 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepsNet: Combining Vision with Language for Automated Medical Reports
Sep 27, 2022Writing reports by analyzing medical images is error-prone for inexperienced practitioners and time consuming for experienced ones. In this work, we present RepsNet that adapts pre-trained vision and language models to interpret medical images and generate automated reports in natural language. RepsNet consists of an encoder-decoder model: the encoder aligns the images with natural language descriptions via contrastive learning, while the decoder predicts answers by conditioning on encoded images and prior context of descriptions retrieved by nearest neighbor search. We formulate the problem in a visual question answering setting to handle both categorical and descriptive natural language answers. We perform experiments on two challenging tasks of medical visual question answering (VQA-Rad) and report generation (IU-Xray) on radiology image datasets. Results show that RepsNet outperforms state-of-the-art methods with 81.08 % classification accuracy on VQA-Rad 2018 and 0.58 BLEU-1 score on IU-Xray. Supplementary details are available at https://sites.google.com/view/repsnet
VisuoSpatial Foresight for Physical Sequential Fabric Manipulation
Feb 19, 2021
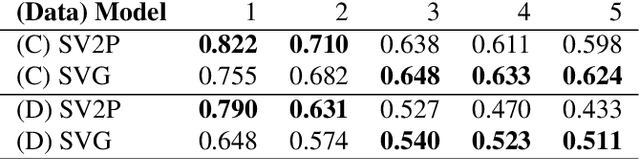
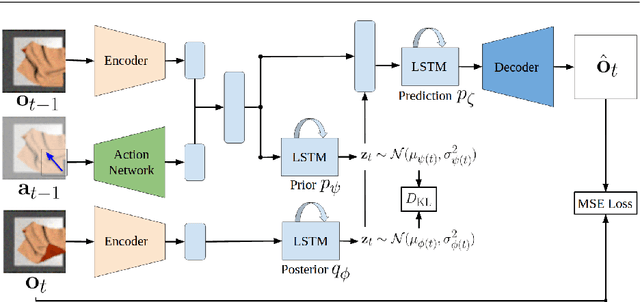
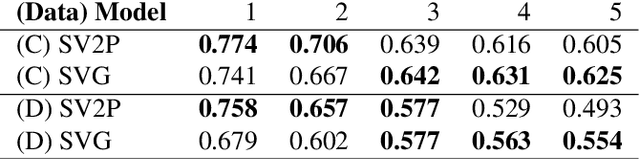
Robotic fabric manipulation has applications in home robotics, textiles, senior care and surgery. Existing fabric manipulation techniques, however, are designed for specific tasks, making it difficult to generalize across different but related tasks. We build upon the Visual Foresight framework to learn fabric dynamics that can be efficiently reused to accomplish different sequential fabric manipulation tasks with a single goal-conditioned policy. We extend our earlier work on VisuoSpatial Foresight (VSF), which learns visual dynamics on domain randomized RGB images and depth maps simultaneously and completely in simulation. In this earlier work, we evaluated VSF on multi-step fabric smoothing and folding tasks against 5 baseline methods in simulation and on the da Vinci Research Kit (dVRK) surgical robot without any demonstrations at train or test time. A key finding was that depth sensing significantly improves performance: RGBD data yields an 80% improvement in fabric folding success rate in simulation over pure RGB data. In this work, we vary 4 components of VSF, including data generation, the choice of visual dynamics model, cost function, and optimization procedure. Results suggest that training visual dynamics models using longer, corner-based actions can improve the efficiency of fabric folding by 76% and enable a physical sequential fabric folding task that VSF could not previously perform with 90% reliability. Code, data, videos, and supplementary material are available at https://sites.google.com/view/fabric-vsf/.
