 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSVD-NO: Learning PDE Solution Operators with SVD Integral Kernels
Nov 13, 2025Neural operators have emerged as a promising paradigm for learning solution operators of partial differential equa- tions (PDEs) directly from data. Existing methods, such as those based on Fourier or graph techniques, make strong as- sumptions about the structure of the kernel integral opera- tor, assumptions which may limit expressivity. We present SVD-NO, a neural operator that explicitly parameterizes the kernel by its singular-value decomposition (SVD) and then carries out the integral directly in the low-rank basis. Two lightweight networks learn the left and right singular func- tions, a diagonal parameter matrix learns the singular values, and a Gram-matrix regularizer enforces orthonormality. As SVD-NO approximates the full kernel, it obtains a high de- gree of expressivity. Furthermore, due to its low-rank struc- ture the computational complexity of applying the operator remains reasonable, leading to a practical system. In exten- sive evaluations on five diverse benchmark equations, SVD- NO achieves a new state of the art. In particular, SVD-NO provides greater performance gains on PDEs whose solutions are highly spatially variable. The code of this work is publicly available at https://github.com/2noamk/SVDNO.git.
ReHub: Linear Complexity Graph Transformers with Adaptive Hub-Spoke Reassignment
Dec 02, 2024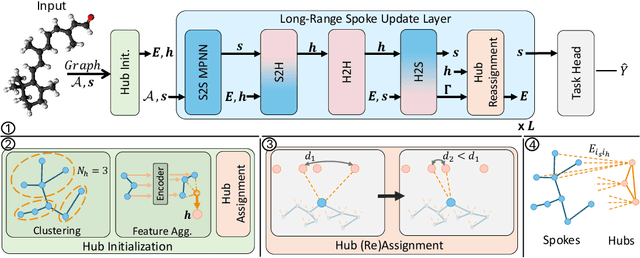
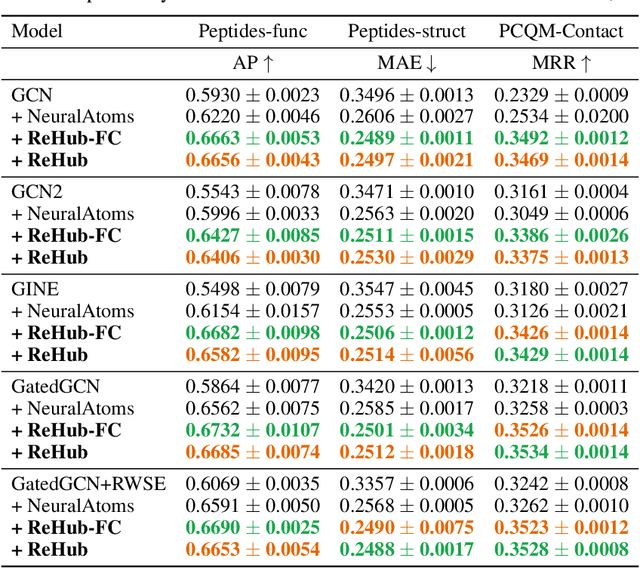
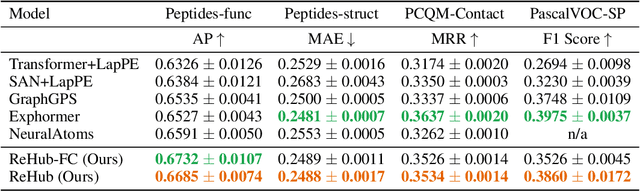
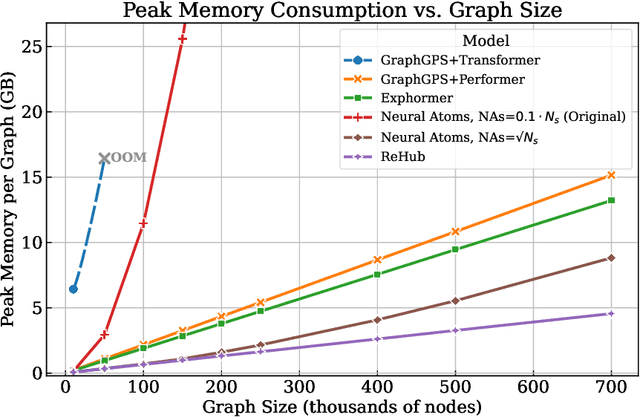
We present ReHub, a novel graph transformer architecture that achieves linear complexity through an efficient reassignment technique between nodes and virtual nodes. Graph transformers have become increasingly important in graph learning for their ability to utilize long-range node communication explicitly, addressing limitations such as oversmoothing and oversquashing found in message-passing graph networks. However, their dense attention mechanism scales quadratically with the number of nodes, limiting their applicability to large-scale graphs. ReHub draws inspiration from the airline industry's