 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoPhy-2: A Challenging Action-Centric Physical Commonsense Evaluation in Video Generation
Mar 09, 2025Large-scale video generative models, capable of creating realistic videos of diverse visual concepts, are strong candidates for general-purpose physical world simulators. However, their adherence to physical commonsense across real-world actions remains unclear (e.g., playing tennis, backflip). Existing benchmarks suffer from limitations such as limited size, lack of human evaluation, sim-to-real gaps, and absence of fine-grained physical rule analysis. To address this, we introduce VideoPhy-2, an action-centric dataset for evaluating physical commonsense in generated videos. We curate 200 diverse actions and detailed prompts for video synthesis from modern generative models. We perform human evaluation that assesses semantic adherence, physical commonsense, and grounding of physical rules in the generated videos. Our findings reveal major shortcomings, with even the best model achieving only 22% joint performance (i.e., high semantic and physical commonsense adherence) on the hard subset of VideoPhy-2. We find that the models particularly struggle with conservation laws like mass and momentum. Finally, we also train VideoPhy-AutoEval, an automatic evaluator for fast, reliable assessment on our dataset. Overall, VideoPhy-2 serves as a rigorous benchmark, exposing critical gaps in video generative models and guiding future research in physically-grounded video generation. The data and code is available at https://videophy2.github.io/.
Streamlining Conformal Information Retrieval via Score Refinement
Oct 03, 2024
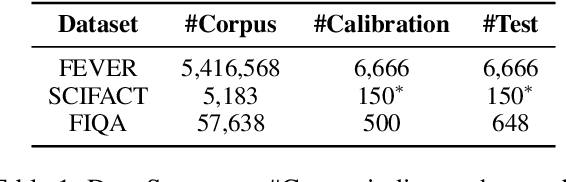
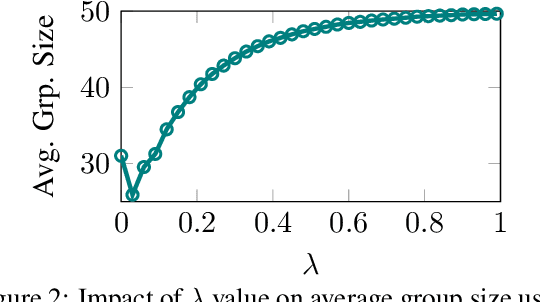
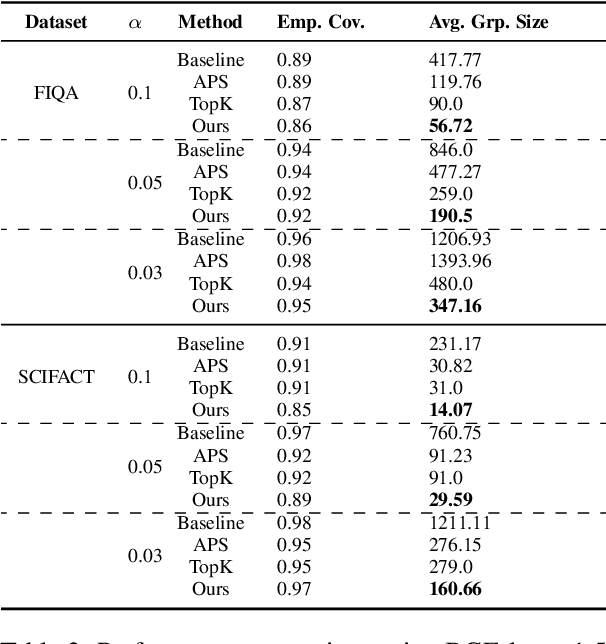
Information retrieval (IR) methods, like retrieval augmented generation, are fundamental to modern applications but often lack statistical guarantees. Conformal prediction addresses this by retrieving sets guaranteed to include relevant information, yet existing approaches produce large-sized sets, incurring high computational costs and slow response times. In this work, we introduce a score refinement method that applies a simple monotone transformation to retrieval scores, leading to significantly smaller conformal sets while maintaining their statistical guarantees. Experiments on various BEIR benchmarks validate the effectiveness of our approach in producing compact sets containing relevant information.
Predicting Generalization of AI Colonoscopy Models to Unseen Data
Mar 22, 2024



$\textbf{Background}$: Generalizability of AI colonoscopy algorithms is important for wider adoption in clinical practice. However, current techniques for evaluating performance on unseen data require expensive and time-intensive labels. $\textbf{Methods}$: We use a "Masked Siamese Network" (MSN) to identify novel phenomena in unseen data and predict polyp detector performance. MSN is trained to predict masked out regions of polyp images, without any labels. We test MSN's ability to be trained on data only from Israel and detect unseen techniques, narrow-band imaging (NBI) and chromendoscoy (CE), on colonoscopes from Japan (354 videos, 128 hours). We also test MSN's ability to predict performance of Computer Aided Detection (CADe) of polyps on colonoscopies from both countries, even though MSN is not trained on data from Japan. $\textbf{Results}$: MSN correctly identifies NBI and CE as less similar to Israel whitelight than Japan whitelight (bootstrapped z-test, |z| > 496, p < 10^-8 for both) using the label-free Frechet distance. MSN detects NBI with 99% accuracy, predicts CE better than our heuristic (90% vs 79% accuracy) despite being trained only on whitelight, and is the only method that is robust to noisy labels. MSN predicts CADe polyp detector performance on in-domain Israel and out-of-domain Japan colonoscopies (r=0.79, 0.37 respectively). With few examples of Japan detector performance to train on, MSN prediction of Japan performance improves (r=0.56). $\textbf{Conclusion}$: Our technique can identify distribution shifts in clinical data and can predict CADe detector performance on unseen data, without labels. Our self-supervised approach can aid in detecting when data in practice is different from training, such as between hospitals or data has meaningfully shifted from training. MSN has potential for application to medical image domains beyond colonoscopy.