DIRL: Domain-Invariant Representation Learning for Sim-to-Real Transfer
Nov 27, 2020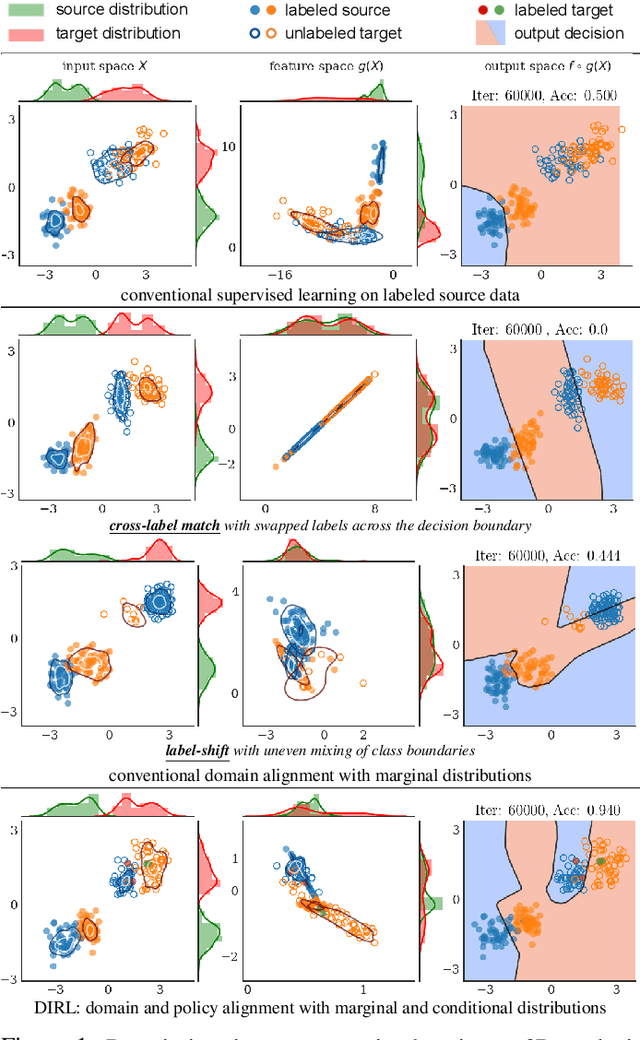



Generating large-scale synthetic data in simulation is a feasible alternative to collecting/labelling real data for training vision-based deep learning models, albeit the modelling inaccuracies do not generalize to the physical world. In this paper, we present a domain-invariant representation learning (DIRL) algorithm to adapt deep models to the physical environment with a small amount of real data. Existing approaches that only mitigate the covariate shift by aligning the marginal distributions across the domains and assume the conditional distributions to be domain-invariant can lead to ambiguous transfer in real scenarios. We propose to jointly align the marginal (input domains) and the conditional (output labels) distributions to mitigate the covariate and the conditional shift across the domains with adversarial learning, and combine it with a triplet distribution loss to make the conditional distributions disjoint in the shared feature space. Experiments on digit domains yield state-of-the-art performance on challenging benchmarks, while sim-to-real transfer of object recognition for vision-based decluttering with a mobile robot improves from 26.8 % to 91.0 %, resulting in 86.5 % grasping accuracy of a wide variety of objects. Code and supplementary details are available at https://sites.google.com/view/dirl
Motion2Vec: Semi-Supervised Representation Learning from Surgical Videos
May 31, 2020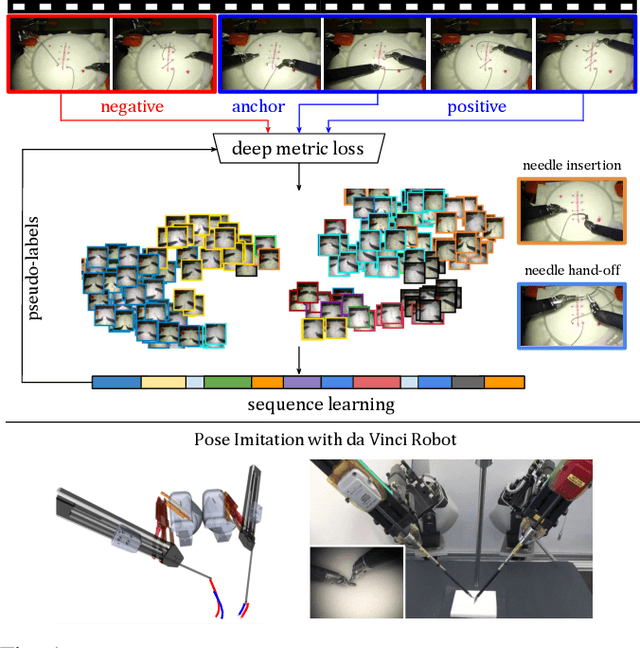



Learning meaningful visual representations in an embedding space can facilitate generalization in downstream tasks such as action segmentation and imitation. In this paper, we learn a motion-centric representation of surgical video demonstrations by grouping them into action segments/sub-goals/options in a semi-supervised manner. We present Motion2Vec, an algorithm that learns a deep embedding feature space from video observations by minimizing a metric learning loss in a Siamese network: images from the same action segment are pulled together while pushed away from randomly sampled images of other segments, while respecting the temporal