 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFramework of Voting Prediction of Parliament Members
May 18, 2025Keeping track of how lawmakers vote is essential for government transparency. While many parliamentary voting records are available online, they are often difficult to interpret, making it challenging to understand legislative behavior across parliaments and predict voting outcomes. Accurate prediction of votes has several potential benefits, from simplifying parliamentary work by filtering out bills with a low chance of passing to refining proposed legislation to increase its likelihood of approval. In this study, we leverage advanced machine learning and data analysis techniques to develop a comprehensive framework for predicting parliamentary voting outcomes across multiple legislatures. We introduce the Voting Prediction Framework (VPF) - a data-driven framework designed to forecast parliamentary voting outcomes at the individual legislator level and for entire bills. VPF consists of three key components: (1) Data Collection - gathering parliamentary voting records from multiple countries using APIs, web crawlers, and structured databases; (2) Parsing and Feature Integration - processing and enriching the data with meaningful features, such as legislator seniority, and content-based characteristics of a given bill; and (3) Prediction Models - using machine learning to forecast how each parliament member will vote and whether a bill is likely to pass. The framework will be open source, enabling anyone to use or modify the framework. To evaluate VPF, we analyzed over 5 million voting records from five countries - Canada, Israel, Tunisia, the United Kingdom and the USA. Our results show that VPF achieves up to 85% precision in predicting individual votes and up to 84% accuracy in predicting overall bill outcomes. These findings highlight VPF's potential as a valuable tool for political analysis, policy research, and enhancing public access to legislative decision-making.
Dark LLMs: The Growing Threat of Unaligned AI Models
May 15, 2025Large Language Models (LLMs) rapidly reshape modern life, advancing fields from healthcare to education and beyond. However, alongside their remarkable capabilities lies a significant threat: the susceptibility of these models to jailbreaking. The fundamental vulnerability of LLMs to jailbreak attacks stems from the very data they learn from. As long as this training data includes unfiltered, problematic, or 'dark' content, the models can inherently learn undesirable patterns or weaknesses that allow users to circumvent their intended safety controls. Our research identifies the growing threat posed by dark LLMs models deliberately designed without ethical guardrails or modified through jailbreak techniques. In our research, we uncovered a universal jailbreak attack that effectively compromises multiple state-of-the-art models, enabling them to answer almost any question and produce harmful outputs upon request. The main idea of our attack was published online over seven months ago. However, many of the tested LLMs were still vulnerable to this attack. Despite our responsible disclosure efforts, responses from major LLM providers were often inadequate, highlighting a concerning gap in industry practices regarding AI safety. As model training becomes more accessible and cheaper, and as open-source LLMs proliferate, the risk of widespread misuse escalates. Without decisive intervention, LLMs may continue democratizing access to dangerous knowledge, posing greater risks than anticipated.
Shaping History: Advanced Machine Learning Techniques for the Analysis and Dating of Cuneiform Tablets over Three Millennia
Jun 06, 2024


