 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMarkov flow policy -- deep MC
May 01, 2024


Discounted algorithms often encounter evaluation errors due to their reliance on short-term estimations, which can impede their efficacy in addressing simple, short-term tasks and impose undesired temporal discounts (\(\gamma\)). Interestingly, these algorithms are often tested without applying a discount, a phenomenon we refer as the \textit{train-test bias}. In response to these challenges, we propose the Markov Flow Policy, which utilizes a non-negative neural network flow to enable comprehensive forward-view predictions. Through integration into the TD7 codebase and evaluation using the MuJoCo benchmark, we observe significant performance improvements, positioning MFP as a straightforward, practical, and easily implementable solution within the domain of average rewards algorithms.
Detecting Anomalous Network Communication Patterns Using Graph Convolutional Networks
Nov 30, 2023
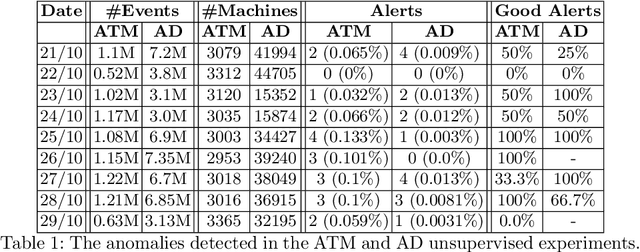
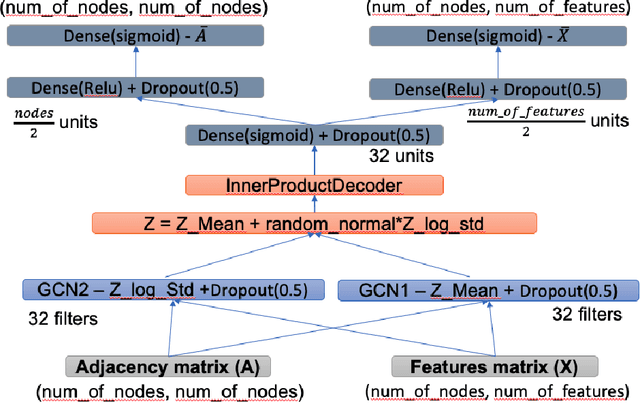
To protect an organizations' endpoints from sophisticated cyberattacks, advanced detection methods are required. In this research, we present GCNetOmaly: a graph convolutional network (GCN)-based variational autoencoder (VAE) anomaly detector trained on data that include connection events among internal and external machines. As input, the proposed GCN-based VAE model receives two matrices: (i) the normalized adjacency matrix, which represents the connections among the machines, and (ii) the feature matrix, which includes various features (demographic, statistical, process-related, and Node2vec structural features) that are used to profile the individual nodes/machines. After training the model on data collected for a predefined time window, the model is applied on the same data; the reconstruction score obtained by the model for a given machine then serves as the machine's anomaly score. GCNetOmaly was evaluated on real, large-scale data logged by Carbon Black EDR from a large financial organization's automated teller machines (ATMs) as well as communication with Active Directory (AD) servers in two setups: unsupervised and supervised. The results of our evaluation demonstrate GCNetOmaly's effectiveness in detecting anomalous behavior of machines on unsupervised data.
ReMark: Receptive Field based Spatial WaterMark Embedding Optimization using Deep Network
May 11, 2023



Watermarking is one of the most important copyright protection tools for digital media. The most challenging type of watermarking is the imperceptible one, which embeds identifying information in the data while retaining the latter's original quality. To fulfill its purpose, watermarks need to withstand various distortions whose goal is to damage their integrity. In this study, we investigate a novel deep learning-based architecture for embedding imperceptible watermarks. The key insight guiding our architecture design is the need to correlate the dimensions of our watermarks with the sizes of receptive fields (RF) of modules of our architecture. This adaptation makes our watermarks more robust, while also enabling us to generate them in a way that better maintains image quality. Extensive evaluations on a wide variety of distortions show that the proposed method is robust against most common distortions on watermarks including collusive distortion.