ordering of the images. The embeddings are iteratively segmented with a recurrent neural network for a given parametrization of the embedding space after pre-training the Siamese network. We only use a small set of labeled video segments to semantically align the embedding space and assign pseudo-labels to the remaining unlabeled data by inference on the learned model parameters. We demonstrate the use of this representation to imitate surgical suturing motions from publicly available videos of the JIGSAWS dataset. Results give 85.5 % segmentation accuracy on average suggesting performance improvement over several state-of-the-art baselines, while kinematic pose imitation gives 0.94 centimeter error in position per observation on the test set. Videos, code and data are available at https://sites.google.com/view/motion2vec
VisuoSpatial Foresight for Multi-Step, Multi-Task Fabric Manipulation
Mar 19, 2020
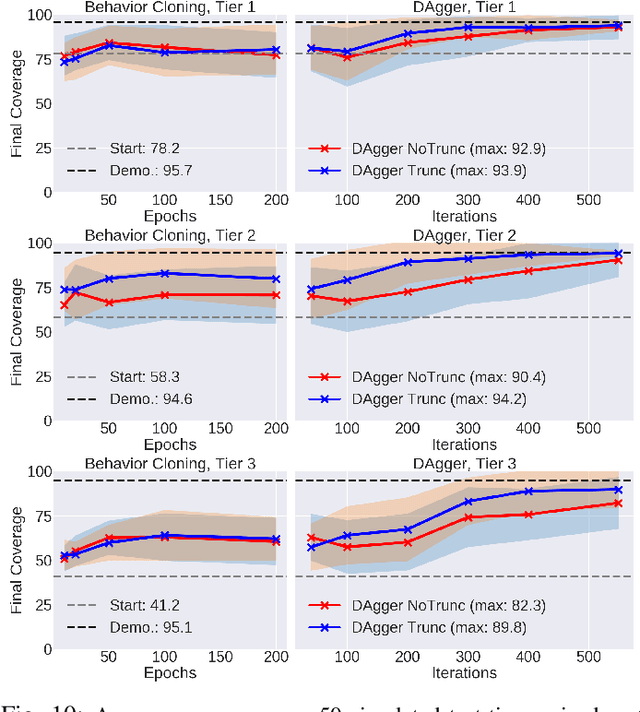
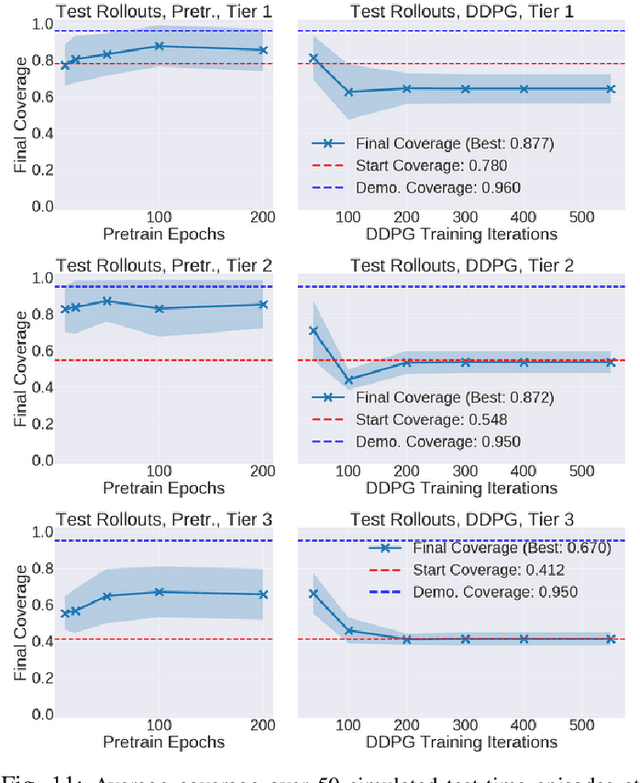
Robotic fabric manipulation has applications in cloth and cable management, senior care, surgery and more. Existing fabric manipulation techniques, however, are designed for specific tasks, making it difficult to generalize across different but related tasks. We address this problem by extending the recently proposed Visual Foresight framework to learn fabric dynamics, which can be efficiently reused to accomplish a variety of different fabric manipulation tasks with a single goal-conditioned policy. We introduce VisuoSpatial Foresight (VSF), which extends prior work by learning visual dynamics on domain randomized RGB images and depth maps simultaneously and completely in simulation. We experimentally evaluate VSF on multi-step fabric smoothing and folding tasks both in simulation and on the da Vinci Research Kit (dVRK) surgical robot without any demonstrations at train or test time. Furthermore, we find that leveraging depth significantly improves performance for cloth manipulation tasks, and results suggest that leveraging RGBD data for video prediction and planning yields an 80% improvement in fabric folding success rate over pure RGB data. Supplementary material is available at https://sites.google.com/view/fabric-vsf/.