hub-and-spoke model, where flights are assigned to optimize operational efficiency. In our approach, graph nodes (spokes) are dynamically reassigned to a fixed number of virtual nodes (hubs) at each model layer. Recent work, Neural Atoms (Li et al., 2024), has demonstrated impressive and consistent improvements over GNN baselines by utilizing such virtual nodes; their findings suggest that the number of hubs strongly influences performance. However, increasing the number of hubs typically raises complexity, requiring a trade-off to maintain linear complexity. Our key insight is that each node only needs to interact with a small subset of hubs to achieve linear complexity, even when the total number of hubs is large. To leverage all hubs without incurring additional computational costs, we propose a simple yet effective adaptive reassignment technique based on hub-hub similarity scores, eliminating the need for expensive node-hub computations. Our experiments on LRGB indicate a consistent improvement in results over the base method, Neural Atoms, while maintaining a linear complexity. Remarkably, our sparse model achieves performance on par with its non-sparse counterpart. Furthermore, ReHub outperforms competitive baselines and consistently ranks among top performers across various benchmarks.
Streamlining Conformal Information Retrieval via Score Refinement
Oct 03, 2024
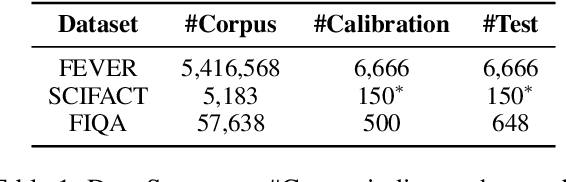
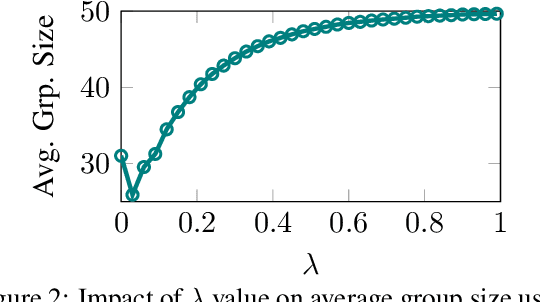
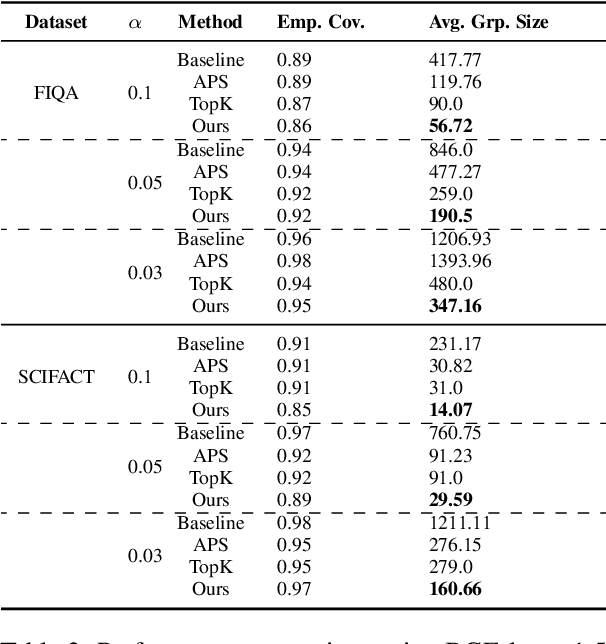
Information retrieval (IR) methods, like retrieval augmented generation, are fundamental to modern applications but often lack statistical guarantees. Conformal prediction addresses this by retrieving sets guaranteed to include relevant information, yet existing approaches produce large-sized sets, incurring high computational costs and slow response times. In this work, we introduce a score refinement method that applies a simple monotone transformation to retrieval scores, leading to significantly smaller conformal sets while maintaining their statistical guarantees. Experiments on various BEIR benchmarks validate the effectiveness of our approach in producing compact sets containing relevant information.
