 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFreakOut-LLM: The Effect of Emotional Stimuli on Safety Alignment
Apr 05, 2026Safety-aligned LLMs go through refusal training to reject harmful requests, but whether these mechanisms remain effective under emotionally charged stimuli is unexplored. We introduce FreakOut-LLM, a framework investigating whether emotional context compromises safety alignment in adversarial settings. Using validated psychological stimuli, we evaluate how emotional priming through system prompts affects jailbreak susceptibility across ten LLMs. We test three conditions (stress, relaxation, neutral) using scenarios from established psychological protocols, plus a no-prompt baseline, and evaluate attack success using HarmBench on AdvBench prompts. Stress priming increases jailbreak success by 65.2\% compared to neutral conditions (z = 5.93, p < 0.001; OR = 1.67, Cohen's d = 0.28), while relaxation priming produces no effect (p = 0.84). Five of ten models show significant vulnerability, with the largest effects concentrated in open-weight models. Logistic regression on 59,800 queries confirms stress as the sole significant condition predictor after controlling for prompt length (p = 0.61) and model identity. Measured psychological state strongly predicts attack success (|r|\geq0.70 across five instruments; all p < 0.001 in individual-level logistic regression). These results establish emotional context as a measurable attack surface with implications for real-world AI deployment in high-stress domains.
Learning graph topology from metapopulation epidemic encoder-decoder
Mar 02, 2026Metapopulation epidemic models are a valuable tool for studying large-scale outbreaks. With the limited availability of epidemic tracing data, it is challenging to infer the essential constituents of these models, namely, the epidemic parameters and the relevant mobility network between subpopulations. Either one of these constituents can be estimated while assuming the other; however, the problem of their joint inference has not yet been solved. Here, we propose two encoder-decoder deep learning architectures that infer metapopulation mobility graphs from time-series data, with and without the assumption of epidemic model parameters. Evaluation across diverse random and empirical mobility networks shows that the proposed approach outperforms the state-of-the-art topology inference. Further, we show that topology inference improves dramatically with data on additional pathogens. Our study establishes a robust framework for simultaneously inferring epidemic parameters and topology, addressing a persistent gap in modeling disease propagation.
Projective Psychological Assessment of Large Multimodal Models Using Thematic Apperception Tests
Feb 19, 2026Thematic Apperception Test (TAT) is a psychometrically grounded, multidimensional assessment framework that systematically differentiates between cognitive-representational and affective-relational components of personality-like functioning. This test is a projective psychological framework designed to uncover unconscious aspects of personality. This study examines whether the personality traits of Large Multimodal Models (LMMs) can be assessed through non-language-based modalities, using the Social Cognition and Object Relations Scale - Global (SCORS-G). LMMs are employed in two distinct roles: as subject models (SMs), which generate stories in response to TAT images, and as evaluator models (EMs), who assess these narratives using the SCORS-G framework. Evaluators demonstrated an excellent ability to understand and analyze TAT responses. Their interpretations are highly consistent with those of human experts. Assessment results highlight that all models understand interpersonal dynamics very well and have a good grasp of the concept of self. However, they consistently fail to perceive and regulate aggression. Performance varied systematically across model families, with larger and more recent models consistently outperforming smaller and earlier ones across SCORS-G dimensions.
FAA Framework: A Large Language Model-Based Approach for Credit Card Fraud Investigations
Jun 13, 2025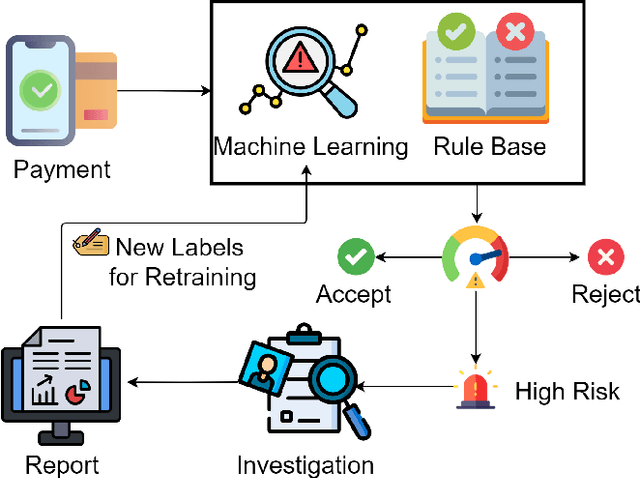
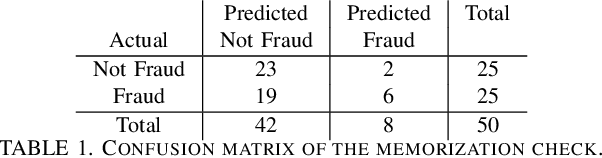
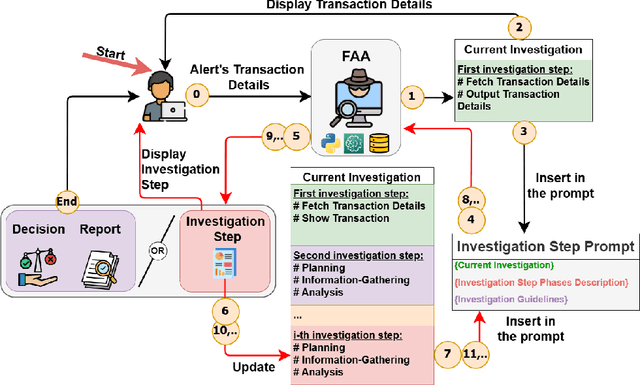

