 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShrinking Bigfoot: Reducing wav2vec 2.0 footprint
Apr 01, 2021
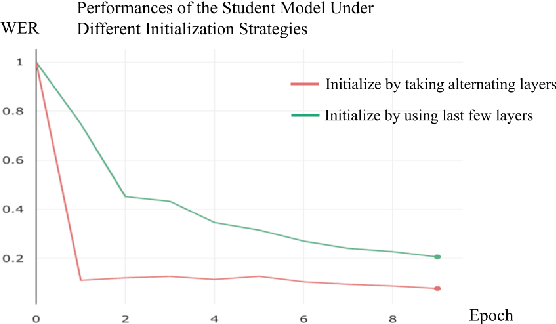
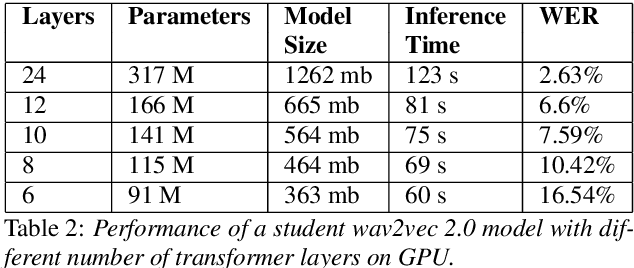
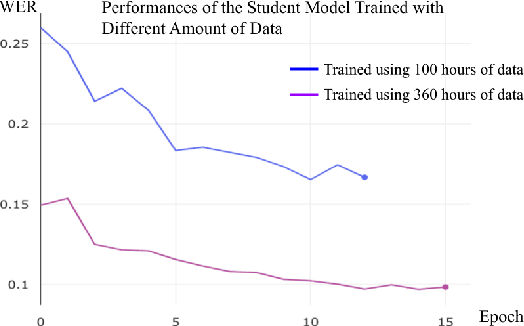
Wav2vec 2.0 is a state-of-the-art speech recognition model which maps speech audio waveforms into latent representations. The largest version of wav2vec 2.0 contains 317 million parameters. Hence, the inference latency of wav2vec 2.0 will be a bottleneck in production, leading to high costs and a significant environmental footprint. To improve wav2vec's applicability to a production setting, we explore multiple model compression methods borrowed from the domain of large language models. Using a teacher-student approach, we distilled the knowledge from the original wav2vec 2.0 model into a student model, which is 2 times faster and 4.8 times smaller than the original model. This increase in performance is accomplished with only a 7% degradation in word error rate (WER). Our quantized model is 3.6 times smaller than the original model, with only a 0.1% degradation in WER. To the best of our knowledge, this is the first work that compresses wav2vec 2.0.
A framework for optimizing COVID-19 testing policy using a Multi Armed Bandit approach
Jul 28, 2020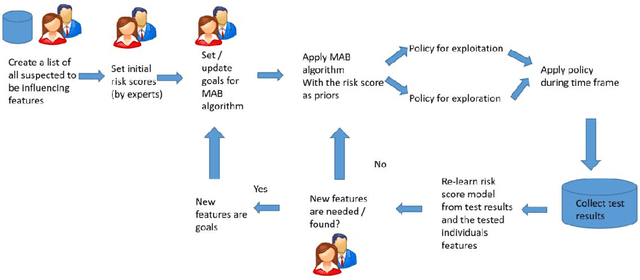

