 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometrically Plausible Object Pose Refinement using Differentiable Simulation
Mar 22, 2026State-of-the-art object pose estimation methods are prone to generating geometrically infeasible pose hypotheses. This problem is prevalent in dexterous manipulation, where estimated poses often intersect with the robotic hand or are not lying on a support surface. We propose a multi-modal pose refinement approach that combines differentiable physics simulation, differentiable rendering and visuo-tactile sensing to optimize object poses for both spatial accuracy and physical consistency. Simulated experiments show that our approach reduces the intersection volume error between the object and robotic hand by 73\% when the initial estimate is accurate and by over 87\% under high initial uncertainty, significantly outperforming standard ICP-based baselines. Furthermore, the improvement in geometric plausibility is accompanied by a concurrent reduction in translation and orientation errors. Achieving pose estimation that is grounded in physical reality while remaining faithful to multi-modal sensor inputs is a critical step toward robust in-hand manipulation.
VisuoTactile 6D Pose Estimation of an In-Hand Object using Vision and Tactile Sensor Data
Jan 04, 2026Knowledge of the 6D pose of an object can benefit in-hand object manipulation. In-hand 6D object pose estimation is challenging because of heavy occlusion produced by the robot's grippers, which can have an adverse effect on methods that rely on vision data only. Many robots are equipped with tactile sensors at their fingertips that could be used to complement vision data. In this paper, we present a method that uses both tactile and vision data to estimate the pose of an object grasped in a robot's hand. To address challenges like lack of standard representation for tactile data and sensor fusion, we propose the use of point clouds to represent object surfaces in contact with the tactile sensor and present a network architecture based on pixel-wise dense fusion. We also extend NVIDIA's Deep Learning Dataset Synthesizer to produce synthetic photo-realistic vision data and corresponding tactile point clouds. Results suggest that using tactile data in addition to vision data improves the 6D pose estimate, and our network generalizes successfully from synthetic training to real physical robots.
* Accepted for publication in IEEE Robotics and Automation Letters (RA-L), January 2022. Presented at ICRA 2022. This is the author's version of the manuscript
Social Mediation through Robots -- A Scoping Review on Improving Group Interactions through Directed Robot Action using an Extended Group Process Model
Sep 10, 2024



Group processes refer to the dynamics that occur within a group and are critical for understanding how groups function. With robots being increasingly placed within small groups, improving these processes has emerged as an important application of social robotics. Social Mediation Robots elicit behavioral change within groups by deliberately influencing the processes of groups. While research in this field has demonstrated that robots can effectively affect interpersonal dynamics, there is a notable gap in integrating these insights to develop coherent understanding and theory. We present a scoping review of literature targeting changes in social interactions between multiple humans through intentional action from robotic agents. To guide our review, we adapt the classical Input-Process-Output (I-P-O) models that we call "Mediation I-P-O model". We evaluated 1633 publications, which yielded 89 distinct social mediation concepts. We construct 11 mediation approaches robots can use to shape processes in small groups and teams. This work strives to produce generalizable insights and evaluate the extent to which the potential of social mediation through robots has been realized thus far. We hope that the proposed framework encourages a holistic approach to the study of social mediation and provides a foundation to standardize future reporting in the domain.
HyperTaxel: Hyper-Resolution for Taxel-Based Tactile Signals Through Contrastive Learning
Aug 15, 2024