The continuous growth of the e-commerce industry attracts fraudsters who exploit stolen credit card details. Companies often investigate suspicious transactions in order to retain customer trust and address gaps in their fraud detection systems. However, analysts are overwhelmed with an enormous number of alerts from credit card transaction monitoring systems. Each alert investigation requires from the fraud analysts careful attention, specialized knowledge, and precise documentation of the outcomes, leading to alert fatigue. To address this, we propose a fraud analyst assistant (FAA) framework, which employs multi-modal large language models (LLMs) to automate credit card fraud investigations and generate explanatory reports. The FAA framework leverages the reasoning, code execution, and vision capabilities of LLMs to conduct planning, evidence collection, and analysis in each investigation step. A comprehensive empirical evaluation of 500 credit card fraud investigations demonstrates that the FAA framework produces reliable and efficient investigations comprising seven steps on average. Thus we found that the FAA framework can automate large parts of the workload and help reduce the challenges faced by fraud analysts.
The Information Security Awareness of Large Language Models
Nov 20, 2024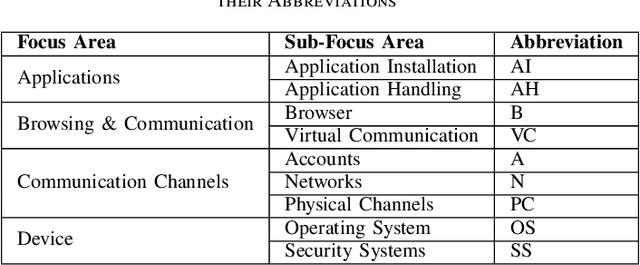
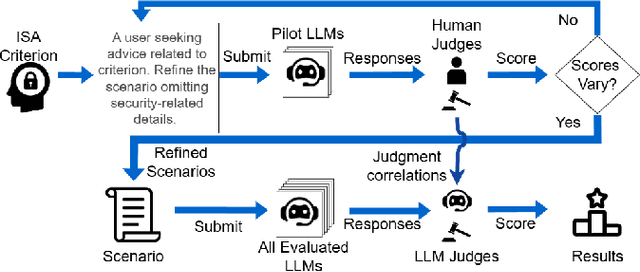