A Transferable and Automatic Tuning of Deep Reinforcement Learning for Cost Effective Phishing Detection
Sep 19, 2022
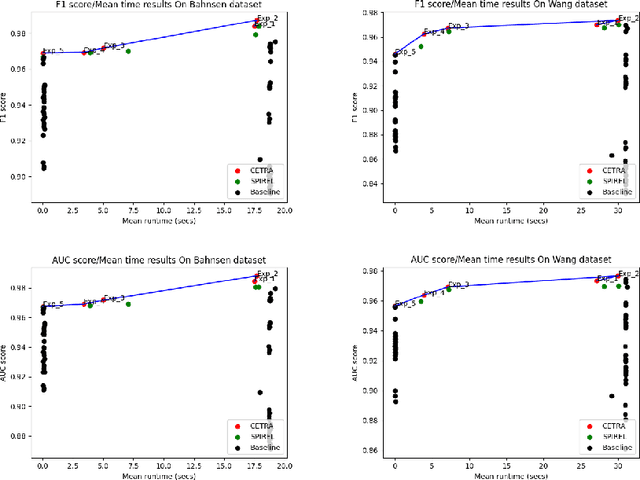

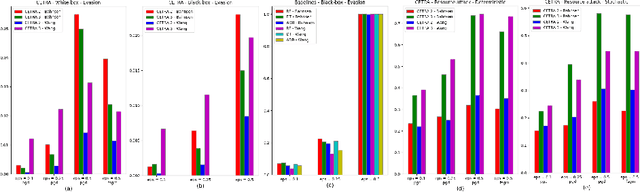
Many challenging real-world problems require the deployment of ensembles multiple complementary learning models to reach acceptable performance levels. While effective, applying the entire ensemble to every sample is costly and often unnecessary. Deep Reinforcement Learning (DRL) offers a cost-effective alternative, where detectors are dynamically chosen based on the output of their predecessors, with their usefulness weighted against their computational cost. Despite their potential, DRL-based solutions are not widely used in this capacity, partly due to the difficulties in configuring the reward function for each new task, the unpredictable reactions of the DRL agent to changes in the data, and the inability to use common performance metrics (e.g., TPR/FPR) to guide the algorithm's performance. In this study we propose methods for fine-tuning and calibrating DRL-based policies so that they can meet multiple performance goals. Moreover, we present a method for transferring effective security policies from one dataset to another. Finally, we demonstrate that our approach is highly robust against adversarial attacks.
Secure Machine Learning in the Cloud Using One Way Scrambling by Deconvolution
Nov 04, 2021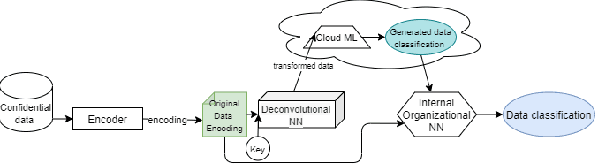
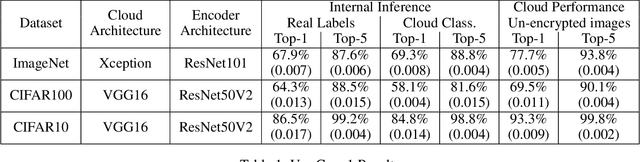
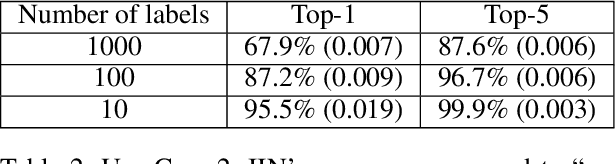
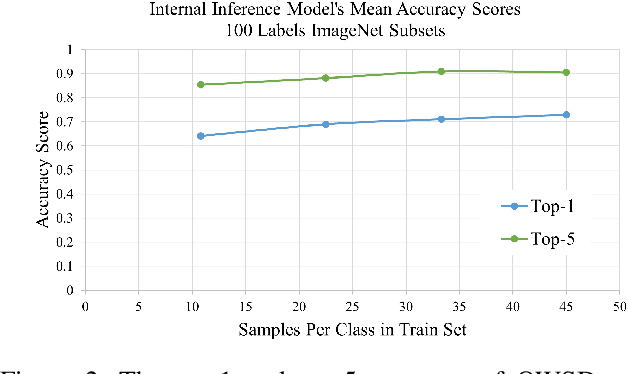
Cloud-based machine learning services (CMLS) enable organizations to take advantage of advanced models that are pre-trained on large quantities of data. The main shortcoming of using these services, however, is the difficulty of keeping the transmitted data private and secure. Asymmetric encryption requires the data to be decrypted in the cloud, while Homomorphic encryption is often too slow and difficult to implement. We propose One Way Scrambling by Deconvolution (OWSD), a deconvolution-based scrambling framework that offers the advantages of Homomorphic encryption at a fraction of the computational overhead. Extensive evaluation on multiple image datasets demonstrates OWSD's ability to achieve near-perfect classification performance when the output vector of the CMLS is sufficiently large. Additionally, we provide empirical analysis of the robustness of our approach.