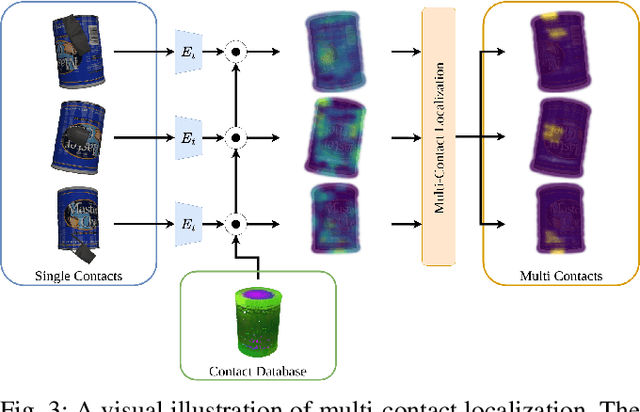

To achieve dexterity comparable to that of humans, robots must intelligently process tactile sensor data. Taxel-based tactile signals often have low spatial-resolution, with non-standardized representations. In this paper, we propose a novel framework, HyperTaxel, for learning a geometrically-informed representation of taxel-based tactile signals to address challenges associated with their spatial resolution. We use this representation and a contrastive learning objective to encode and map sparse low-resolution taxel signals to high-resolution contact surfaces. To address the uncertainty inherent in these signals, we leverage joint probability distributions across multiple simultaneous contacts to improve taxel hyper-resolution. We evaluate our representation by comparing it with two baselines and present results that suggest our representation outperforms the baselines. Furthermore, we present qualitative results that demonstrate the learned representation captures the geometric features of the contact surface, such as flatness, curvature, and edges, and generalizes across different objects and sensor configurations. Moreover, we present results that suggest our representation improves the performance of various downstream tasks, such as surface classification, 6D in-hand pose estimation, and sim-to-real transfer.
ViHOPE: Visuotactile In-Hand Object 6D Pose Estimation with Shape Completion
Sep 11, 2023

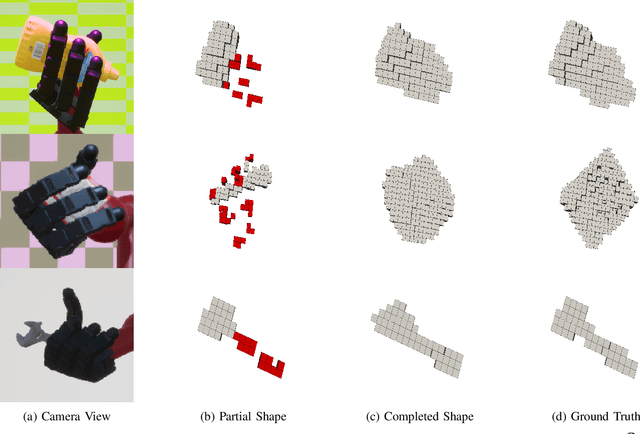

In this letter, we introduce ViHOPE, a novel framework for estimating the 6D pose of an in-hand object using visuotactile perception. Our key insight is that the accuracy of the 6D object pose estimate can be improved by explicitly completing the shape of the object. To this end, we introduce a novel visuotactile shape completion module that uses a conditional Generative Adversarial Network to complete the shape of an in-hand object based on volumetric representation. This approach improves over prior works that directly regress visuotactile observations to a 6D pose. By explicitly completing the shape of the in-hand object and jointly optimizing the shape completion and pose estimation tasks, we improve the accuracy of the 6D object pose estimate. We train and test our model on a synthetic dataset and compare it with the state-of-the-art. In the visuotactile shape completion task, we outperform the state-of-the-art by 265% using the Intersection of Union metric and achieve 88% lower Chamfer Distance. In the visuotactile pose estimation task, we present results that suggest our framework reduces position and angular errors by 35% and 64%, respectively. Furthermore, we ablate our framework to confirm the gain on the 6D object pose estimate from explicitly completing the shape. Ultimately, we show that our framework produces models that are robust to sim-to-real transfer on a real-world robot platform.
"How Did They Come Across?" Lessons Learned from Continuous Affective Ratings
Jul 07, 2023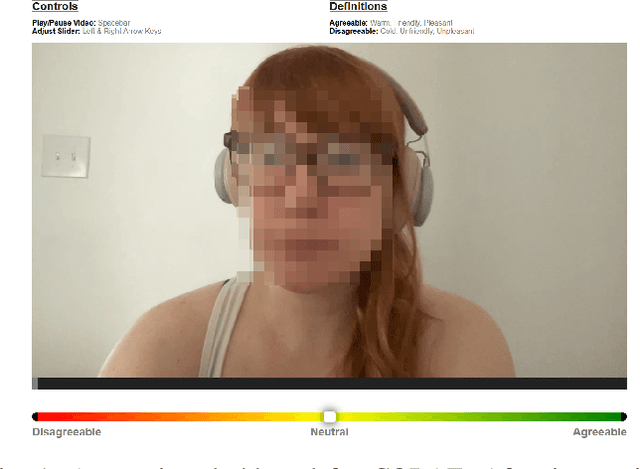
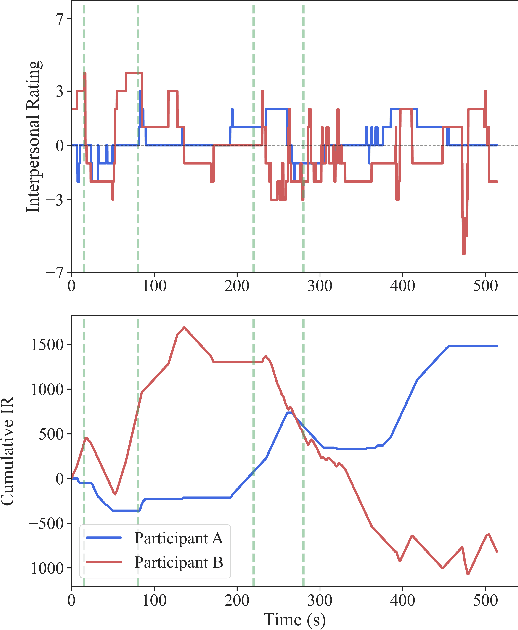