Deep Imitation Learning of Sequential Fabric Smoothing Policies
Sep 23, 2019



Sequential pulling policies to flatten and smooth fabrics have applications from surgery to manufacturing to home tasks such as bed making and folding clothes. Due to the complexity of fabric states and dynamics, we apply deep imitation learning to learn policies that, given color or depth images of a rectangular fabric sample, estimate pick points and pull vectors to spread the fabric to maximize coverage. To generate data, we develop a fabric simulator and an algorithmic demonstrator that has access to complete state information. We train policies in simulation using domain randomization and dataset aggregation (DAgger) on three tiers of difficulty in the initial randomized configuration. We present results comparing five baseline policies to learned policies and report systematic comparisons of color vs. depth images as inputs. In simulation, learned policies achieve comparable or superior performance to analytic baselines. In 120 physical experiments with the da Vinci Research Kit (dVRK) surgical robot, policies trained in simulation attain 86% and 69% final coverage for color and depth inputs, respectively, suggesting the feasibility of learning fabric smoothing policies from simulation. Supplementary material is available at https://sites.google.com/view/ fabric-smoothing.
A Fog Robotics Approach to Deep Robot Learning: Application to Object Recognition and Grasp Planning in Surface Decluttering
Mar 22, 2019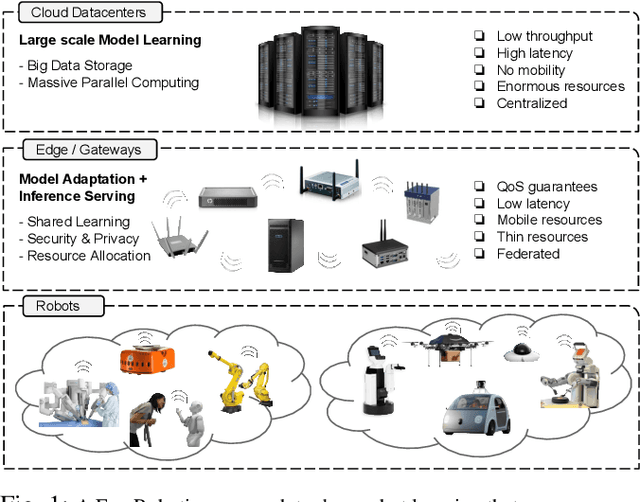


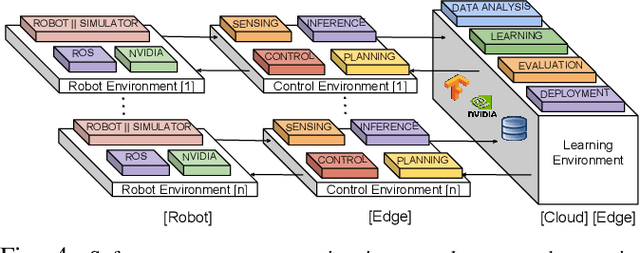
The growing demand of industrial, automotive and service robots presents a challenge to the centralized Cloud Robotics model in terms of privacy, security, latency, bandwidth, and reliability. In this paper, we present a `Fog Robotics' approach to deep robot learning that distributes compute, storage and networking resources between the Cloud and the Edge in a federated manner. Deep models are trained on non-private (public) synthetic images in the Cloud; the models are adapted to the private real images of the environment at the Edge within a trusted network and subsequently, deployed as a service for low-latency and secure inference/prediction for other robots in the network. We apply this approach to surface decluttering, where a mobile robot picks and sorts objects from a cluttered floor by learning a deep object recognition and a grasp planning model. Experiments suggest that Fog Robotics can improve performance by sim-to-real domain adaptation in comparison to exclusively using Cloud or Edge resources, while reducing the inference cycle time by 4\times to successfully declutter 86% of objects over 213 attempts.