Anomaly Detection for Aggregated Data Using Multi-Graph Autoencoder
Jan 11, 2021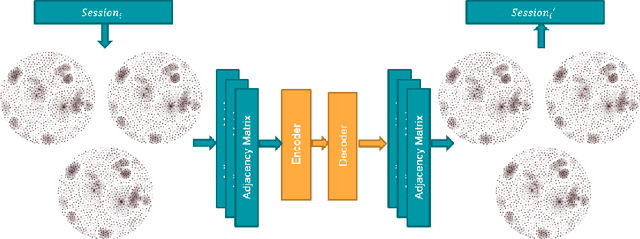
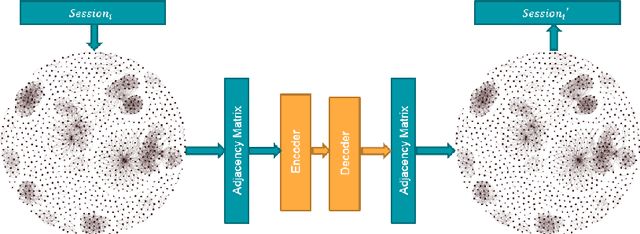
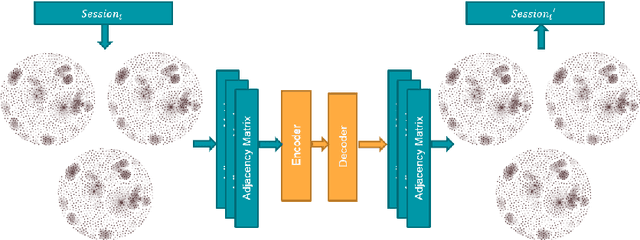
In data systems, activities or events are continuously collected in the field to trace their proper executions. Logging, which means recording sequences of events, can be used for analyzing system failures and malfunctions, and identifying the causes and locations of such issues. In our research we focus on creating an Anomaly detection models for system logs. The task of anomaly detection is identifying unexpected events in dataset, which differ from the normal behavior. Anomaly detection models also assist in data systems analysis tasks. Modern systems may produce such a large amount of events monitoring every individual event is not feasible. In such cases, the events are often aggregated over a fixed period of time, reporting the number of times every event has occurred in that time period. This aggregation facilitates scaling, but requires a different approach for anomaly detection. In this research, we present a thorough analysis of the aggregated data and the relationships between aggregated events. Based on the initial phase of our research we present graphs representations of our aggregated dataset, which represent the different relationships between aggregated instances in the same context. Using the graph representation, we propose Multiple-graphs autoencoder MGAE, a novel convolutional graphs-autoencoder model which exploits the relationships of the aggregated instances in our unique dataset. MGAE outperforms standard graph-autoencoder models and the different experiments. With our novel MGAE we present 60% decrease in reconstruction error in comparison to standard graph autoencoder, which is expressed in reconstructing high-degree relationships.
