 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking the Language Barrier: Can Direct Inference Outperform Pre-Translation in Multilingual LLM Applications?
Mar 04, 2024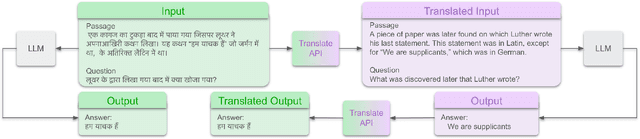
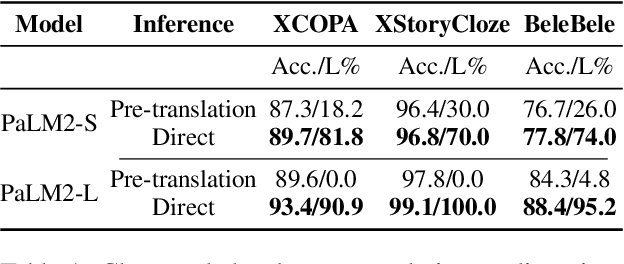

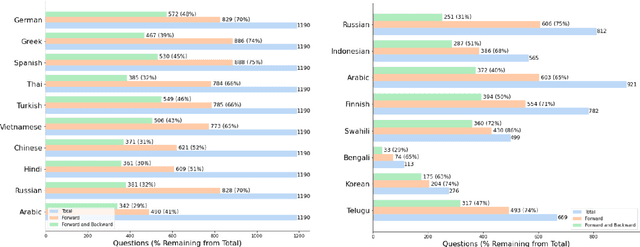
Large language models hold significant promise in multilingual applications. However, inherent biases stemming from predominantly English-centric pre-training have led to the widespread practice of pre-translation, i.e., translating non-English inputs to English before inference, leading to complexity and information loss. This study re-evaluates the need for pre-translation in the context of PaLM2 models (Anil et al., 2023), which have been established as highly performant in multilingual tasks. We offer a comprehensive investigation across 108 languages and 6 diverse benchmarks, including open-end generative tasks, which were excluded from previous similar studies. Our findings challenge the pre-translation paradigm established in prior research, highlighting the advantages of direct inference in PaLM2. Specifically, PaLM2-L consistently outperforms pre-translation in 94 out of 108 languages. These findings pave the way for more efficient and effective multilingual applications, alleviating the limitations associated with pre-translation and unlocking linguistic authenticity.