 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessment and manipulation of latent constructs in pre-trained language models using psychometric scales
Sep 29, 2024Human-like personality traits have recently been discovered in large language models, raising the hypothesis that their (known and as yet undiscovered) biases conform with human latent psychological constructs. While large conversational models may be tricked into answering psychometric questionnaires, the latent psychological constructs of thousands of simpler transformers, trained for other tasks, cannot be assessed because appropriate psychometric methods are currently lacking. Here, we show how standard psychological questionnaires can be reformulated into natural language inference prompts, and we provide a code library to support the psychometric assessment of arbitrary models. We demonstrate, using a sample of 88 publicly available models, the existence of human-like mental health-related constructs (including anxiety, depression, and Sense of Coherence) which conform with standard theories in human psychology and show similar correlations and mitigation strategies. The ability to interpret and rectify the performance of language models by using psychological tools can boost the development of more explainable, controllable, and trustworthy models.
Fake News Data Collection and Classification: Iterative Query Selection for Opaque Search Engines with Pseudo Relevance Feedback
Dec 23, 2020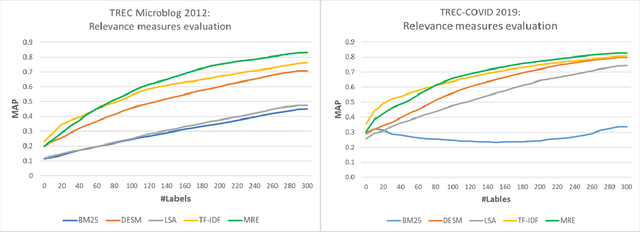
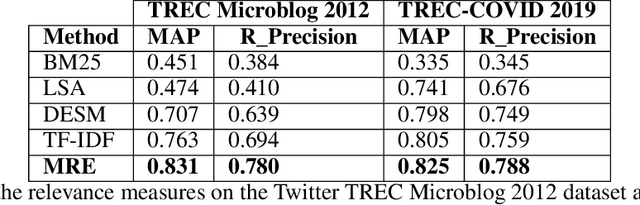
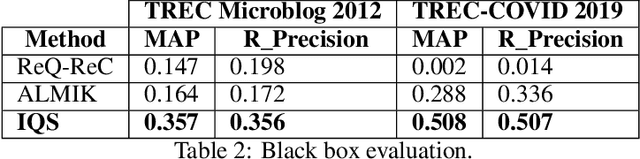
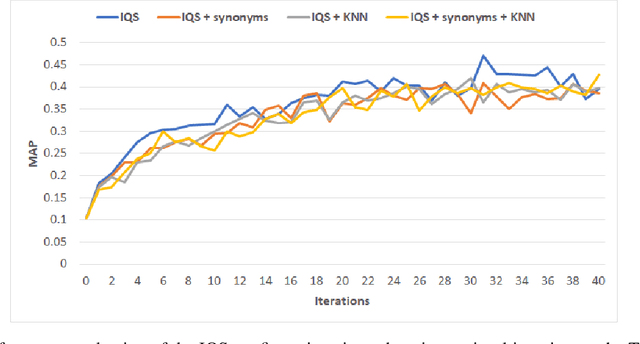
Retrieving information from an online search engine is the first and most important step in many data mining tasks. Most of the search engines currently available on the web, including all social media platforms, are black-boxes (a.k.a opaque) supporting short keyword queries. In these settings, retrieving all posts and comments discussing a particular news item automatically and at large scales is a challenging task. In this paper, we propose a method for generating short keyword queries given a prototype document. The proposed algorithm interacts with the opaque search engine to iteratively improve the query. It is evaluated on the Twitter TREC Microblog 2012 and TREC-COVID 2019 datasets showing superior performance compared to state of the art and is applied to automatically collect large scale dataset for training machine learning classifiers for fake news detection. The classifiers training on 70,000 labeled news items and more than 61 million associated tweets automatically collected using the proposed method obtained impressive performance of AUC and accuracy of 0.92, and 0.86, respectively.