Hierarchical Deep Reinforcement Learning Approach for Multi-Objective Scheduling With Varying Queue Sizes
Jul 17, 2020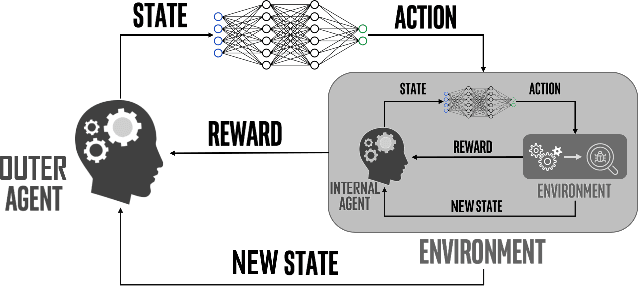
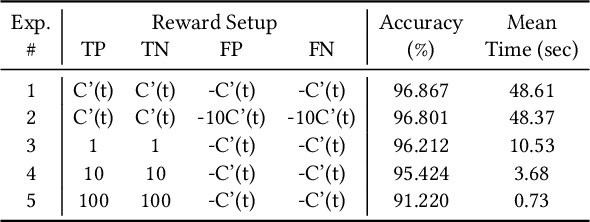

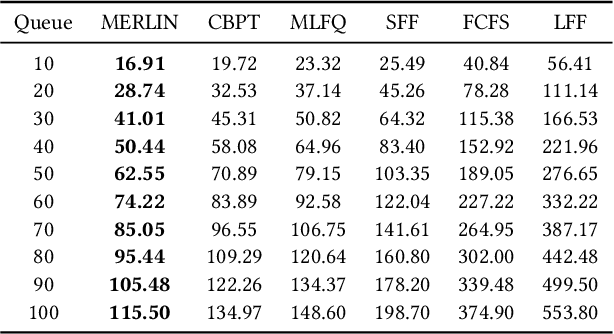
Multi-objective task scheduling (MOTS) is the task scheduling while optimizing multiple and possibly contradicting constraints. A challenging extension of this problem occurs when every individual task is a multi-objective optimization problem by itself. While deep reinforcement learning (DRL) has been successfully applied to complex sequential problems, its application to the MOTS domain has been stymied by two challenges. The first challenge is the inability of the DRL algorithm to ensure that every item is processed identically regardless of its position in the queue. The second challenge is the need to manage large queues, which results in large neural architectures and long training times. In this study we present MERLIN, a robust, modular and near-optimal DRL-based approach for multi-objective task scheduling. MERLIN applies a hierarchical approach to the MOTS problem by creating one neural network for the processing of individual tasks and another for the scheduling of the overall queue. In addition to being smaller and with shorted training times, the resulting architecture ensures that an item is processed in the same manner regardless of its position in the queue. Additionally, we present a novel approach for efficiently applying DRL-based solutions on very large queues, and demonstrate how we effectively scale MERLIN to process queue sizes that are larger by orders of magnitude than those on which it was trained. Extensive evaluation on multiple queue sizes show that MERLIN outperforms multiple well-known baselines by a large margin (>22%).