Molecular Diffusion Models with Virtual Receptors
Jun 26, 2024


Machine learning approaches to Structure-Based Drug Design (SBDD) have proven quite fertile over the last few years. In particular, diffusion-based approaches to SBDD have shown great promise. We present a technique which expands on this diffusion approach in two crucial ways. First, we address the size disparity between the drug molecule and the target/receptor, which makes learning more challenging and inference slower. We do so through the notion of a Virtual Receptor, which is a compressed version of the receptor; it is learned so as to preserve key aspects of the structural information of the original receptor, while respecting the relevant group equivariance. Second, we incorporate a protein language embedding used originally in the context of protein folding. We experimentally demonstrate the contributions of both the virtual receptors and the protein embeddings: in practice, they lead to both better performance, as well as significantly faster computations.
A Theoretical Framework for an Efficient Normalizing Flow-Based Solution to the Schrodinger Equation
May 28, 2024A central problem in quantum mechanics involves solving the Electronic Schrodinger Equation for a molecule or material. The Variational Monte Carlo approach to this problem approximates a particular variational objective via sampling, and then optimizes this approximated objective over a chosen parameterized family of wavefunctions, known as the ansatz. Recently neural networks have been used as the ansatz, with accompanying success. However, sampling from such wavefunctions has required the use of a Markov Chain Monte Carlo approach, which is inherently inefficient. In this work, we propose a solution to this problem via an ansatz which is cheap to sample from, yet satisfies the requisite quantum mechanical properties. We prove that a normalizing flow using the following two essential ingredients satisfies our requirements: (a) a base distribution which is constructed from Determinantal Point Processes; (b) flow layers which are equivariant to a particular subgroup of the permutation group. We then show how to construct both continuous and discrete normalizing flows which satisfy the requisite equivariance. We further demonstrate the manner in which the non-smooth nature ("cusps") of the wavefunction may be captured, and how the framework may be generalized to provide induction across multiple molecules. The resulting theoretical framework entails an efficient approach to solving the Electronic Schrodinger Equation.
Looks Too Good To Be True: An Information-Theoretic Analysis of Hallucinations in Generative Restoration Models
May 26, 2024



The pursuit of high perceptual quality in image restoration has driven the development of revolutionary generative models, capable of producing results often visually indistinguishable from real data. However, as their perceptual quality continues to improve, these models also exhibit a growing tendency to generate hallucinations - realistic-looking details that do not exist in the ground truth images. The presence of hallucinations introduces uncertainty regarding the reliability of the models' predictions, raising major concerns about their practical application. In this paper, we employ information-theory tools to investigate this phenomenon, revealing a fundamental tradeoff between uncertainty and perception. We rigorously analyze the relationship between these two factors, proving that the global minimal uncertainty in generative models grows in tandem with perception. In particular, we define the inherent uncertainty of the restoration problem and show that attaining perfect perceptual quality entails at least twice this uncertainty. Additionally, we establish a relation between mean squared-error distortion, uncertainty and perception, through which we prove the aforementioned uncertainly-perception tradeoff induces the well-known perception-distortion tradeoff. This work uncovers fundamental limitations of generative models in achieving both high perceptual quality and reliable predictions for image restoration. We demonstrate our theoretical findings through an analysis of single image super-resolution algorithms. Our work aims to raise awareness among practitioners about this inherent tradeoff, empowering them to make informed decisions and potentially prioritize safety over perceptual performance.
On the Semantic Latent Space of Diffusion-Based Text-to-Speech Models
Feb 19, 2024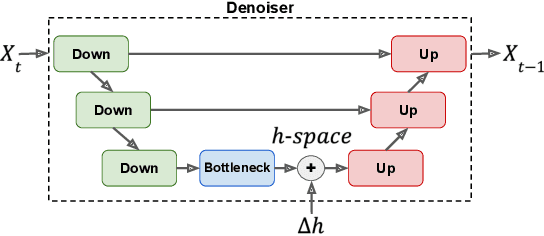

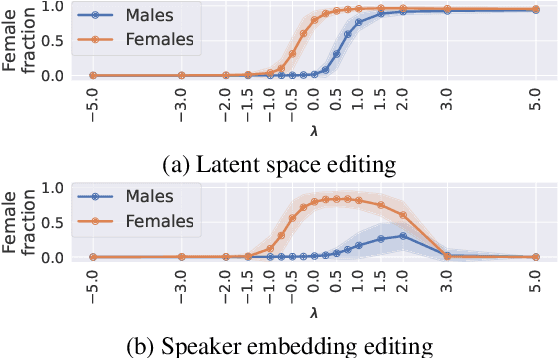

The incorporation of Denoising Diffusion Models (DDMs) in the Text-to-Speech (TTS) domain is rising, providing great value in synthesizing high quality speech. Although they exhibit impressive audio quality, the extent of their semantic capabilities is unknown, and controlling their synthesized speech's vocal properties remains a challenge. Inspired by recent advances in image synthesis, we explore the latent space of frozen TTS models, which is composed of the latent bottleneck activations of the DDM's denoiser. We identify that this space contains rich semantic information, and outline several novel methods for finding semantic directions within it, both supervised and unsupervised. We then demonstrate how these enable off-the-shelf audio editing, without any further training, architectural changes or data requirements. We present evidence of the semantic and acoustic qualities of the edited audio, and provide supplemental samples: https://latent-analysis-grad-tts.github.io/speech-samples/.
