 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotion2Vec: Semi-Supervised Representation Learning from Surgical Videos
May 31, 2020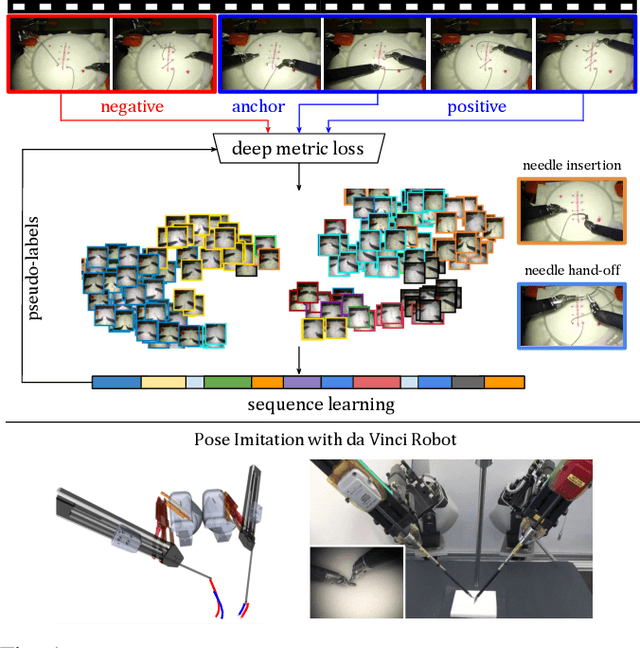



Learning meaningful visual representations in an embedding space can facilitate generalization in downstream tasks such as action segmentation and imitation. In this paper, we learn a motion-centric representation of surgical video demonstrations by grouping them into action segments/sub-goals/options in a semi-supervised manner. We present Motion2Vec, an algorithm that learns a deep embedding feature space from video observations by minimizing a metric learning loss in a Siamese network: images from the same action segment are pulled together while pushed away from randomly sampled images of other segments, while respecting the temporal ordering of the images. The embeddings are iteratively segmented with a recurrent neural network for a given parametrization of the embedding space after pre-training the Siamese network. We only use a small set of labeled video segments to semantically align the embedding space and assign pseudo-labels to the remaining unlabeled data by inference on the learned model parameters. We demonstrate the use of this representation to imitate surgical suturing motions from publicly available videos of the JIGSAWS dataset. Results give 85.5 % segmentation accuracy on average suggesting performance improvement over several state-of-the-art baselines, while kinematic pose imitation gives 0.94 centimeter error in position per observation on the test set. Videos, code and data are available at https://sites.google.com/view/motion2vec