Breaking the Language Barrier: Can Direct Inference Outperform Pre-Translation in Multilingual LLM Applications?
Mar 04, 2024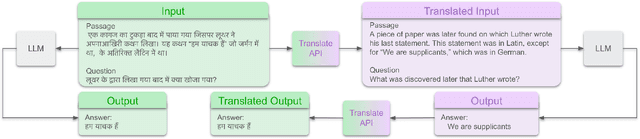
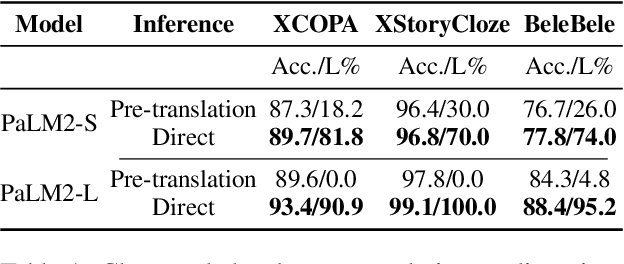

Large language models hold significant promise in multilingual applications. However, inherent biases stemming from predominantly English-centric pre-training have led to the widespread practice of pre-translation, i.e., translating non-English inputs to English before inference, leading to complexity and information loss. This study re-evaluates the need for pre-translation in the context of PaLM2 models (Anil et al., 2023), which have been established as highly performant in multilingual tasks. We offer a comprehensive investigation across 108 languages and 6 diverse benchmarks, including open-end generative tasks, which were excluded from previous similar studies. Our findings challenge the pre-translation paradigm established in prior research, highlighting the advantages of direct inference in PaLM2. Specifically, PaLM2-L consistently outperforms pre-translation in 94 out of 108 languages. These findings pave the way for more efficient and effective multilingual applications, alleviating the limitations associated with pre-translation and unlocking linguistic authenticity.
The unreasonable effectiveness of AI CADe polyp detectors to generalize to new countries
Dec 17, 2023$\textbf{Background and aims}$: Artificial Intelligence (AI) Computer-Aided Detection (CADe) is commonly used for polyp detection, but data seen in clinical settings can differ from model training. Few studies evaluate how well CADe detectors perform on colonoscopies from countries not seen during training, and none are able to evaluate performance without collecting expensive and time-intensive labels. $\textbf{Methods}$: We trained a CADe polyp detector on Israeli colonoscopy videos (5004 videos, 1106 hours) and evaluated on Japanese videos (354 videos, 128 hours) by measuring the True Positive Rate (TPR) versus false alarms per minute (FAPM). We introduce a colonoscopy dissimilarity measure called "MAsked mediCal Embedding Distance" (MACE) to quantify differences between colonoscopies, without labels. We evaluated CADe on all Japan videos and on those with the highest MACE. $\textbf{Results}$: MACE correctly quantifies that narrow-band imaging (NBI) and chromoendoscopy (CE) frames are less similar to Israel data than Japan whitelight (bootstrapped z-test, |z| > 690, p < $10^{-8}$ for both). Despite differences in the data, CADe performance on Japan colonoscopies was non-inferior to Israel ones without additional training (TPR at 0.5 FAPM: 0.957 and 0.972 for Israel and Japan; TPR at 1.0 FAPM: 0.972 and 0.989 for Israel and Japan; superiority test t > 45.2, p < $10^{-8}$). Despite not being trained on NBI or CE, TPR on those subsets were non-inferior to Japan overall (non-inferiority test t > 47.3, p < $10^{-8}$, $\delta$ = 1.5% for both). $\textbf{Conclusion}$: Differences that prevent CADe detectors from performing well in non-medical settings do not degrade the performance of our AI CADe polyp detector when applied to data from a new country. MACE can help medical AI models internationalize by identifying the most "dissimilar" data on which to evaluate models.