Overcoming Order in Autoregressive Graph Generation
Feb 04, 2024



Graph generation is a fundamental problem in various domains, including chemistry and social networks. Recent work has shown that molecular graph generation using recurrent neural networks (RNNs) is advantageous compared to traditional generative approaches which require converting continuous latent representations into graphs. One issue which arises when treating graph generation as sequential generation is the arbitrary order of the sequence which results from a particular choice of graph flattening method. In this work we propose using RNNs, taking into account the non-sequential nature of graphs by adding an Orderless Regularization (OLR) term that encourages the hidden state of the recurrent model to be invariant to different valid orderings present under the training distribution. We demonstrate that sequential graph generation models benefit from our proposed regularization scheme, especially when data is scarce. Our findings contribute to the growing body of research on graph generation and provide a valuable tool for various applications requiring the synthesis of realistic and diverse graph structures.
Early Time Classification with Accumulated Accuracy Gap Control
Feb 01, 2024
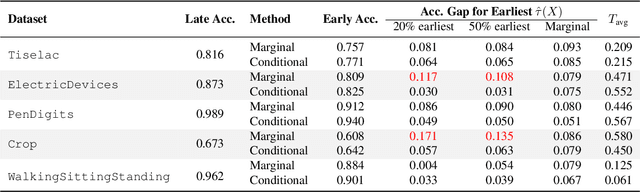
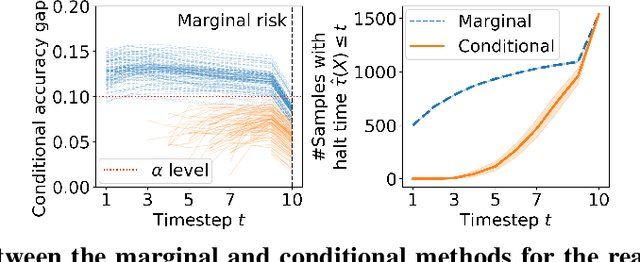
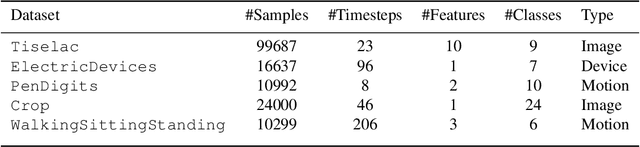
Early time classification algorithms aim to label a stream of features without processing the full input stream, while maintaining accuracy comparable to that achieved by applying the classifier to the entire input. In this paper, we introduce a statistical framework that can be applied to any sequential classifier, formulating a calibrated stopping rule. This data-driven rule attains finite-sample, distribution-free control of the accuracy gap between full and early-time classification. We start by presenting a novel method that builds on the Learn-then-Test calibration framework to control this gap marginally, on average over i.i.d. instances. As this algorithm tends to yield an excessively high accuracy gap for early halt times, our main contribution is the proposal of a framework that controls a stronger notion of error, where the accuracy gap is controlled conditionally on the accumulated halt times. Numerical experiments demonstrate the effectiveness, applicability, and usefulness of our method. We show that our proposed early stopping mechanism reduces up to 94% of timesteps used for classification while achieving rigorous accuracy gap control.
Weakly-Supervised Surgical Phase Recognition
Oct 26, 2023


A key element of computer-assisted surgery systems is phase recognition of surgical videos. Existing phase recognition algorithms require frame-wise annotation of a large number of videos, which is time and money consuming. In this work we join concepts of graph segmentation with self-supervised learning to derive a random-walk solution for per-frame phase prediction. Furthermore, we utilize within our method two forms of weak supervision: sparse timestamps or few-shot learning. The proposed algorithm enjoys low complexity and can operate in lowdata regimes. We validate our method by running experiments with the public Cholec80 dataset of laparoscopic cholecystectomy videos, demonstrating promising performance in multiple setups.