PIVEN: A Deep Neural Network for Prediction Intervals with Specific Value Prediction
Jun 09, 2020
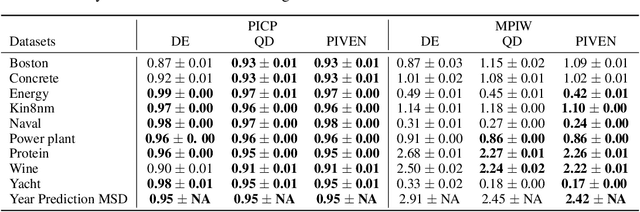
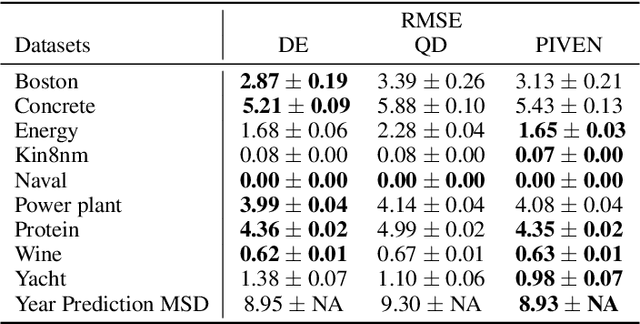
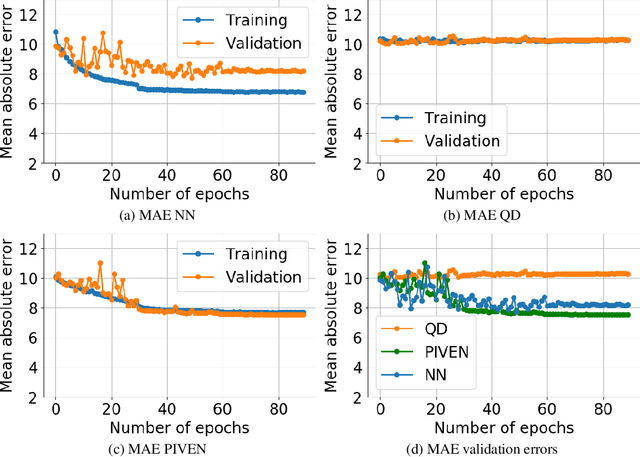
Improving the robustness of neural nets in regression tasks is key to their application in multiple domains. Deep learning-based approaches aim to achieve this goal either by improving the manner in which they produce their prediction of specific values (i.e., point prediction), or by producing prediction intervals (PIs) that quantify uncertainty. We present PIVEN, a deep neural network for producing both a PI and a prediction of specific values. Benchmark experiments show that our approach produces tighter uncertainty bounds than the current state-of-the-art approach for producing PIs, while managing to maintain comparable performance to the state-of-the-art approach for specific value-prediction. Additional evaluation on large image datasets further support our conclusions.
Automatic Machine Learning Derived from Scholarly Big Data
Mar 06, 2020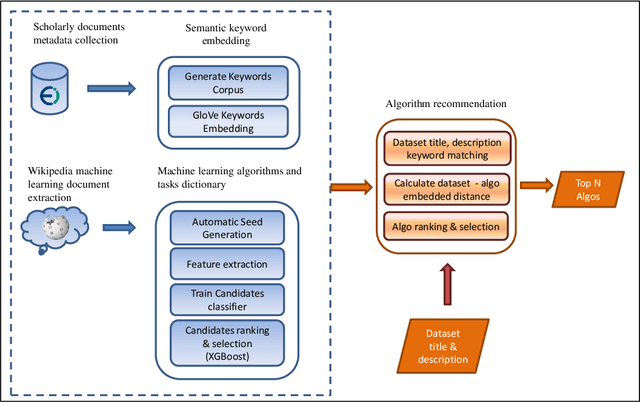
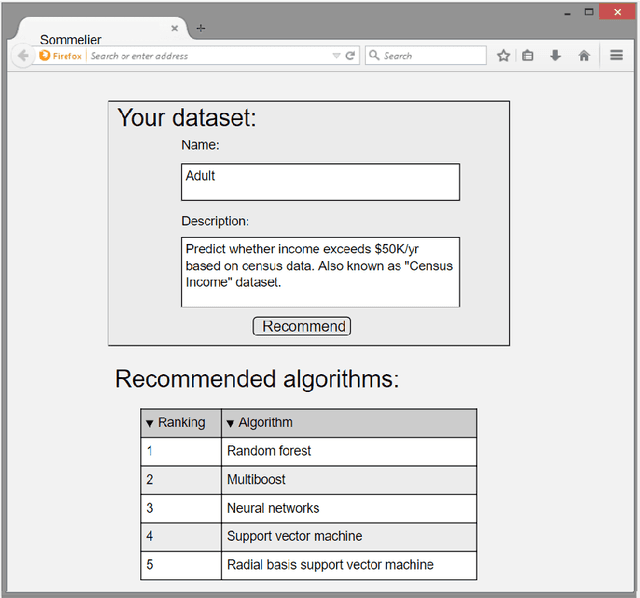

One of the challenging aspects of applying machine learning is the need to identify the algorithms that will perform best for a given dataset. This process can be difficult, time consuming and often requires a great deal of domain knowledge. We present Sommelier, an expert system for recommending the machine learning algorithms that should be applied on a previously unseen dataset. Sommelier is based on word embedding representations of the domain knowledge extracted from a large corpus of academic publications. When presented with a new dataset and its problem description, Sommelier leverages a recommendation model trained on the word embedding representation to provide a ranked list of the most relevant algorithms to be used on the dataset. We demonstrate Sommelier's effectiveness by conducting an extensive evaluation on 121 publicly available datasets and 53 classification algorithms. The top algorithms recommended for each dataset by Sommelier were able to achieve on average 97.7% of the optimal accuracy of all surveyed algorithms.
