 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCapabilities of Gemini Models in Medicine
May 01, 2024



Excellence in a wide variety of medical applications poses considerable challenges for AI, requiring advanced reasoning, access to up-to-date medical knowledge and understanding of complex multimodal data. Gemini models, with strong general capabilities in multimodal and long-context reasoning, offer exciting possibilities in medicine. Building on these core strengths of Gemini, we introduce Med-Gemini, a family of highly capable multimodal models that are specialized in medicine with the ability to seamlessly use web search, and that can be efficiently tailored to novel modalities using custom encoders. We evaluate Med-Gemini on 14 medical benchmarks, establishing new state-of-the-art (SoTA) performance on 10 of them, and surpass the GPT-4 model family on every benchmark where a direct comparison is viable, often by a wide margin. On the popular MedQA (USMLE) benchmark, our best-performing Med-Gemini model achieves SoTA performance of 91.1% accuracy, using a novel uncertainty-guided search strategy. On 7 multimodal benchmarks including NEJM Image Challenges and MMMU (health & medicine), Med-Gemini improves over GPT-4V by an average relative margin of 44.5%. We demonstrate the effectiveness of Med-Gemini's long-context capabilities through SoTA performance on a needle-in-a-haystack retrieval task from long de-identified health records and medical video question answering, surpassing prior bespoke methods using only in-context learning. Finally, Med-Gemini's performance suggests real-world utility by surpassing human experts on tasks such as medical text summarization, alongside demonstrations of promising potential for multimodal medical dialogue, medical research and education. Taken together, our results offer compelling evidence for Med-Gemini's potential, although further rigorous evaluation will be crucial before real-world deployment in this safety-critical domain.
On the Semantic Latent Space of Diffusion-Based Text-to-Speech Models
Feb 19, 2024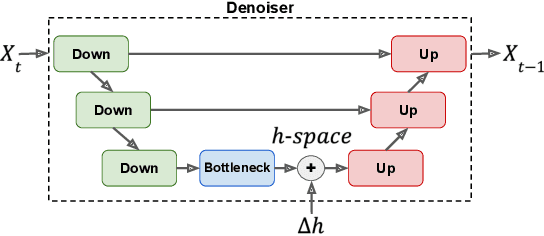

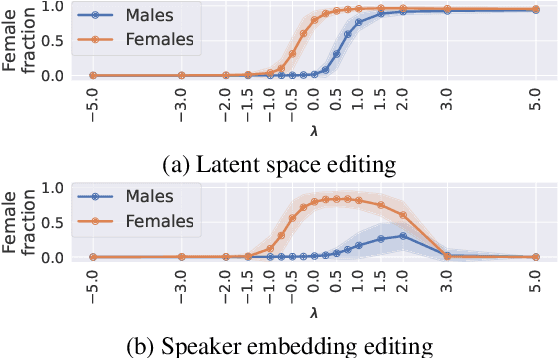

The incorporation of Denoising Diffusion Models (DDMs) in the Text-to-Speech (TTS) domain is rising, providing great value in synthesizing high quality speech. Although they exhibit impressive audio quality, the extent of their semantic capabilities is unknown, and controlling their synthesized speech's vocal properties remains a challenge. Inspired by recent advances in image synthesis, we explore the latent space of frozen TTS models, which is composed of the latent bottleneck activations of the DDM's denoiser. We identify that this space contains rich semantic information, and outline several novel methods for finding semantic directions within it, both supervised and unsupervised. We then demonstrate how these enable off-the-shelf audio editing, without any further training, architectural changes or data requirements. We present evidence of the semantic and acoustic qualities of the edited audio, and provide supplemental samples: https://latent-analysis-grad-tts.github.io/speech-samples/.
Weakly-Supervised Surgical Phase Recognition
Oct 26, 2023


A key element of computer-assisted surgery systems is phase recognition of surgical videos. Existing phase recognition algorithms require frame-wise annotation of a large number of videos, which is time and money consuming. In this work we join concepts of graph segmentation with self-supervised learning to derive a random-walk solution for per-frame phase prediction. Furthermore, we utilize within our method two forms of weak supervision: sparse timestamps or few-shot learning. The proposed algorithm enjoys low complexity and can operate in lowdata regimes. We validate our method by running experiments with the public Cholec80 dataset of laparoscopic cholecystectomy videos, demonstrating promising performance in multiple setups.
Self-Supervised Learning for Endoscopic Video Analysis
Aug 23, 2023Self-supervised learning (SSL) has led to important breakthroughs in computer vision by allowing learning from large amounts of unlabeled data. As such, it might have a pivotal role to play in biomedicine where annotating data requires a highly specialized expertise. Yet, there are many healthcare domains for which SSL has not been extensively explored. One such domain is endoscopy, minimally invasive procedures which are commonly used to detect and treat infections, chronic inflammatory diseases or cancer. In this work, we study the use of a leading SSL framework, namely Masked Siamese Networks (MSNs), for endoscopic video analysis such as colonoscopy and laparoscopy. To fully exploit the power of SSL, we create sizable unlabeled endoscopic video datasets for training MSNs. These strong image representations serve as a foundation for secondary training with limited annotated datasets, resulting in state-of-the-art performance in endoscopic benchmarks like surgical phase recognition during laparoscopy and colonoscopic polyp characterization. Additionally, we achieve a 50% reduction in annotated data size without sacrificing performance. Thus, our work provides evidence that SSL can dramatically reduce the need of annotated data in endoscopy.
SimGANs: Simulator-Based Generative Adversarial Networks for ECG Synthesis to Improve Deep ECG Classification
Jun 27, 2020