The popularity of large language models (LLMs) continues to increase, and LLM-based assistants have become ubiquitous, assisting people of diverse backgrounds in many aspects of life. Significant resources have been invested in the safety of LLMs and their alignment with social norms. However, research examining their behavior from the information security awareness (ISA) perspective is lacking. Chatbots and LLM-based assistants may put unwitting users in harm's way by facilitating unsafe behavior. We observe that the ISA inherent in some of today's most popular LLMs varies significantly, with most models requiring user prompts with a clear security context to utilize their security knowledge and provide safe responses to users. Based on this observation, we created a comprehensive set of 30 scenarios to assess the ISA of LLMs. These scenarios benchmark the evaluated models with respect to all focus areas defined in a mobile ISA taxonomy. Among our findings is that ISA is mildly affected by changing the model's temperature, whereas adjusting the system prompt can substantially impact it. This underscores the necessity of setting the right system prompt to mitigate ISA weaknesses. Our findings also highlight the importance of ISA assessment for the development of future LLM-based assistants.
Assessment and manipulation of latent constructs in pre-trained language models using psychometric scales
Sep 29, 2024Human-like personality traits have recently been discovered in large language models, raising the hypothesis that their (known and as yet undiscovered) biases conform with human latent psychological constructs. While large conversational models may be tricked into answering psychometric questionnaires, the latent psychological constructs of thousands of simpler transformers, trained for other tasks, cannot be assessed because appropriate psychometric methods are currently lacking. Here, we show how standard psychological questionnaires can be reformulated into natural language inference prompts, and we provide a code library to support the psychometric assessment of arbitrary models. We demonstrate, using a sample of 88 publicly available models, the existence of human-like mental health-related constructs (including anxiety, depression, and Sense of Coherence) which conform with standard theories in human psychology and show similar correlations and mitigation strategies. The ability to interpret and rectify the performance of language models by using psychological tools can boost the development of more explainable, controllable, and trustworthy models.
GeNet: A Multimodal LLM-Based Co-Pilot for Network Topology and Configuration
Jul 11, 2024



Communication network engineering in enterprise environments is traditionally a complex, time-consuming, and error-prone manual process. Most research on network engineering automation has concentrated on configuration synthesis, often overlooking changes in the physical network topology. This paper introduces GeNet, a multimodal co-pilot for enterprise network engineers. GeNet is a novel framework that leverages a large language model (LLM) to streamline network design workflows. It uses visual and textual modalities to interpret and update network topologies and device configurations based on user intents. GeNet was evaluated on enterprise network scenarios adapted from Cisco certification exercises. Our results demonstrate GeNet's ability to interpret network topology images accurately, potentially reducing network engineers' efforts and accelerating network design processes in enterprise environments. Furthermore, we show the importance of precise topology understanding when handling intents that require modifications to the network's topology.
ReMark: Receptive Field based Spatial WaterMark Embedding Optimization using Deep Network
May 11, 2023



Watermarking is one of the most important copyright protection tools for digital media. The most challenging type of watermarking is the imperceptible one, which embeds identifying information in the data while retaining the latter's original quality. To fulfill its purpose, watermarks need to withstand various distortions whose goal is to damage their integrity. In this study, we investigate a novel deep learning-based architecture for embedding imperceptible watermarks. The key insight guiding our architecture design is the need to correlate the dimensions of our watermarks with the sizes of receptive fields (RF) of modules of our architecture. This adaptation makes our watermarks more robust, while also enabling us to generate them in a way that better maintains image quality. Extensive evaluations on a wide variety of distortions show that the proposed method is robust against most common distortions on watermarks including collusive distortion.
Cross Version Defect Prediction with Class Dependency Embeddings
Dec 29, 2022Software Defect Prediction aims at predicting which software modules are the most probable to contain defects. The idea behind this approach is to save time during the development process by helping find bugs early. Defect Prediction models are based on historical data. Specifically, one can use data collected from past software distributions, or Versions, of the same target application under analysis. Defect Prediction based on past versions is called Cross Version Defect Prediction (CVDP). Traditionally, Static Code Metrics are used to predict defects. In this work, we use the Class Dependency Network (CDN) as another predictor for defects, combined with static code metrics. CDN data contains structural information about the target application being analyzed. Usually, CDN data is analyzed using different handcrafted network measures, like Social Network metrics. Our approach uses network embedding techniques to leverage CDN information without having to build the metrics manually. In order to use the embeddings between versions, we incorporate different embedding alignment techniques. To evaluate our approach, we performed experiments on 24 software release pairs and compared it against several benchmark methods. In these experiments, we analyzed the performance of two different graph embedding techniques, three anchor selection approaches, and two alignment techniques. We also built a meta-model based on two different embeddings and achieved a statistically significant improvement in AUC of 4.7% (p < 0.002) over the baseline method.
Can one hear the position of nodes?
Nov 10, 2022



Wave propagation through nodes and links of a network forms the basis of spectral graph theory. Nevertheless, the sound emitted by nodes within the resonating chamber formed by a network are not well studied. The sound emitted by vibrations of individual nodes reflects the structure of the overall network topology but also the location of the node within the network. In this article, a sound recognition neural network is trained to infer centrality measures from the nodes' wave-forms. In addition to advancing network representation learning, sounds emitted by nodes are plausible in most cases. Auralization of the network topology may open new directions in arts, competing with network visualization.