 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Parsing for Complex Data Retrieval: Targeting Query Plans vs. SQL for No-Code Access to Relational Databases
Dec 22, 2023Large Language Models (LLMs) have spurred progress in text-to-SQL, the task of generating SQL queries from natural language questions based on a given database schema. Despite the declarative nature of SQL, it continues to be a complex programming language. In this paper, we investigate the potential of an alternative query language with simpler syntax and modular specification of complex queries. The purpose is to create a query language that can be learned more easily by modern neural semantic parsing architectures while also enabling non-programmers to better assess the validity of the query plans produced by an interactive query plan assistant. The proposed alternative query language is called Query Plan Language (QPL). It is designed to be modular and can be translated into a restricted form of SQL Common Table Expressions (CTEs). The aim of QPL is to make complex data retrieval accessible to non-programmers by allowing users to express their questions in natural language while also providing an easier-to-verify target language. The paper demonstrates how neural LLMs can benefit from QPL's modularity to generate complex query plans in a compositional manner. This involves a question decomposition strategy and a planning stage. We conduct experiments on a version of the Spider text-to-SQL dataset that has been converted to QPL. The hierarchical structure of QPL programs enables us to measure query complexity naturally. Based on this assessment, we identify the low accuracy of existing text-to-SQL systems on complex compositional queries. We present ways to address the challenge of complex queries in an iterative, user-controlled manner, using fine-tuned LLMs and a variety of prompting strategies in a compositional manner.
Semantic Decomposition of Question and SQL for Text-to-SQL Parsing
Oct 20, 2023



Text-to-SQL semantic parsing faces challenges in generalizing to cross-domain and complex queries. Recent research has employed a question decomposition strategy to enhance the parsing of complex SQL queries. However, this strategy encounters two major obstacles: (1) existing datasets lack question decomposition; (2) due to the syntactic complexity of SQL, most complex queries cannot be disentangled into sub-queries that can be readily recomposed. To address these challenges, we propose a new modular Query Plan Language (QPL) that systematically decomposes SQL queries into simple and regular sub-queries. We develop a translator from SQL to QPL by leveraging analysis of SQL server query optimization plans, and we augment the Spider dataset with QPL programs. Experimental results demonstrate that the modular nature of QPL benefits existing semantic-parsing architectures, and training text-to-QPL parsers is more effective than text-to-SQL parsing for semantically equivalent queries. The QPL approach offers two additional advantages: (1) QPL programs can be paraphrased as simple questions, which allows us to create a dataset of (complex question, decomposed questions). Training on this dataset, we obtain a Question Decomposer for data retrieval that is sensitive to database schemas. (2) QPL is more accessible to non-experts for complex queries, leading to more interpretable output from the semantic parser.
Emptying the Ocean with a Spoon: Should We Edit Models?
Oct 18, 2023We call into question the recently popularized method of direct model editing as a means of correcting factual errors in LLM generations. We contrast model editing with three similar but distinct approaches that pursue better defined objectives: (1) retrieval-based architectures, which decouple factual memory from inference and linguistic capabilities embodied in LLMs; (2) concept erasure methods, which aim at preventing systemic bias in generated text; and (3) attribution methods, which aim at grounding generations into identified textual sources. We argue that direct model editing cannot be trusted as a systematic remedy for the disadvantages inherent to LLMs, and while it has proven potential in improving model explainability, it opens risks by reinforcing the notion that models can be trusted for factuality. We call for cautious promotion and application of model editing as part of the LLM deployment process, and for responsibly limiting the use cases of LLMs to those not relying on editing as a critical component.
Data Efficient Masked Language Modeling for Vision and Language
Sep 05, 2021