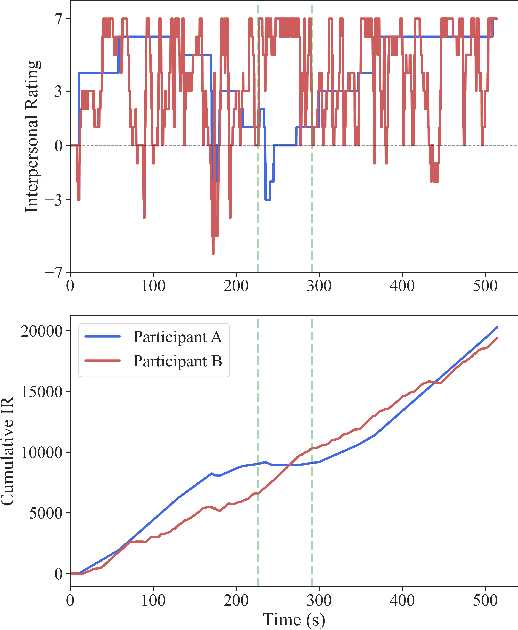
Social distance, or perception of the other, is recognized as a dynamic dimension of an interaction, but yet to be widely explored or understood. Through CORAE, a novel web-based open-source tool for COntinuous Retrospective Affect Evaluation, we collected retrospective ratings of interpersonal perceptions between 12 participant dyads. In this work, we explore how different aspects of these interactions reflect on the ratings collected, through a discourse analysis of individual and social behavior of the interactants. We found that different events observed in the ratings can be mapped to complex interaction phenomena, shedding light on relevant interaction features that may play a role in interpersonal understanding and grounding. This paves the way for better, more seamless human-robot interactions, where affect is interpreted as highly dynamic and contingent on interaction history.
* arXiv admin note: substantial text overlap with arXiv:2306.16629
What Could a Social Mediator Robot Do? Lessons from Real-World Mediation Scenarios
Jun 30, 2023