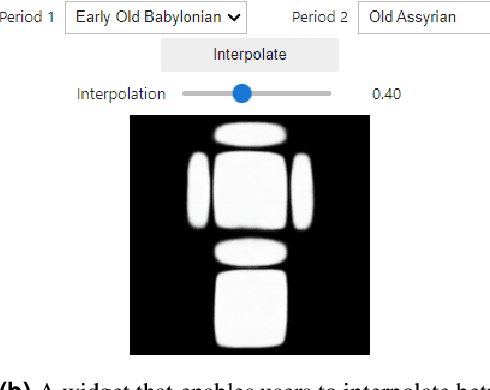
Cuneiform tablets, emerging in ancient Mesopotamia around the late fourth millennium BCE, represent one of humanity's earliest writing systems. Characterized by wedge-shaped marks on clay tablets, these artifacts provided insight into Mesopotamian civilization across various domains. Traditionally, the analysis and dating of these tablets rely on subjective assessment of shape and writing style, leading to uncertainties in pinpointing their exact temporal origins. Recent advances in digitization have revolutionized the study of cuneiform by enhancing accessibility and analytical capabilities. Our research uniquely focuses on the silhouette of tablets as significant indicators of their historical periods, diverging from most studies that concentrate on textual content. Utilizing an unprecedented dataset of over 94,000 images from the Cuneiform Digital Library Initiative collection, we apply deep learning methods to classify cuneiform tablets, covering over 3,000 years of history. By leveraging statistical, computational techniques, and generative modeling through Variational Auto-Encoders (VAEs), we achieve substantial advancements in the automatic classification of these ancient documents, focusing on the tablets' silhouettes as key predictors. Our classification approach begins with a Decision Tree using height-to-width ratios and culminates with a ResNet50 model, achieving a 61% macro F1-score for tablet silhouettes. Moreover, we introduce novel VAE-powered tools to enhance explainability and enable researchers to explore changes in tablet shapes across different eras and genres. This research contributes to document analysis and diplomatics by demonstrating the value of large-scale data analysis combined with statistical methods. These insights offer valuable tools for historians and epigraphists, enriching our understanding of cuneiform tablets and the cultures that produced them.
A Novel Method for News Article Event-Based Embedding
May 20, 2024Embedding news articles is a crucial tool for multiple fields, such as media bias detection, identifying fake news, and news recommendations. However, existing news embedding methods are not optimized for capturing the latent context of news events. In many cases, news embedding methods rely on full-textual information and neglect the importance of time-relevant embedding generation. Here, we aim to address these shortcomings by presenting a novel lightweight method that optimizes news embedding generation by focusing on the entities and themes mentioned in the articles and their historical connections to specific events. We suggest a method composed of three stages. First, we process and extract the events, entities, and themes for the given news articles. Second, we generate periodic time embeddings for themes and entities by training timely separated GloVe models on current and historical data. Lastly, we concatenate the news embeddings generated by two distinct approaches: Smooth Inverse Frequency (SIF) for article-level vectors and Siamese Neural Networks for embeddings with nuanced event-related information. To test and evaluate our method, we leveraged over 850,000 news articles and 1,000,000 events from the GDELT project. For validation purposes, we conducted a comparative analysis of different news embedding generation methods, applying them twice to a shared event detection task - first on articles published within the same day and subsequently on those published within the same month. Our experiments show that our method significantly improves the Precision-Recall (PR) AUC across all tasks and datasets. Specifically, we observed an average PR AUC improvement of 2.15% and 2.57% compared to SIF, as well as 2.57% and 2.43% compared to the semi-supervised approach for daily and monthly shared event detection tasks, respectively.
Analyzing Key Users' behavior trends in Volunteer-Based Networks
Oct 04, 2023



Online social networks usage has increased significantly in the last decade and continues to grow in popularity. Multiple social platforms use volunteers as a central component. The behavior of volunteers in volunteer-based networks has been studied extensively in recent years. Here, we explore the development of volunteer-based social networks, primarily focusing on their key users' behaviors and activities. We developed two novel algorithms: the first reveals key user behavior patterns over time; the second utilizes machine learning methods to generate a forecasting model that can predict the future behavior of key users, including whether they will remain active donors or change their behavior to become mainly recipients, and vice-versa. These algorithms allowed us to analyze the factors that significantly influence behavior predictions. To evaluate our algorithms, we utilized data from over 2.4 million users on a peer-to-peer food-sharing online platform. Using our algorithm, we identified four main types of key user behavior patterns that occur over time. Moreover, we succeeded in forecasting future active donor key users and predicting the key users that would change their behavior to donors, with an accuracy of up to 89.6%. These findings provide valuable insights into the behavior of key users in volunteer-based social networks and pave the way for more effective communities-building in the future, while using the potential of machine learning for this goal.
Short Run Transit Route Planning Decision Support System Using a Deep Learning-Based Weighted Graph
Aug 24, 2023