Generating training examples for supervised tasks is a long sought after goal in AI. We study the problem of heart signal electrocardiogram (ECG) synthesis for improved heartbeat classification. ECG synthesis is challenging: the generation of training examples for such biological-physiological systems is not straightforward, due to their dynamic nature in which the various parts of the system interact in complex ways. However, an understanding of these dynamics has been developed for years in the form of mathematical process simulators. We study how to incorporate this knowledge into the generative process by leveraging a biological simulator for the task of ECG classification. Specifically, we use a system of ordinary differential equations representing heart dynamics, and incorporate this ODE system into the optimization process of a generative adversarial network to create biologically plausible ECG training examples. We perform empirical evaluation and show that heart simulation knowledge during the generation process improves ECG classification.
Detecting Deficient Coverage in Colonoscopies
Jan 26, 2020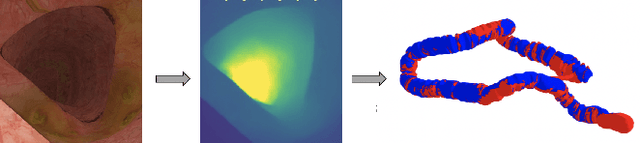
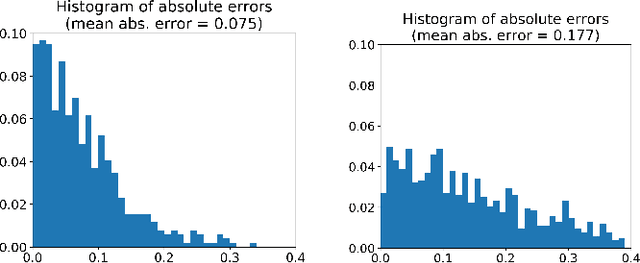
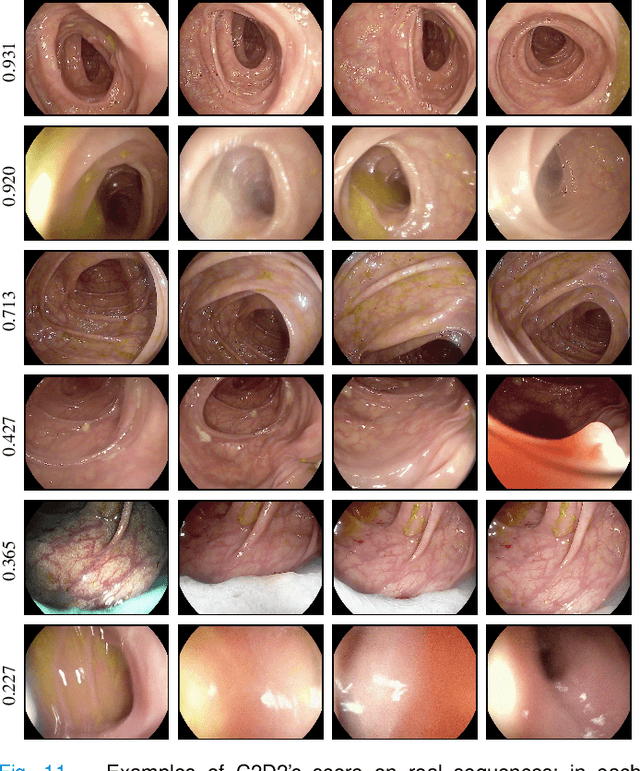
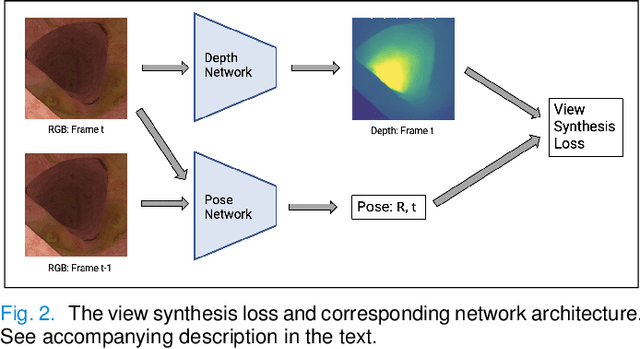
Colorectal Cancer (CRC) is a global health problem, resulting in 900K deaths per year. Colonoscopy is the tool of choice for preventing CRC, by detecting polyps before they become cancerous, and removing them. However, colonoscopy is hampered by the fact that endoscopists routinely miss an average of 22-28% of polyps. While some of these missed polyps appear in the endoscopist's field of view, others are missed simply because of substandard coverage of the procedure, i.e. not all of the colon is seen. This paper attempts to rectify the problem of substandard coverage in colonoscopy through the introduction of the C2D2 (Colonoscopy Coverage Deficiency via Depth) algorithm which detects deficient coverage, and can thereby alert the endoscopist to revisit a given area. More specifically, C2D2 consists of two separate algorithms: the first performs depth estimation of the colon given an ordinary RGB video stream; while the second computes coverage given these depth estimates. Rather than compute coverage for the entire colon, our algorithm computes coverage locally, on a segment-by-segment basis; C2D2 can then indicate in real-time whether a particular area of the colon has suffered from deficient coverage, and if so the endoscopist can return to that area. Our coverage algorithm is the first such algorithm to be evaluated in a large-scale way; while our depth estimation technique is the first calibration-free unsupervised method applied to colonoscopies. The C2D2 algorithm achieves state of the art results in the detection of deficient coverage: it is 2.4 times more accurate than human experts.