The use of social robots as instruments for social mediation has been gaining traction in the field of Human-Robot Interaction (HRI). So far, the design of such robots and their behaviors is often driven by technological platforms and experimental setups in controlled laboratory environments. To address complex social relationships in the real world, it is crucial to consider the actual needs and consequences of the situations found therein. This includes understanding when a mediator is necessary, what specific role such a robot could play, and how it moderates human social dynamics. In this paper, we discuss six relevant roles for robotic mediators that we identified by investigating a collection of videos showing realistic group situations. We further discuss mediation behaviors and target measures to evaluate the success of such interventions. We hope that our findings can inspire future research on robot-assisted social mediation by highlighting a wider set of mediation applications than those found in prior studies. Specifically, we aim to inform the categorization and selection of interaction scenarios that reflect real situations, where a mediation robot can have a positive and meaningful impact on group dynamics.
Group Dynamics: Survey of Existing Multimodal Models and Considerations for Social Mediation
Jun 30, 2023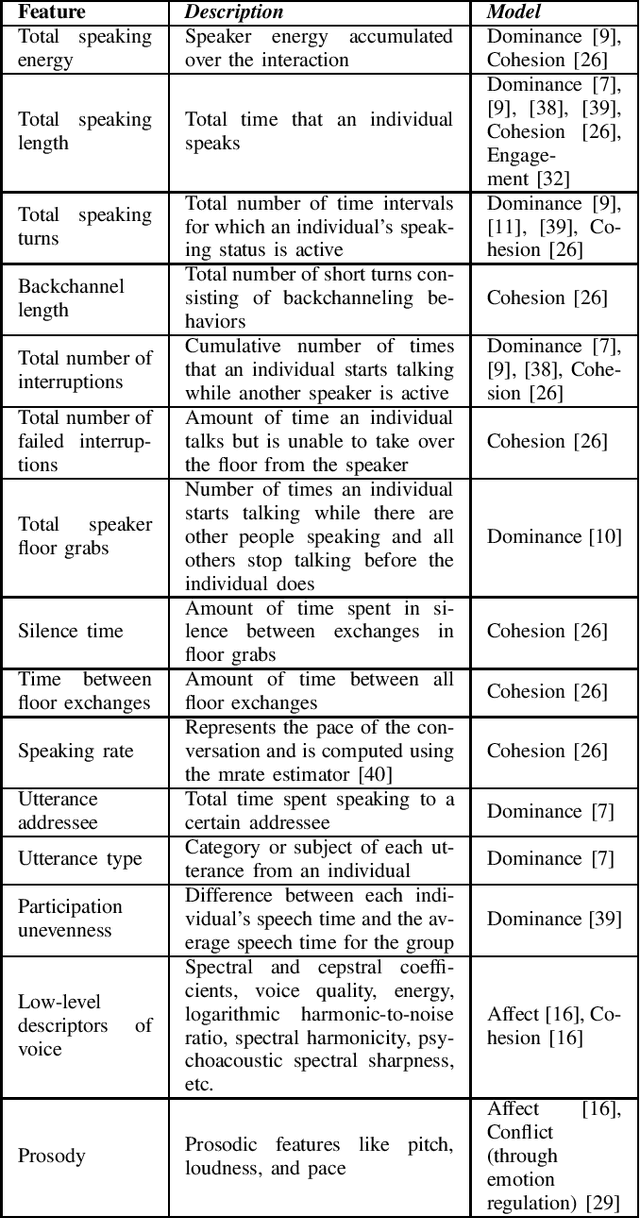
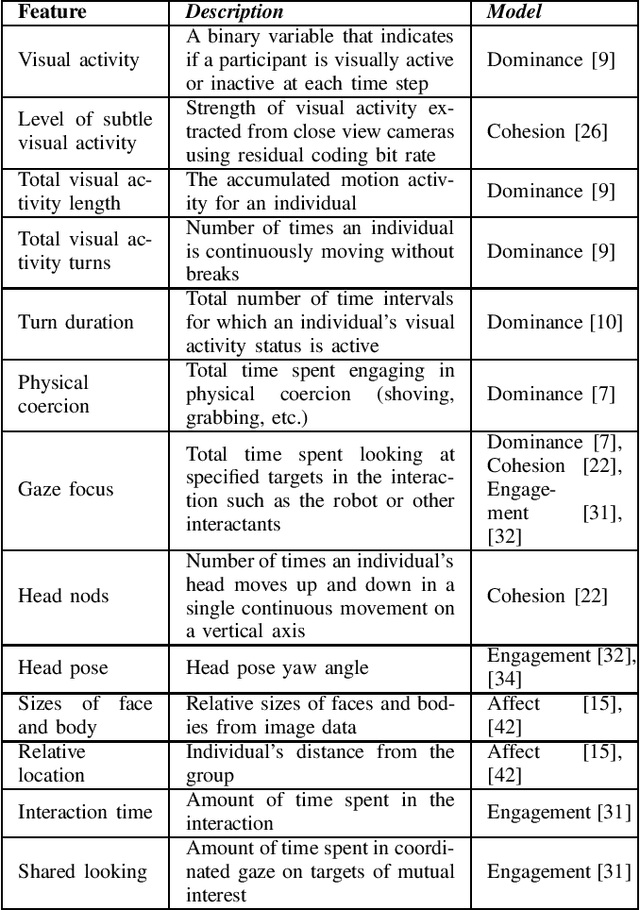

