 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreamlining Conformal Information Retrieval via Score Refinement
Oct 03, 2024
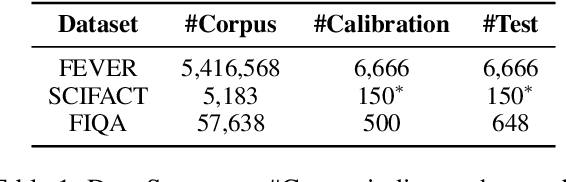
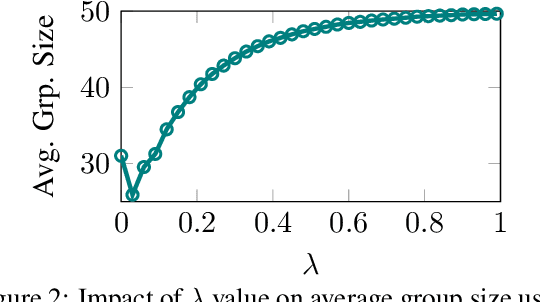
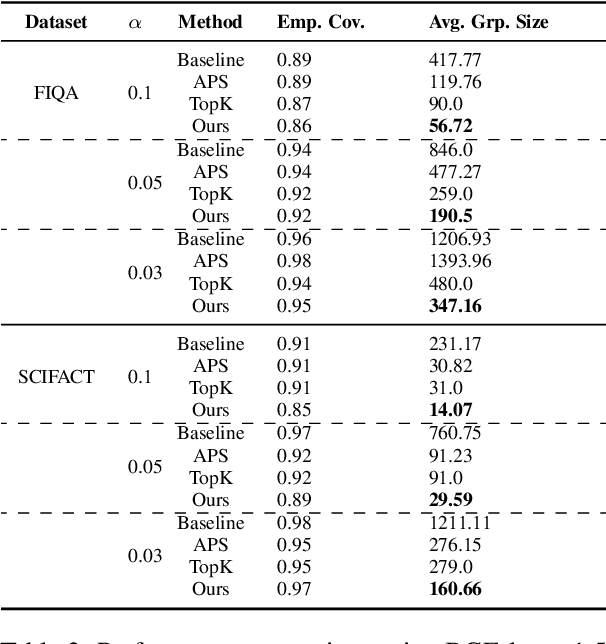
Information retrieval (IR) methods, like retrieval augmented generation, are fundamental to modern applications but often lack statistical guarantees. Conformal prediction addresses this by retrieving sets guaranteed to include relevant information, yet existing approaches produce large-sized sets, incurring high computational costs and slow response times. In this work, we introduce a score refinement method that applies a simple monotone transformation to retrieval scores, leading to significantly smaller conformal sets while maintaining their statistical guarantees. Experiments on various BEIR benchmarks validate the effectiveness of our approach in producing compact sets containing relevant information.
Predicting Generalization of AI Colonoscopy Models to Unseen Data
Mar 22, 2024



$\textbf{Background}$: Generalizability of AI colonoscopy algorithms is important for wider adoption in clinical practice. However, current techniques for evaluating performance on unseen data require expensive and time-intensive labels. $\textbf{Methods}$: We use a "Masked Siamese Network" (MSN) to identify novel phenomena in unseen data and predict polyp detector performance. MSN is trained to predict masked out regions of polyp images, without any labels. We test MSN's ability to be trained on data only from Israel and detect unseen techniques, narrow-band imaging (NBI) and chromendoscoy (CE), on colonoscopes from Japan (354 videos, 128 hours). We also test MSN's ability to predict performance of Computer Aided Detection (CADe) of polyps on colonoscopies from both countries, even though MSN is not trained on data from Japan. $\textbf{Results}$: MSN correctly identifies NBI and CE as less similar to Israel whitelight than Japan whitelight (bootstrapped z-test, |z| > 496, p < 10^-8 for both) using the label-free Frechet distance. MSN detects NBI with 99% accuracy, predicts CE better than our heuristic (90% vs 79% accuracy) despite being trained only on whitelight, and is the only method that is robust to noisy labels. MSN predicts CADe polyp detector performance on in-domain Israel and out-of-domain Japan colonoscopies (r=0.79, 0.37 respectively). With few examples of Japan detector performance to train on, MSN prediction of Japan performance improves (r=0.56). $\textbf{Conclusion}$: Our technique can identify distribution shifts in clinical data and can predict CADe detector performance on unseen data, without labels. Our self-supervised approach can aid in detecting when data in practice is different from training, such as between hospitals or data has meaningfully shifted from training. MSN has potential for application to medical image domains beyond colonoscopy.
Breaking the Language Barrier: Can Direct Inference Outperform Pre-Translation in Multilingual LLM Applications?
Mar 04, 2024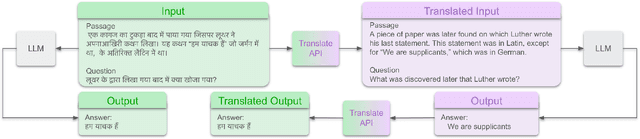
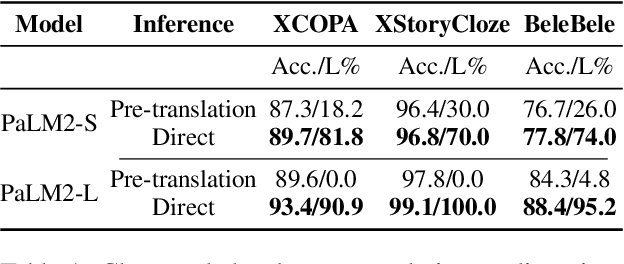

