 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Transferable and Automatic Tuning of Deep Reinforcement Learning for Cost Effective Phishing Detection
Sep 19, 2022
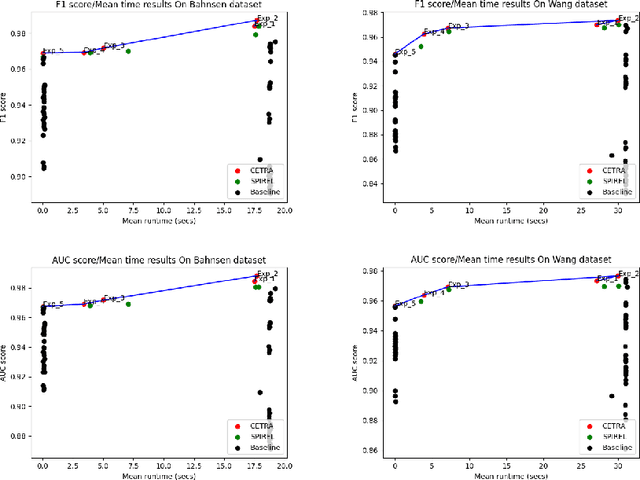

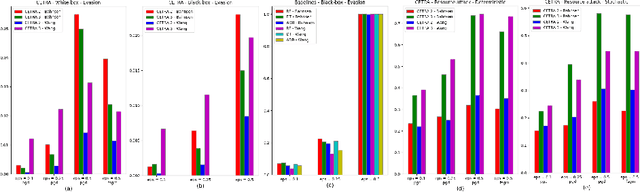
Many challenging real-world problems require the deployment of ensembles multiple complementary learning models to reach acceptable performance levels. While effective, applying the entire ensemble to every sample is costly and often unnecessary. Deep Reinforcement Learning (DRL) offers a cost-effective alternative, where detectors are dynamically chosen based on the output of their predecessors, with their usefulness weighted against their computational cost. Despite their potential, DRL-based solutions are not widely used in this capacity, partly due to the difficulties in configuring the reward function for each new task, the unpredictable reactions of the DRL agent to changes in the data, and the inability to use common performance metrics (e.g., TPR/FPR) to guide the algorithm's performance. In this study we propose methods for fine-tuning and calibrating DRL-based policies so that they can meet multiple performance goals. Moreover, we present a method for transferring effective security policies from one dataset to another. Finally, we demonstrate that our approach is highly robust against adversarial attacks.