 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometrically Plausible Object Pose Refinement using Differentiable Simulation
Mar 22, 2026State-of-the-art object pose estimation methods are prone to generating geometrically infeasible pose hypotheses. This problem is prevalent in dexterous manipulation, where estimated poses often intersect with the robotic hand or are not lying on a support surface. We propose a multi-modal pose refinement approach that combines differentiable physics simulation, differentiable rendering and visuo-tactile sensing to optimize object poses for both spatial accuracy and physical consistency. Simulated experiments show that our approach reduces the intersection volume error between the object and robotic hand by 73\% when the initial estimate is accurate and by over 87\% under high initial uncertainty, significantly outperforming standard ICP-based baselines. Furthermore, the improvement in geometric plausibility is accompanied by a concurrent reduction in translation and orientation errors. Achieving pose estimation that is grounded in physical reality while remaining faithful to multi-modal sensor inputs is a critical step toward robust in-hand manipulation.
HyperTaxel: Hyper-Resolution for Taxel-Based Tactile Signals Through Contrastive Learning
Aug 15, 2024

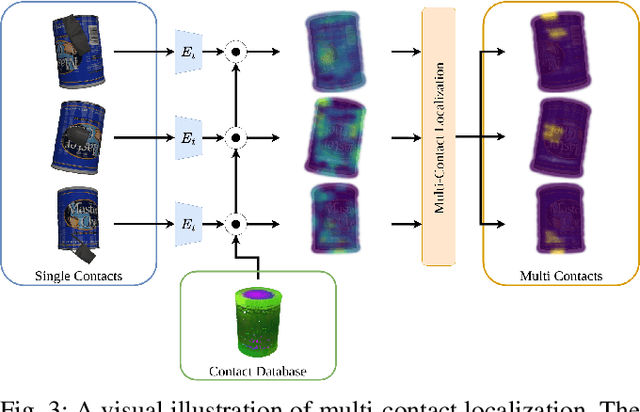

To achieve dexterity comparable to that of humans, robots must intelligently process tactile sensor data. Taxel-based tactile signals often have low spatial-resolution, with non-standardized representations. In this paper, we propose a novel framework, HyperTaxel, for learning a geometrically-informed representation of taxel-based tactile signals to address challenges associated with their spatial resolution. We use this representation and a contrastive learning objective to encode and map sparse low-resolution taxel signals to high-resolution contact surfaces. To address the uncertainty inherent in these signals, we leverage joint probability distributions across multiple simultaneous contacts to improve taxel hyper-resolution. We evaluate our representation by comparing it with two baselines and present results that suggest our representation outperforms the baselines. Furthermore, we present qualitative results that demonstrate the learned representation captures the geometric features of the contact surface, such as flatness, curvature, and edges, and generalizes across different objects and sensor configurations. Moreover, we present results that suggest our representation improves the performance of various downstream tasks, such as surface classification, 6D in-hand pose estimation, and sim-to-real transfer.
ViHOPE: Visuotactile In-Hand Object 6D Pose Estimation with Shape Completion
Sep 11, 2023

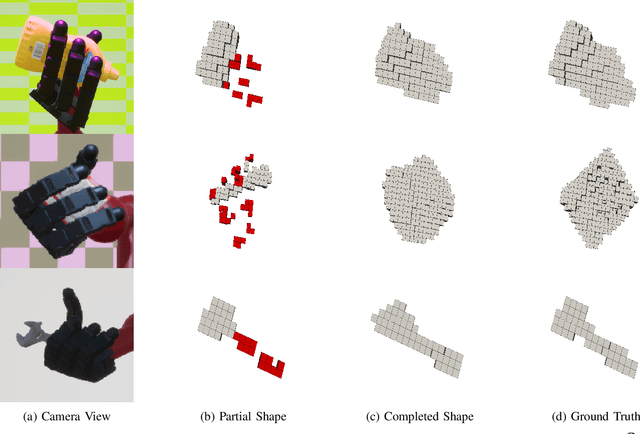

In this letter, we introduce ViHOPE, a novel framework for estimating the 6D pose of an in-hand object using visuotactile perception. Our key insight is that the accuracy of the 6D object pose estimate can be improved by explicitly completing the shape of the object. To this end, we introduce a novel visuotactile shape completion module that uses a conditional Generative Adversarial Network to complete the shape of an in-hand object based on volumetric representation. This approach improves over prior works that directly regress visuotactile observations to a 6D pose. By explicitly completing the shape of the in-hand object and jointly optimizing the shape completion and pose estimation tasks, we improve the accuracy of the 6D object pose estimate. We train and test our model on a synthetic dataset and compare it with the state-of-the-art. In the visuotactile shape completion task, we outperform the state-of-the-art by 265% using the Intersection of Union metric and achieve 88% lower Chamfer Distance. In the visuotactile pose estimation task, we present results that suggest our framework reduces position and angular errors by 35% and 64%, respectively. Furthermore, we ablate our framework to confirm the gain on the 6D object pose estimate from explicitly completing the shape. Ultimately, we show that our framework produces models that are robust to sim-to-real transfer on a real-world robot platform.
Hierarchical Graph Neural Networks for Proprioceptive 6D Pose Estimation of In-hand Objects
Jun 28, 2023



Robotic manipulation, in particular in-hand object manipulation, often requires an accurate estimate of the object's 6D pose. To improve the accuracy of the estimated pose, state-of-the-art approaches in 6D object pose estimation use observational data from one or more modalities, e.g., RGB images, depth, and tactile readings. However, existing approaches make limited use of the underlying geometric structure of the object captured by these modalities, thereby, increasing their reliance on visual features. This results in poor performance when presented with objects that lack such visual features or when visual features are simply occluded. Furthermore, current approaches do not take advantage of the proprioceptive information embedded in the position of the fingers. To address these limitations, in this paper: (1) we introduce a hierarchical graph neural network architecture for combining multimodal (vision and touch) data that allows for a geometrically informed 6D object pose estimation, (2) we introduce a hierarchical message passing operation that flows the information within and across modalities to learn a graph-based object representation, and (3) we introduce a method that accounts for the proprioceptive information for in-hand object representation. We evaluate our model on a diverse subset of objects from the YCB Object and Model Set, and show that our method substantially outperforms existing state-of-the-art work in accuracy and robustness to occlusion. We also deploy our proposed framework on a real robot and qualitatively demonstrate successful transfer to real settings.