 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCluster Frequency Conformal Prediction for Local Coverage
May 24, 2026Conformal prediction provides distribution-free coverage guarantees, but in many-class classification it may still under-cover specific classes or subpopulations, preventing safe deployment in high-stakes applications. We propose Cluster Frequency Conformal Prediction (CFCP), a plug-in framework that adapts conformal prediction to local structure in a learned representation space. CFCP clusters learned embeddings, estimates cluster-level label-frequency distributions from calibration data, and for each test point constructs a sample-specific probability vector by softly mixing nearby cluster distributions regularized with global-prior and reliability-aware shrinkage. This vector is then conformalized using standard set constructors. In the disjoint-split regime, CFCP inherits standard finite-sample marginal validity. Under additional assumptions, CFCP further admits a local-validity interpretation. Since representation clusters aggregate locally similar samples, their empirical class frequencies provide a stable estimate of local label ambiguity. Across image and text benchmarks, CFCP achieves the best class coverage in 15/16 dataset/score-family comparisons and a competitive prediction set size efficiency, with several settings substantially more efficient. Overall, our results show that cluster-frequency information provides an effective localized signal for improving classwise reliability in many-class conformal prediction.
Trajectory-Based Difficulty Scoring for Reliable Learning on Tabular Data
May 23, 2026Gradient-boosted trees achieve strong performance on tabular data, yet often leave a long tail of poorly predicted instances. We introduce a Trajectory-based Difficulty Score (TDS), an instance-level difficulty estimator for boosted ensembles derived from per-tree cumulative prediction trajectories. For each instance, we compute interpretable trajectory descriptors (e.g., variance, oscillation peaks, sign switches, and tail stability) and train a lightweight regression model to predict held-out loss. An empirical CDF calibrates the resulting signal into a score in $[0,1]$ that supports ranking hard cases. Across diverse tabular benchmarks and ensemble sizes, TDS exhibits strong rank correlation with error and outperforms established instance-hardness and uncertainty baselines on classification, while remaining competitive on regression. We then show how a single difficulty signal improves multiple data mining workflows: difficulty-driven active learning for label-efficient training, difficulty-thresholded selective prediction for improved risk-coverage trade-offs, and TDS-stratified (Mondrian) conformal prediction for more uniform conditional coverage. Finally, clustering high-TDS instances using SHAP attributions reveals coherent failure modes characterized by compact feature-value ranges, supporting error analysis and targeted data acquisition.
EncodeRec: An Embedding Backbone for Recommendation Systems
Jan 15, 2026Recent recommender systems increasingly leverage embeddings from large pre-trained language models (PLMs). However, such embeddings exhibit two key limitations: (1) PLMs are not explicitly optimized to produce structured and discriminative embedding spaces, and (2) their representations remain overly generic, often failing to capture the domain-specific semantics crucial for recommendation tasks. We present EncodeRec, an approach designed to align textual representations with recommendation objectives while learning compact, informative embeddings directly from item descriptions. EncodeRec keeps the language model parameters frozen during recommender system training, making it computationally efficient without sacrificing semantic fidelity. Experiments across core recommendation benchmarks demonstrate its effectiveness both as a backbone for sequential recommendation models and for semantic ID tokenization, showing substantial gains over PLM-based and embedding model baselines. These results underscore the pivotal role of embedding adaptation in bridging the gap between general-purpose language models and practical recommender systems.
Calibration and Discrimination Optimization Using Clusters of Learned Representation
Oct 22, 2025Machine learning models are essential for decision-making and risk assessment, requiring highly reliable predictions in terms of both discrimination and calibration. While calibration often receives less attention, it is crucial for critical decisions, such as those in clinical predictions. We introduce a novel calibration pipeline that leverages an ensemble of calibration functions trained on clusters of learned representations of the input samples to enhance overall calibration. This approach not only improves the calibration score of various methods from 82.28% up to 100% but also introduces a unique matching metric that ensures model selection optimizes both discrimination and calibration. Our generic scheme adapts to any underlying representation, clustering, calibration methods and metric, offering flexibility and superior performance across commonly used calibration methods.