Large language models hold significant promise in multilingual applications. However, inherent biases stemming from predominantly English-centric pre-training have led to the widespread practice of pre-translation, i.e., translating non-English inputs to English before inference, leading to complexity and information loss. This study re-evaluates the need for pre-translation in the context of PaLM2 models (Anil et al., 2023), which have been established as highly performant in multilingual tasks. We offer a comprehensive investigation across 108 languages and 6 diverse benchmarks, including open-end generative tasks, which were excluded from previous similar studies. Our findings challenge the pre-translation paradigm established in prior research, highlighting the advantages of direct inference in PaLM2. Specifically, PaLM2-L consistently outperforms pre-translation in 94 out of 108 languages. These findings pave the way for more efficient and effective multilingual applications, alleviating the limitations associated with pre-translation and unlocking linguistic authenticity.
Self-Supervised Polyp Re-Identification in Colonoscopy
Jun 14, 2023Computer-aided polyp detection (CADe) is becoming a standard, integral part of any modern colonoscopy system. A typical colonoscopy CADe detects a polyp in a single frame and does not track it through the video sequence. Yet, many downstream tasks including polyp characterization (CADx), quality metrics, automatic reporting, require aggregating polyp data from multiple frames. In this work we propose a robust long term polyp tracking method based on re-identification by visual appearance. Our solution uses an attention-based self-supervised ML model, specifically designed to leverage the temporal nature of video input. We quantitatively evaluate method's performance and demonstrate its value for the CADx task.
MDGAN: Boosting Anomaly Detection Using \\Multi-Discriminator Generative Adversarial Networks
Oct 11, 2018

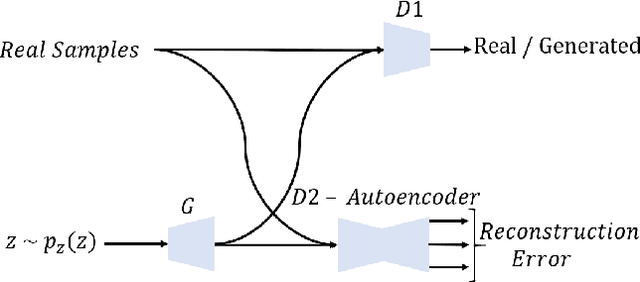
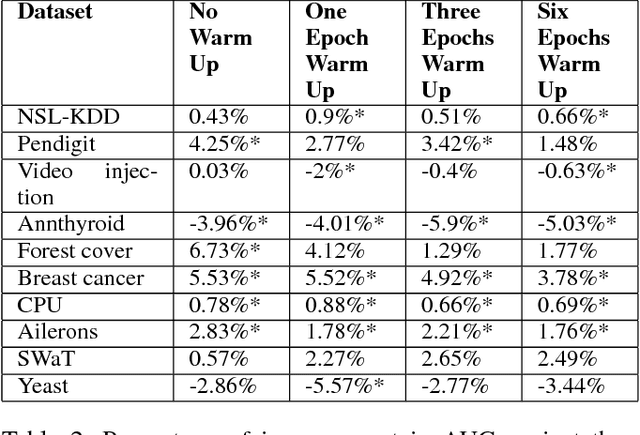
Anomaly detection is often considered a challenging field of machine learning due to the difficulty of obtaining anomalous samples for training and the need to obtain a sufficient amount of training data. In recent years, autoencoders have been shown to be effective anomaly detectors that train only on "normal" data. Generative adversarial networks (GANs) have been used to generate additional training samples for classifiers, thus making them more accurate and robust. However, in anomaly detection GANs are only used to reconstruct existing samples rather than to generate additional ones. This stems both from the small amount and lack of diversity of anomalous data in most domains. In this study we propose MDGAN, a novel GAN architecture for improving anomaly detection through the generation of additional samples. Our approach uses two discriminators: a dense network for determining whether the generated samples are of sufficient quality (i.e., valid) and an autoencoder that serves as an anomaly detector. MDGAN enables us to reconcile two conflicting goals: 1) generate high-quality samples that can fool the first discriminator, and 2) generate samples that can eventually be effectively reconstructed by the second discriminator, thus improving its performance. Empirical evaluation on a diverse set of datasets demonstrates the merits of our approach.