Generalizing Robot Imitation Learning with Invariant Hidden Semi-Markov Models
Nov 19, 2018
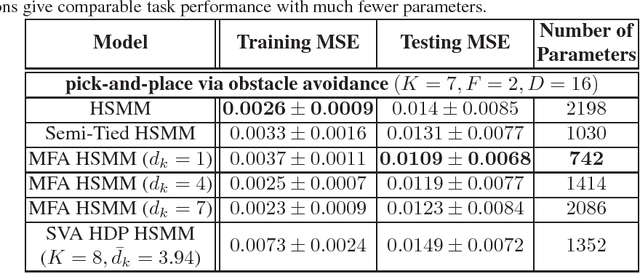
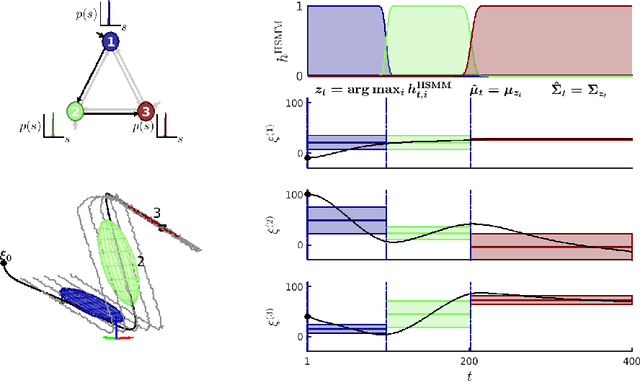

Generalizing manipulation skills to new situations requires extracting invariant patterns from demonstrations. For example, the robot needs to understand the demonstrations at a higher level while being invariant to the appearance of the objects, geometric aspects of objects such as its position, size, orientation and viewpoint of the observer in the demonstrations. In this paper, we propose an algorithm that learns a joint probability density function of the demonstrations with invariant formulations of hidden semi-Markov models to extract invariant segments (also termed as sub-goals or options), and smoothly follow the generated sequence of states with a linear quadratic tracking controller. The algorithm takes as input the demonstrations with respect to different coordinate systems describing virtual landmarks or objects of interest with a task-parameterized formulation, and adapt the segments according to the environmental changes in a systematic manner. We present variants of this algorithm in latent space with low-rank covariance decompositions, semi-tied covariances, and non-parametric online estimation of model parameters under small variance asymptotics; yielding considerably low sample and model complexity for acquiring new manipulation skills. The algorithm allows a Baxter robot to learn a pick-and-place task while avoiding a movable obstacle based on only 4 kinesthetic demonstrations.
A Dynamic Regret Analysis and Adaptive Regularization Algorithm for On-Policy Robot Imitation Learning
Nov 06, 2018
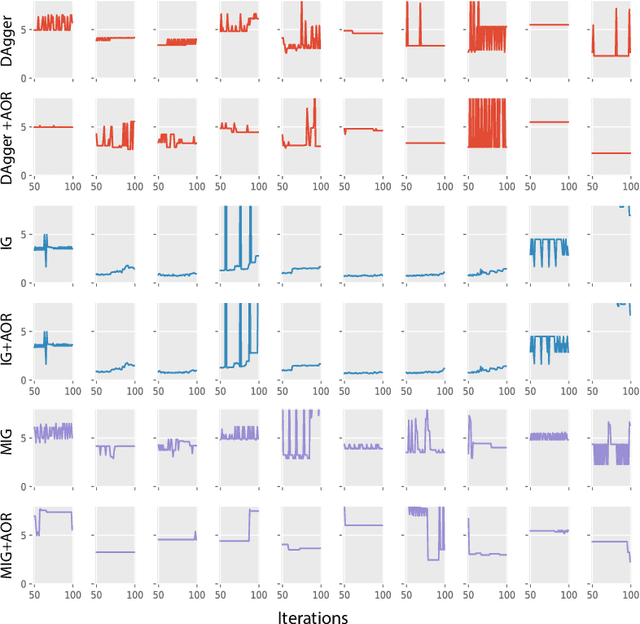
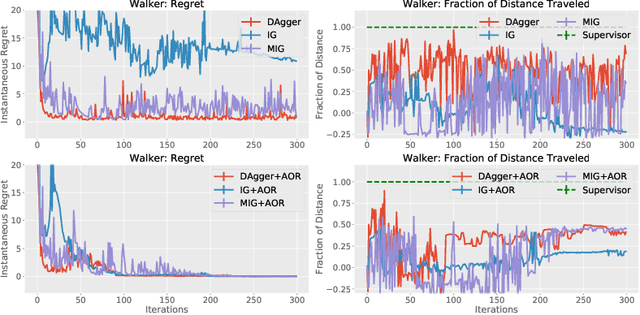
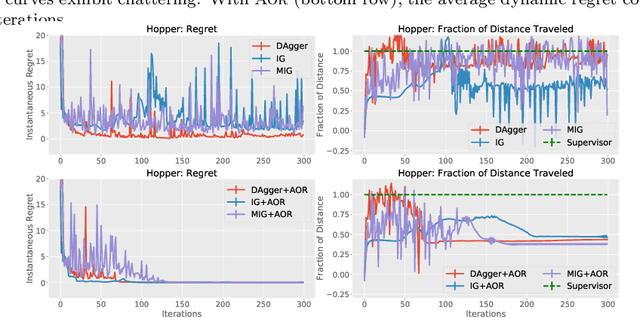
On-policy imitation learning algorithms such as Dagger evolve a robot control policy by executing it, measuring performance (loss), obtaining corrective feedback from a supervisor, and generating the next policy. As the loss between iterations can vary unpredictably, a fundamental question is under what conditions this process will eventually achieve a converged policy. If one assumes the underlying trajectory distribution is static (stationary), it is possible to prove convergence for Dagger. Cheng and Boots (2018) consider the more realistic