X-Cross: Dynamic Integration of Language Models for Cross-Domain Sequential Recommendation
Apr 29, 2025



As new products are emerging daily, recommendation systems are required to quickly adapt to possible new domains without needing extensive retraining. This work presents ``X-Cross'' -- a novel cross-domain sequential-recommendation model that recommends products in new domains by integrating several domain-specific language models; each model is fine-tuned with low-rank adapters (LoRA). Given a recommendation prompt, operating layer by layer, X-Cross dynamically refines the representation of each source language model by integrating knowledge from all other models. These refined representations are propagated from one layer to the next, leveraging the activations from each domain adapter to ensure domain-specific nuances are preserved while enabling adaptability across domains. Using Amazon datasets for sequential recommendation, X-Cross achieves performance comparable to a model that is fine-tuned with LoRA, while using only 25% of the additional parameters. In cross-domain tasks, such as adapting from Toys domain to Tools, Electronics or Sports, X-Cross demonstrates robust performance, while requiring about 50%-75% less fine-tuning data than LoRA to make fine-tuning effective. Furthermore, X-Cross achieves significant improvement in accuracy over alternative cross-domain baselines. Overall, X-Cross enables scalable and adaptive cross-domain recommendations, reducing computational overhead and providing an efficient solution for data-constrained environments.
Forget What You Know about LLMs Evaluations - LLMs are Like a Chameleon
Feb 11, 2025



Large language models (LLMs) often appear to excel on public benchmarks, but these high scores may mask an overreliance on dataset-specific surface cues rather than true language understanding. We introduce the Chameleon Benchmark Overfit Detector (C-BOD), a meta-evaluation framework that systematically distorts benchmark prompts via a parametric transformation and detects overfitting of LLMs. By rephrasing inputs while preserving their semantic content and labels, C-BOD exposes whether a model's performance is driven by memorized patterns. Evaluated on the MMLU benchmark using 26 leading LLMs, our method reveals an average performance degradation of 2.15% under modest perturbations, with 20 out of 26 models exhibiting statistically significant differences. Notably, models with higher baseline accuracy exhibit larger performance differences under perturbation, and larger LLMs tend to be more sensitive to rephrasings indicating that both cases may overrely on fixed prompt patterns. In contrast, the Llama family and models with lower baseline accuracy show insignificant degradation, suggesting reduced dependency on superficial cues. Moreover, C-BOD's dataset- and model-agnostic design allows easy integration into training pipelines to promote more robust language understanding. Our findings challenge the community to look beyond leaderboard scores and prioritize resilience and generalization in LLM evaluation.
DFPE: A Diverse Fingerprint Ensemble for Enhancing LLM Performance
Jan 29, 2025Large Language Models (LLMs) have shown remarkable capabilities across various natural language processing tasks but often struggle to excel uniformly in diverse or complex domains. We propose a novel ensemble method - Diverse Fingerprint Ensemble (DFPE), which leverages the complementary strengths of multiple LLMs to achieve more robust performance. Our approach involves: (1) clustering models based on response "fingerprints" patterns, (2) applying a quantile-based filtering mechanism to remove underperforming models at a per-subject level, and (3) assigning adaptive weights to remaining models based on their subject-wise validation accuracy. In experiments on the Massive Multitask Language Understanding (MMLU) benchmark, DFPE outperforms the best single model by 3% overall accuracy and 5% in discipline-level accuracy. This method increases the robustness and generalization of LLMs and underscores how model selection, diversity preservation, and performance-driven weighting can effectively address challenging, multi-faceted language understanding tasks.
FairTTTS: A Tree Test Time Simulation Method for Fairness-Aware Classification
Jan 14, 2025Algorithmic decision-making has become deeply ingrained in many domains, yet biases in machine learning models can still produce discriminatory outcomes, often harming unprivileged groups. Achieving fair classification is inherently challenging, requiring a careful balance between predictive performance and ethical considerations. We present FairTTTS, a novel post-processing bias mitigation method inspired by the Tree Test Time Simulation (TTTS) method. Originally developed to enhance accuracy and robustness against adversarial inputs through probabilistic decision-path adjustments, TTTS serves as the foundation for FairTTTS. By building on this accuracy-enhancing technique, FairTTTS mitigates bias and improves predictive performance. FairTTTS uses a distance-based heuristic to adjust decisions at protected attribute nodes, ensuring fairness for unprivileged samples. This fairness-oriented adjustment occurs as a post-processing step, allowing FairTTTS to be applied to pre-trained models, diverse datasets, and various fairness metrics without retraining. Extensive evaluation on seven benchmark datasets shows that FairTTTS outperforms traditional methods in fairness improvement, achieving a 20.96% average increase over the baseline compared to 18.78% for related work, and further enhances accuracy by 0.55%. In contrast, competing methods typically reduce accuracy by 0.42%. These results confirm that FairTTTS effectively promotes more equitable decision-making while simultaneously improving predictive performance.