Self-Supervised Learning for Endoscopic Video Analysis
Aug 23, 2023Self-supervised learning (SSL) has led to important breakthroughs in computer vision by allowing learning from large amounts of unlabeled data. As such, it might have a pivotal role to play in biomedicine where annotating data requires a highly specialized expertise. Yet, there are many healthcare domains for which SSL has not been extensively explored. One such domain is endoscopy, minimally invasive procedures which are commonly used to detect and treat infections, chronic inflammatory diseases or cancer. In this work, we study the use of a leading SSL framework, namely Masked Siamese Networks (MSNs), for endoscopic video analysis such as colonoscopy and laparoscopy. To fully exploit the power of SSL, we create sizable unlabeled endoscopic video datasets for training MSNs. These strong image representations serve as a foundation for secondary training with limited annotated datasets, resulting in state-of-the-art performance in endoscopic benchmarks like surgical phase recognition during laparoscopy and colonoscopic polyp characterization. Additionally, we achieve a 50% reduction in annotated data size without sacrificing performance. Thus, our work provides evidence that SSL can dramatically reduce the need of annotated data in endoscopy.
Self-Supervised Polyp Re-Identification in Colonoscopy
Jun 14, 2023Computer-aided polyp detection (CADe) is becoming a standard, integral part of any modern colonoscopy system. A typical colonoscopy CADe detects a polyp in a single frame and does not track it through the video sequence. Yet, many downstream tasks including polyp characterization (CADx), quality metrics, automatic reporting, require aggregating polyp data from multiple frames. In this work we propose a robust long term polyp tracking method based on re-identification by visual appearance. Our solution uses an attention-based self-supervised ML model, specifically designed to leverage the temporal nature of video input. We quantitatively evaluate method's performance and demonstrate its value for the CADx task.
Semantic Parsing of Colonoscopy Videos with Multi-Label Temporal Networks
Jun 12, 2023Following the successful debut of polyp detection and characterization, more advanced automation tools are being developed for colonoscopy. The new automation tasks, such as quality metrics or report generation, require understanding of the procedure flow that includes activities, events, anatomical landmarks, etc. In this work we present a method for automatic semantic parsing of colonoscopy videos. The method uses a novel DL multi-label temporal segmentation model trained in supervised and unsupervised regimes. We evaluate the accuracy of the method on a test set of over 300 annotated colonoscopy videos, and use ablation to explore the relative importance of various method's components.
Semi-supervised Quality Evaluation of Colonoscopy Procedures
May 17, 2023Colonoscopy is the standard of care technique for detecting and removing polyps for the prevention of colorectal cancer. Nevertheless, gastroenterologists (GI) routinely miss approximately 25% of polyps during colonoscopies. These misses are highly operator dependent, influenced by the physician skills, experience, vigilance, and fatigue. Standard quality metrics, such as Withdrawal Time or Cecal Intubation Rate, have been shown to be well correlated with Adenoma Detection Rate (ADR). However, those metrics are limited in their ability to assess the quality of a specific procedure, and they do not address quality aspects related to the style or technique of the examination. In this work we design novel online and offline quality metrics, based on visual appearance quality criteria learned by an ML model in an unsupervised way. Furthermore, we evaluate the likelihood of detecting an existing polyp as a function of quality and use it to demonstrate high correlation of the proposed metric to polyp detection sensitivity. The proposed online quality metric can be used to provide real time quality feedback to the performing GI. By integrating the local metric over the withdrawal phase, we build a global, offline quality metric, which is shown to be highly correlated to the standard Polyp Per Colonoscopy (PPC) quality metric.
Clinical BERTScore: An Improved Measure of Automatic Speech Recognition Performance in Clinical Settings
Mar 13, 2023
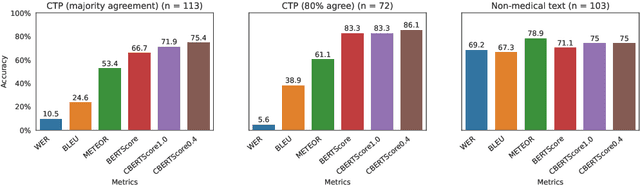
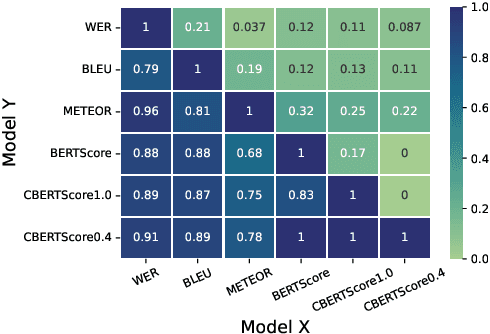
Automatic Speech Recognition (ASR) in medical contexts has the potential to save time, cut costs, increase report accuracy, and reduce physician burnout. However, the healthcare industry has been slower to adopt this technology, in part due to the importance of avoiding medically-relevant transcription mistakes. In this work, we present the Clinical BERTScore (CBERTScore), an ASR metric that penalizes clinically-relevant mistakes more than others. We demonstrate that this metric more closely aligns with clinician preferences on medical sentences as compared to other metrics (WER, BLUE, METEOR, etc), sometimes by wide margins. We collect a benchmark of 13 clinician preferences on 149 realistic medical sentences called the Clinician Transcript Preference benchmark (CTP), demonstrate that CBERTScore more closely matches what clinicians prefer, and release the benchmark for the community to further develop clinically-aware ASR metrics.