model for robotics where the underlying trajectory distribution, which is a function of the policy, is dynamic and show that it is possible to prove convergence when a condition on the rate of change of the trajectory distributions is satisfied. In this paper, we reframe that result using dynamic regret theory from the field of Online Optimization to prove convergence to locally optimal policies for Dagger, Imitation Gradient, and Multiple Imitation Gradient. These results inspire a new algorithm, Adaptive On-Policy Regularization (AOR), that ensures the conditions for convergence. We present simulation results with cart-pole balancing and walker locomotion benchmarks that suggest AOR can significantly decrease dynamic regret and chattering. To our knowledge, this the first application of dynamic regret theory to imitation learning.
Small Variance Asymptotics for Non-Parametric Online Robot Learning
Oct 15, 2018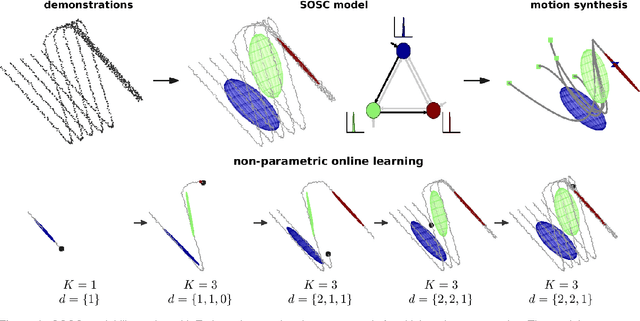



Small variance asymptotics is emerging as a useful technique for inference in large scale Bayesian non-parametric mixture models. This paper analyses the online learning of robot manipulation tasks with Bayesian non-parametric mixture models under small variance asymptotics. The analysis yields a scalable online sequence clustering (SOSC) algorithm that is non-parametric in the number of clusters and the subspace dimension of each cluster. SOSC groups the new datapoint in its low dimensional subspace by online inference in a non-parametric mixture of probabilistic principal component analyzers (MPPCA) based on Dirichlet process, and captures the state transition and state duration information online in a hidden semi-Markov model (HSMM) based on hierarchical Dirichlet process. A task-parameterized formulation of our approach autonomously adapts the model to changing environmental situations during manipulation. We apply the algorithm in a teleoperation setting to recognize the intention of the operator and remotely adjust the movement of the robot using the learned model. The generative model is used to synthesize both time-independent and time-dependent behaviours by relying on the principles of shared and autonomous control. Experiments with the Baxter robot yield parsimonious clusters that adapt online with new demonstrations and assist the operator in performing remote manipulation tasks.