Social mediator robots facilitate human-human interactions by producing behavior strategies that positively influence how humans interact with each other in social settings. As robots for social mediation gain traction in the field of human-human-robot interaction, their ability to "understand" the humans in their environments becomes crucial. This objective requires models of human understanding that consider multiple humans in an interaction as a collective entity and represent the group dynamics that exist among its members. Group dynamics are defined as the influential actions, processes, and changes that occur within and between group interactants. Since an individual's behavior may be deeply influenced by their interactions with other group members, the social dynamics existing within a group can influence the behaviors, attitudes, and opinions of each individual and the group as a whole. Therefore, models of group dynamics are critical for a social mediator robot to be effective in its role. In this paper, we survey existing models of group dynamics and categorize them into models of social dominance, affect, social cohesion, conflict resolution, and engagement. We highlight the multimodal features these models utilize, and emphasize the importance of capturing the interpersonal aspects of a social interaction. Finally, we make a case for models of relational affect as an approach that may be able to capture a representation of human-human interactions that can be useful for social mediation.
Modeling Group Dynamics for Personalized Robot-Mediated Interactions
Jun 29, 2023The field of human-human-robot interaction (HHRI) uses social robots to positively influence how humans interact with each other. This objective requires models of human understanding that consider multiple humans in an interaction as a collective entity and represent the group dynamics that exist within it. Understanding group dynamics is important because these can influence the behaviors, attitudes, and opinions of each individual within the group, as well as the group as a whole. Such an understanding is also useful when personalizing an interaction between a robot and the humans in its environment, where a group-level model can facilitate the design of robot behaviors that are tailored to a given group, the dynamics that exist within it, and the specific needs and preferences of the individual interactants. In this paper, we highlight the need for group-level models of human understanding in human-human-robot interaction research and how these can be useful in developing personalization techniques. We survey existing models of group dynamics and categorize them into models of social dominance, affect, social cohesion, and conflict resolution. We highlight the important features these models utilize, evaluate their potential to capture interpersonal aspects of a social interaction, and highlight their value for personalization techniques. Finally, we identify directions for future work, and make a case for models of relational affect as an approach that can better capture group-level understanding of human-human interactions and be useful in personalizing human-human-robot interactions.
Hierarchical Graph Neural Networks for Proprioceptive 6D Pose Estimation of In-hand Objects
Jun 28, 2023



Robotic manipulation, in particular in-hand object manipulation, often requires an accurate estimate of the object's 6D pose. To improve the accuracy of the estimated pose, state-of-the-art approaches in 6D object pose estimation use observational data from one or more modalities, e.g., RGB images, depth, and tactile readings. However, existing approaches make limited use of the underlying geometric structure of the object captured by these modalities, thereby, increasing their reliance on visual features. This results in poor performance when presented with objects that lack such visual features or when visual features are simply occluded. Furthermore, current approaches do not take advantage of the proprioceptive information embedded in the position of the fingers. To address these limitations, in this paper: (1) we introduce a hierarchical graph neural network architecture for combining multimodal (vision and touch) data that allows for a geometrically informed 6D object pose estimation, (2) we introduce a hierarchical message passing operation that flows the information within and across modalities to learn a graph-based object representation, and (3) we introduce a method that accounts for the proprioceptive information for in-hand object representation. We evaluate our model on a diverse subset of objects from the YCB Object and Model Set, and show that our method substantially outperforms existing state-of-the-art work in accuracy and robustness to occlusion. We also deploy our proposed framework on a real robot and qualitatively demonstrate successful transfer to real settings.