BiasGuard: Guardrailing Fairness in Machine Learning Production Systems
Jan 07, 2025As machine learning (ML) systems increasingly impact critical sectors such as hiring, financial risk assessments, and criminal justice, the imperative to ensure fairness has intensified due to potential negative implications. While much ML fairness research has focused on enhancing training data and processes, addressing the outputs of already deployed systems has received less attention. This paper introduces 'BiasGuard', a novel approach designed to act as a fairness guardrail in production ML systems. BiasGuard leverages Test-Time Augmentation (TTA) powered by Conditional Generative Adversarial Network (CTGAN), a cutting-edge generative AI model, to synthesize data samples conditioned on inverted protected attribute values, thereby promoting equitable outcomes across diverse groups. This method aims to provide equal opportunities for both privileged and unprivileged groups while significantly enhancing the fairness metrics of deployed systems without the need for retraining. Our comprehensive experimental analysis across diverse datasets reveals that BiasGuard enhances fairness by 31% while only reducing accuracy by 0.09% compared to non-mitigated benchmarks. Additionally, BiasGuard outperforms existing post-processing methods in improving fairness, positioning it as an effective tool to safeguard against biases when retraining the model is impractical.
AMFPMC -- An improved method of detecting multiple types of drug-drug interactions using only known drug-drug interactions
Feb 07, 2023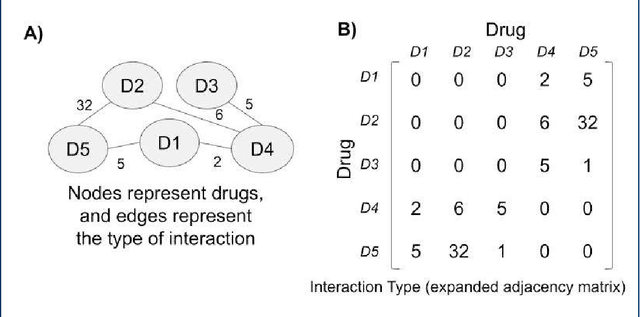

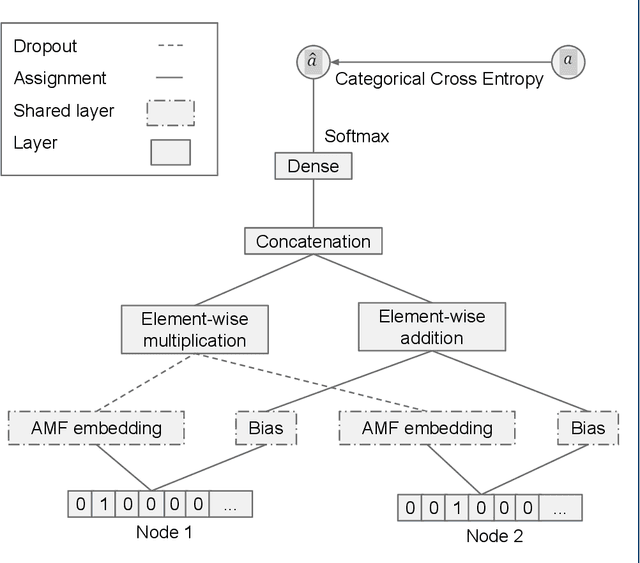

Adverse drug interactions are largely preventable causes of medical accidents, which frequently result in physician and emergency room encounters. The detection of drug interactions in a lab, prior to a drug's use in medical practice, is essential, however it is costly and time-consuming. Machine learning techniques can provide an efficient and accurate means of predicting possible drug-drug interactions and combat the growing problem of adverse drug interactions. Most existing models for predicting interactions rely on the chemical properties of drugs. While such models can be accurate, the required properties are not always available.