Public transport routing plays a crucial role in transit network design, ensuring a satisfactory level of service for passengers. However, current routing solutions rely on traditional operational research heuristics, which can be time-consuming to implement and lack the ability to provide quick solutions. Here, we propose a novel deep learning-based methodology for a decision support system that enables public transport (PT) planners to identify short-term route improvements rapidly. By seamlessly adjusting specific sections of routes between two stops during specific times of the day, our method effectively reduces times and enhances PT services. Leveraging diverse data sources such as GTFS and smart card data, we extract features and model the transportation network as a directed graph. Using self-supervision, we train a deep learning model for predicting lateness values for road segments. These lateness values are then utilized as edge weights in the transportation graph, enabling efficient path searching. Through evaluating the method on Tel Aviv, we are able to reduce times on more than 9\% of the routes. The improved routes included both intraurban and suburban routes showcasing a fact highlighting the model's versatility. The findings emphasize the potential of our data-driven decision support system to enhance public transport and city logistics, promoting greater efficiency and reliability in PT services.
Interruptions detection in video conferences
Feb 25, 2023In recent years, video conferencing (VC) popularity has skyrocketed for a wide range of activities. As a result, the number of VC users surged sharply. The sharp increase in VC usage has been accompanied by various newly emerging privacy and security challenges. VC meetings became a target for various security attacks, such as Zoombombing. Other VC-related challenges also emerged. For example, during COVID lockdowns, educators had to teach in online environments struggling with keeping students engaged for extended periods. In parallel, the amount of available VC videos has grown exponentially. Thus, users and companies are limited in finding abnormal segments in VC meetings within the converging volumes of data. Such abnormal events that affect most meeting participants may be indicators of interesting points in time, including security attacks or other changes in meeting climate, like someone joining a meeting or sharing a dramatic content. Here, we present a novel algorithm for detecting abnormal events in VC data. We curated VC publicly available recordings, including meetings with interruptions. We analyzed the videos using our algorithm, extracting time windows where abnormal occurrences were detected. Our algorithm is a pipeline that combines multiple methods in several steps to detect users' faces in each video frame, track face locations during the meeting and generate vector representations of a facial expression for each face in each frame. Vector representations are used to monitor changes in facial expressions throughout the meeting for each participant. The overall change in meeting climate is quantified using those parameters across all participants, and translating them into event anomaly detection. This is the first open pipeline for automatically detecting anomaly events in VC meetings. Our model detects abnormal events with 92.3% precision over the collected dataset.
Malicious Source Code Detection Using Transformer
Sep 16, 2022



Open source code is considered a common practice in modern software development. However, reusing other code allows bad actors to access a wide developers' community, hence the products that rely on it. Those attacks are categorized as supply chain attacks. Recent years saw a growing number of supply chain attacks that leverage open source during software development, relaying the download and installation procedures, whether automatic or manual. Over the years, many approaches have been invented for detecting vulnerable packages. However, it is uncommon to detect malicious code within packages. Those detection approaches can be broadly categorized as analyzes that use (dynamic) and do not use (static) code execution. Here, we introduce Malicious Source code Detection using Transformers (MSDT) algorithm. MSDT is a novel static analysis based on a deep learning method that detects real-world code injection cases to source code packages. In this study, we used MSDT and a dataset with over 600,000 different functions to embed various functions and applied a clustering algorithm to the resulting vectors, detecting the malicious functions by detecting the outliers. We evaluated MSDT's performance by conducting extensive experiments and demonstrated that our algorithm is capable of detecting functions that were injected with malicious code with precision@k values of up to 0.909.
Co-Membership-based Generic Anomalous Communities Detection
Mar 30, 2022



Nowadays, detecting anomalous communities in networks is an essential task in research, as it helps discover insights into community-structured networks. Most of the existing methods leverage either information regarding attributes of vertices or the topological structure of communities. In this study, we introduce the Co-Membership-based Generic Anomalous Communities Detection Algorithm (referred as to CMMAC), a novel and generic method that utilizes the information of vertices co-membership in multiple communities. CMMAC is domain-free and almost unaffected by communities' sizes and densities. Specifically, we train a classifier to predict the probability of each vertex in a community being a member of the community. We then rank the communities by the aggregated membership probabilities of each community's vertices. The lowest-ranked communities are considered to be anomalous. Furthermore, we present an algorithm for generating a community-structured random network enabling the infusion of anomalous communities to facilitate research in the field. We utilized it to generate two datasets, composed of thousands of labeled anomaly-infused networks, and published them. We experimented extensively on thousands of simulated, and real-world networks, infused with artificial anomalies. CMMAC outperformed other existing methods in a range of settings. Additionally, we demonstrated that CMMAC can identify abnormal communities in real-world unlabeled networks in different domains, such as Reddit and Wikipedia.
CompanyName2Vec: Company Entity Matching Based on Job Ads
Jan 12, 2022



Entity Matching is an essential part of all real-world systems that take in structured and unstructured data coming from different sources. Typically no common key is available for connecting records. Massive data cleaning and integration processes require completion before any data analytics, or further processing can be performed. Although record linkage is frequently regarded as a somewhat tedious but necessary step, it reveals valuable insights, supports data visualization, and guides further analytic approaches to the data. Here, we focus on organization entity matching. We introduce CompanyName2Vec, a novel algorithm to solve company entity matching (CEM) using a neural network model to learn company name semantics from a job ad corpus, without relying on any information on the matched company besides its name. Based on a real-world data, we show that CompanyName2Vec outperforms other evaluated methods and solves the CEM challenge with an average success rate of 89.3%.