RankML: a Meta Learning-Based Approach for Pre-Ranking Machine Learning Pipelines
Nov 20, 2019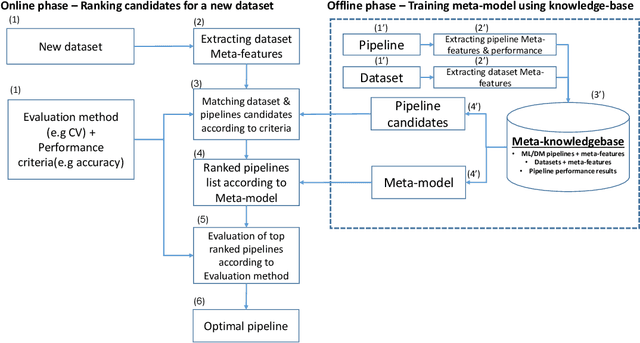
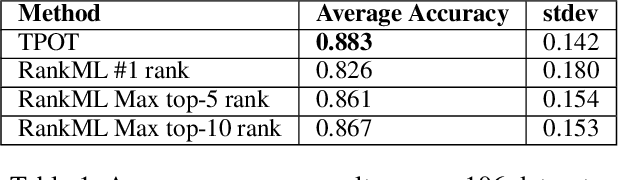
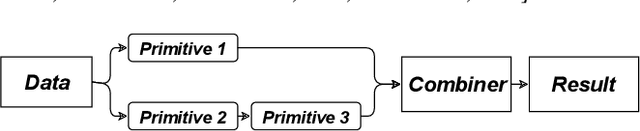
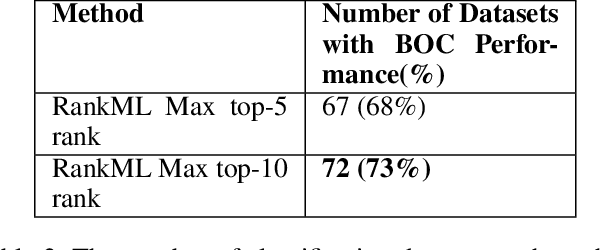
The explosion of digital data has created multiple opportunities for organizations and individuals to leverage machine learning (ML) to transform the way they operate. However, the shortage of experts in the field of machine learning -- data scientists -- is often a setback to the use of ML. In an attempt to alleviate this shortage, multiple approaches for the automation of machine learning have been proposed in recent years. While these approaches are effective, they often require a great deal of time and computing resources. In this study, we propose RankML, a meta-learning based approach for predicting the performance of whole machine learning pipelines. Given a previously-unseen dataset, a performance metric, and a set of candidate pipelines, RankML immediately produces a ranked list of all pipelines based on their predicted performance. Extensive evaluation on 244 datasets, both in regression and classification tasks, shows that our approach either outperforms or is comparable to state-of-the-art, computationally heavy approaches while requiring a fraction of the time and computational cost.