 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFake News Data Collection and Classification: Iterative Query Selection for Opaque Search Engines with Pseudo Relevance Feedback
Dec 23, 2020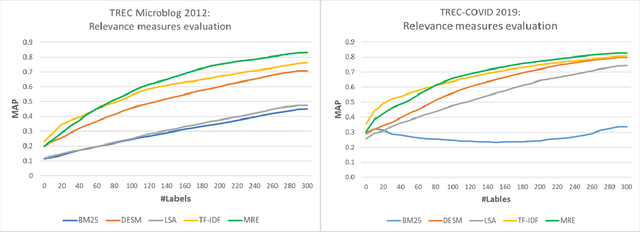
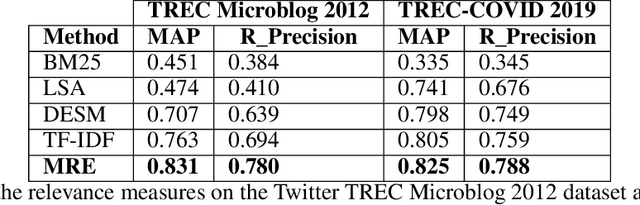
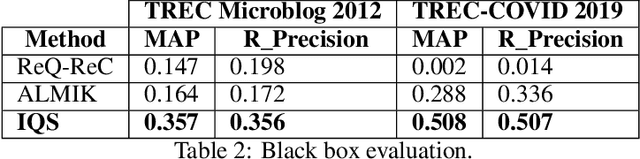
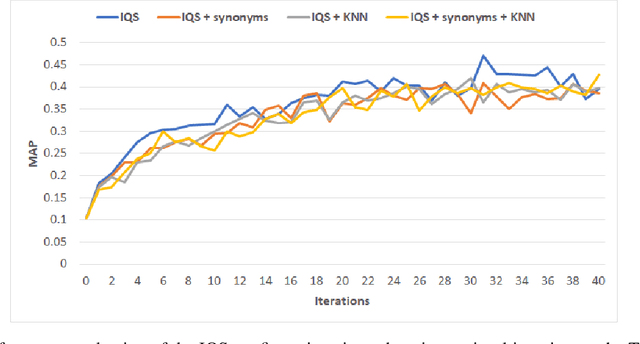
Retrieving information from an online search engine is the first and most important step in many data mining tasks. Most of the search engines currently available on the web, including all social media platforms, are black-boxes (a.k.a opaque) supporting short keyword queries. In these settings, retrieving all posts and comments discussing a particular news item automatically and at large scales is a challenging task. In this paper, we propose a method for generating short keyword queries given a prototype document. The proposed algorithm interacts with the opaque search engine to iteratively improve the query. It is evaluated on the Twitter TREC Microblog 2012 and TREC-COVID 2019 datasets showing superior performance compared to state of the art and is applied to automatically collect large scale dataset for training machine learning classifiers for fake news detection. The classifiers training on 70,000 labeled news items and more than 61 million associated tweets automatically collected using the proposed method obtained impressive performance of AUC and accuracy of 0.92, and 0.86, respectively.
How Does That Sound? Multi-Language SpokenName2Vec Algorithm Using Speech Generation and Deep Learning
May 24, 2020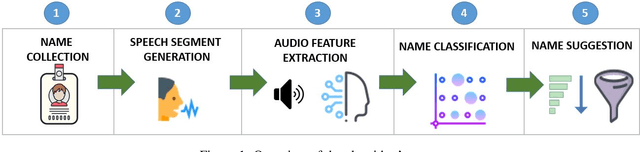
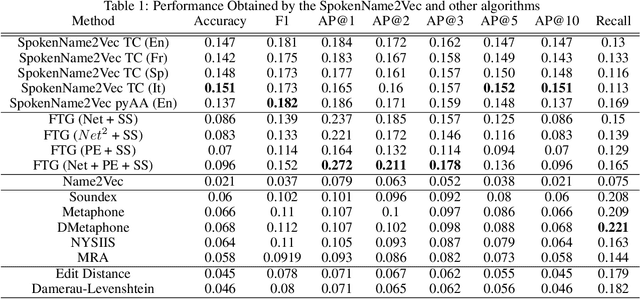

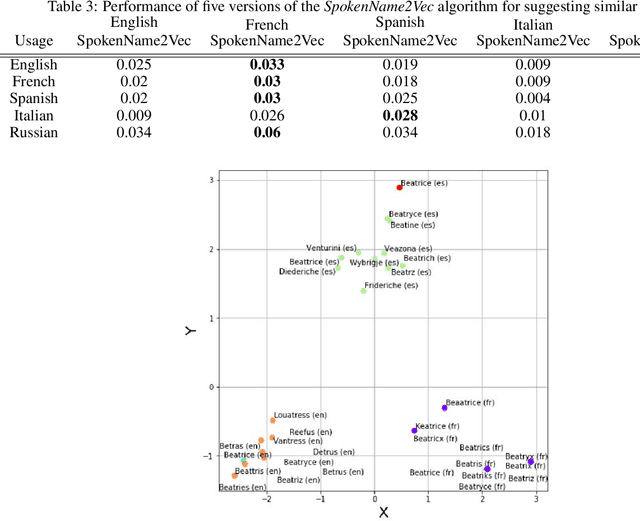
Searching for information about a specific person is an online activity frequently performed by many users. In most cases, users are aided by queries containing a name and sending back to the web search engines for finding their will. Typically, Web search engines provide just a few accurate results associated with a name-containing query. Currently, most solutions for suggesting synonyms in online search are based on pattern matching and phonetic encoding, however very often, the performance of such solutions is less than optimal. In this paper, we propose SpokenName2Vec, a novel and generic approach which addresses the similar name suggestion problem by utilizing automated speech generation, and deep learning to produce spoken name embeddings. This sophisticated and innovative embeddings captures the way people pronounce names in any language and accent. Utilizing the name pronunciation can be helpful for both differentiating and detecting names that sound alike, but are written differently. The proposed approach was demonstrated on a large-scale dataset consisting of 250,000 forenames and evaluated using a machine learning classifier and 7,399 names with their verified synonyms. The performance of the proposed approach was found to be superior to 12 other algorithms evaluated in this study, including well used phonetic and string similarity algorithms, and two recently proposed algorithms. The results obtained suggest that the proposed approach could serve as a useful and valuable tool for solving the similar name suggestion problem.