 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFake News Data Collection and Classification: Iterative Query Selection for Opaque Search Engines with Pseudo Relevance Feedback
Paper and Code
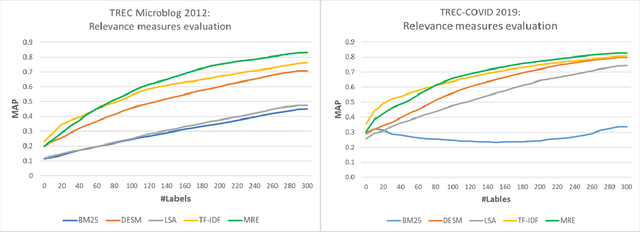
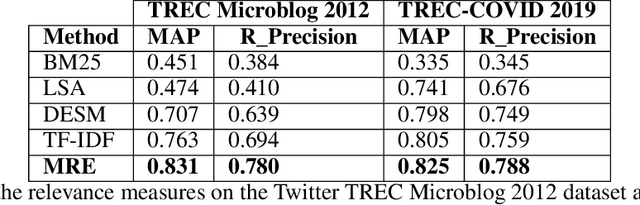
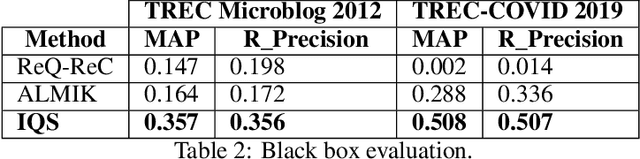
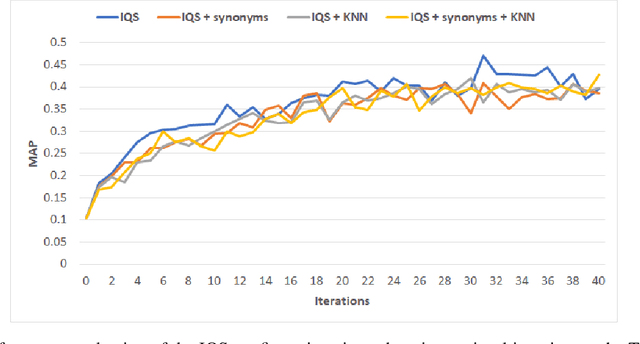
Retrieving information from an online search engine is the first and most important step in many data mining tasks. Most of the search engines currently available on the web, including all social media platforms, are black-boxes (a.k.a opaque) supporting short keyword queries. In these settings, retrieving all posts and comments discussing a particular news item automatically and at large scales is a challenging task. In this paper, we propose a method for generating short keyword queries given a prototype document. The proposed algorithm interacts with the opaque search engine to iteratively improve the query. It is evaluated on the Twitter TREC Microblog 2012 and TREC-COVID 2019 datasets showing superior performance compared to state of the art and is applied to automatically collect large scale dataset for training machine learning classifiers for fake news detection. The classifiers training on 70,000 labeled news items and more than 61 million associated tweets automatically collected using the proposed method obtained impressive performance of AUC and accuracy of 0.92, and 0.86, respectively.