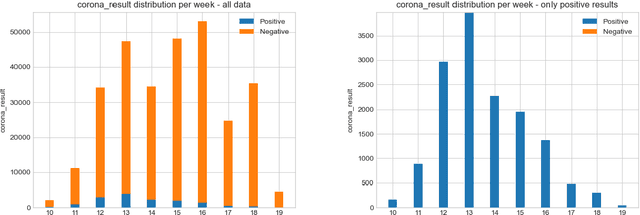

Testing is an important part of tackling the COVID-19 pandemic. Availability of testing is a bottleneck due to constrained resources and effective prioritization of individuals is necessary. Here, we discuss the impact of different prioritization policies on COVID-19 patient discovery and the ability of governments and health organizations to use the results for effective decision making. We suggest a framework for testing that balances the maximal discovery of positive individuals with the need for population-based surveillance aimed at understanding disease spread and characteristics. This framework draws from similar approaches to prioritization in the domain of cyber-security based on ranking individuals using a risk score and then reserving a portion of the capacity for random sampling. This approach is an application of Multi-Armed-Bandits maximizing exploration/exploitation of the underlying distribution. We find that individuals can be ranked for effective testing using a few simple features, and that ranking them using such models we can capture 65% (CI: 64.7%-68.3%) of the positive individuals using less than 20% of the testing capacity or 92.1% (CI: 91.1%-93.2%) of positives individuals using 70% of the capacity, allowing reserving a significant portion of the tests for population studies. Our approach allows experts and decision-makers to tailor the resulting policies as needed allowing transparency into the ranking policy and the ability to understand the disease spread in the population and react quickly and in an informed manner.
Sideways Transliteration: How to Transliterate Multicultural Person Names?
Nov 27, 2019



In a global setting, texts contain transliterated names from many cultural origins. Correct transliteration depends not only on target and source languages but also, on the source language of the name. We introduce a novel methodology for transliteration of names originating in different languages using only monolingual resources. Our method is based on a step of noisy transliteration and then ranking of the results based on origin specific letter models. The transliteration table used for noisy generation is learned in an unsupervised manner for each possible origin language. We present a solution for gathering monolingual training data used by our method by mining of social media sites such as Facebook and Wikipedia. We present results in the context of transliterating from English to Hebrew and provide an online web service for transliteration from English to Hebrew
Multi-Label Classification of Patient Notes a Case Study on ICD Code Assignment
Nov 20, 2017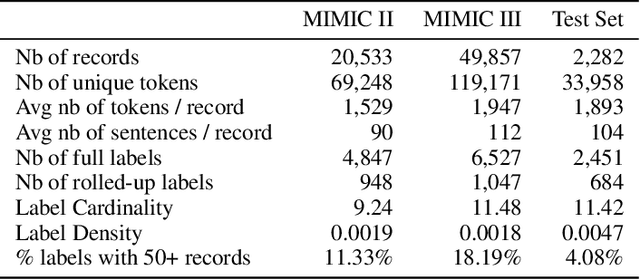
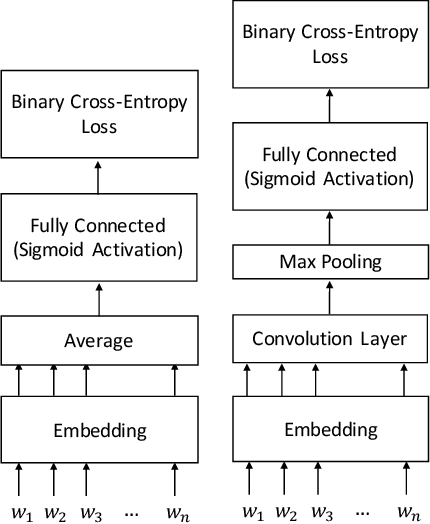

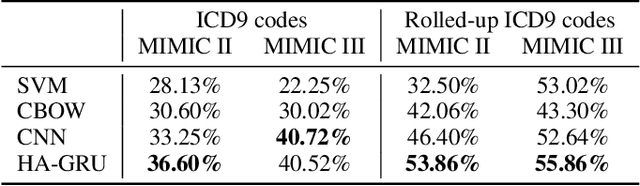
In the context of the Electronic Health Record, automated diagnosis coding of patient notes is a useful task, but a challenging one due to the large number of codes and the length of patient notes. We investigate four models for assigning multiple ICD codes to discharge summaries taken from both MIMIC II and III. We present Hierarchical Attention-GRU (HA-GRU), a hierarchical approach to tag a document by identifying the sentences relevant for each label. HA-GRU achieves state-of-the art results. Furthermore, the learned sentence-level attention layer highlights the model decision process, allows easier error analysis, and suggests future directions for improvement.