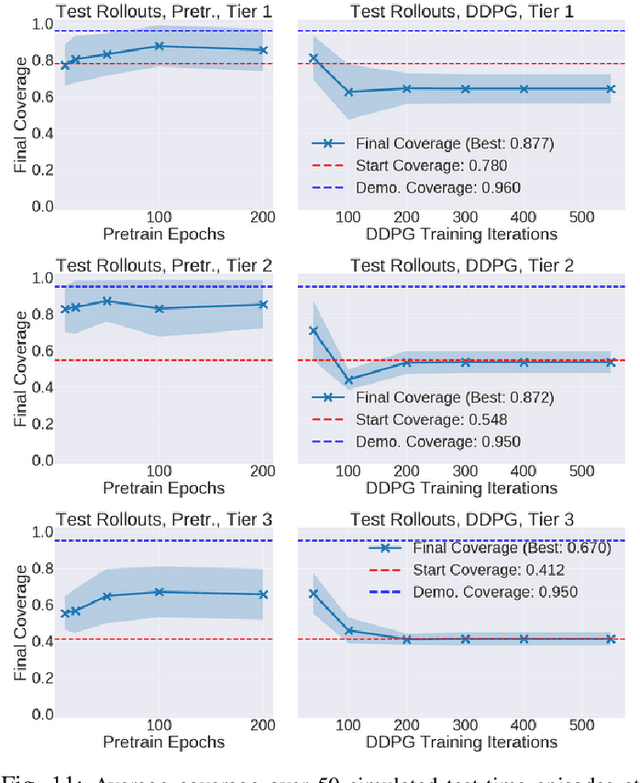
Robotic fabric manipulation has applications in cloth and cable management, senior care, surgery and more. Existing fabric manipulation techniques, however, are designed for specific tasks, making it difficult to generalize across different but related tasks. We address this problem by extending the recently proposed Visual Foresight framework to learn fabric dynamics, which can be efficiently reused to accomplish a variety of different fabric manipulation tasks with a single goal-conditioned policy. We introduce VisuoSpatial Foresight (VSF), which extends prior work by learning visual dynamics on domain randomized RGB images and depth maps simultaneously and completely in simulation. We experimentally evaluate VSF on multi-step fabric smoothing and folding tasks both in simulation and on the da Vinci Research Kit (dVRK) surgical robot without any demonstrations at train or test time. Furthermore, we find that leveraging depth significantly improves performance for cloth manipulation tasks, and results suggest that leveraging RGBD data for video prediction and planning yields an 80% improvement in fabric folding success rate over pure RGB data. Supplementary material is available at https://sites.google.com/view/fabric-vsf/.
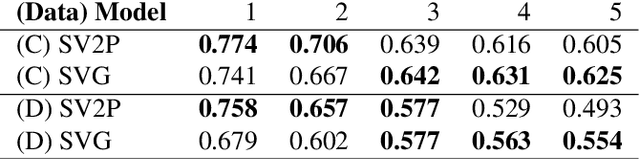
Deep Imitation Learning of Sequential Fabric Smoothing Policies
Sep 23, 2019



Sequential pulling policies to flatten and smooth fabrics have applications from surgery to manufacturing to home tasks such as bed making and folding clothes. Due to the complexity of fabric states and dynamics, we apply deep imitation learning to learn policies that, given color or depth images of a rectangular fabric sample, estimate pick points and pull vectors to spread the fabric to maximize coverage. To generate data, we develop a fabric simulator and an algorithmic demonstrator that has access to complete state information. We train policies in simulation using domain randomization and dataset aggregation (DAgger) on three tiers of difficulty in the initial randomized configuration. We present results comparing five baseline policies to learned policies and report systematic comparisons of color vs. depth images as inputs. In simulation, learned policies achieve comparable or superior performance to analytic baselines. In 120 physical experiments with the da Vinci Research Kit (dVRK) surgical robot, policies trained in simulation attain 86% and 69% final coverage for color and depth inputs, respectively, suggesting the feasibility of learning fabric smoothing policies from simulation. Supplementary material is available at https://sites.google.com/view/ fabric-smoothing.