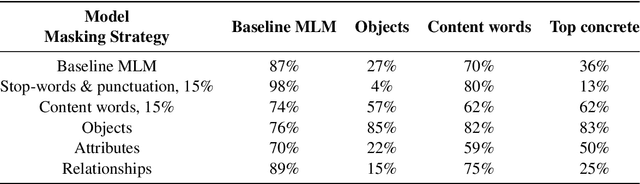
Masked language modeling (MLM) is one of the key sub-tasks in vision-language pretraining. In the cross-modal setting, tokens in the sentence are masked at random, and the model predicts the masked tokens given the image and the text. In this paper, we observe several key disadvantages of MLM in this setting. First, as captions tend to be short, in a third of the sentences no token is sampled. Second, the majority of masked tokens are stop-words and punctuation, leading to under-utilization of the image. We investigate a range of alternative masking strategies specific to the cross-modal setting that address these shortcomings, aiming for better fusion of text and image in the learned representation. When pre-training the LXMERT model, our alternative masking strategies consistently improve over the original masking strategy on three downstream tasks, especially in low resource settings. Further, our pre-training approach substantially outperforms the baseline model on a prompt-based probing task designed to elicit image objects. These results and our analysis indicate that our method allows for better utilization of the training data.
Automatic Generation of Contrast Sets from Scene Graphs: Probing the Compositional Consistency of GQA
Mar 17, 2021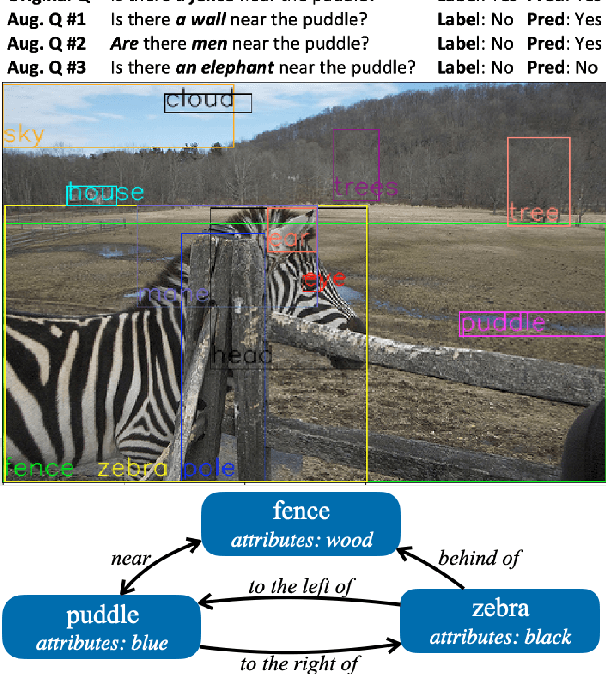



Recent works have shown that supervised models often exploit data artifacts to achieve good test scores while their performance severely degrades on samples outside their training distribution. Contrast sets (Gardneret al., 2020) quantify this phenomenon by perturbing test samples in a minimal way such that the output label is modified. While most contrast sets were created manually, requiring intensive annotation effort, we present a novel method which leverages rich semantic input representation to automatically generate contrast sets for the visual question answering task. Our method computes the answer of perturbed questions, thus vastly reducing annotation cost and enabling thorough evaluation of models' performance on various semantic aspects (e.g., spatial or relational reasoning). We demonstrate the effectiveness of our approach on the GQA dataset and its semantic scene graph image representation. We find that, despite GQA's compositionality and carefully balanced label distribution, two high-performing models drop 13-17% in accuracy compared to the original test set. Finally, we show that our automatic perturbation can be applied to the training set to mitigate the degradation in performance, opening the door to more robust models.
Building a Hebrew Semantic Role Labeling Lexical Resource from Parallel Movie Subtitles
May 17, 2020



We present a semantic role labeling resource for Hebrew built semi-automatically through annotation projection from English. This corpus is derived from the multilingual OpenSubtitles dataset and includes short informal sentences, for which reliable linguistic annotations have been computed. We provide a fully annotated version of the data including morphological analysis, dependency syntax and semantic role labeling in both FrameNet and PropBank styles. Sentences are aligned between English and Hebrew, both sides include full annotations and the explicit mapping from the English arguments to the Hebrew ones. We train a neural SRL model on this Hebrew resource exploiting the pre-trained multilingual BERT transformer model, and provide the first available baseline model for Hebrew SRL as a reference point. The code we provide is generic and can be adapted to other languages to bootstrap SRL resources.
* 9 pages, 7 figures, accepted to LREC 2020
Sideways Transliteration: How to Transliterate Multicultural Person Names?
Nov 27, 2019



In a global setting, texts contain transliterated names from many cultural origins. Correct transliteration depends not only on target and source languages but also, on the source language of the name. We introduce a novel methodology for transliteration of names originating in different languages using only monolingual resources. Our method is based on a step of noisy transliteration and then ranking of the results based on origin specific letter models. The transliteration table used for noisy generation is learned in an unsupervised manner for each possible origin language. We present a solution for gathering monolingual training data used by our method by mining of social media sites such as Facebook and Wikipedia. We present results in the context of transliterating from English to Hebrew and provide an online web service for transliteration from English to Hebrew
Question Answering as an Automatic Evaluation Metric for News Article Summarization
Jun 02, 2019
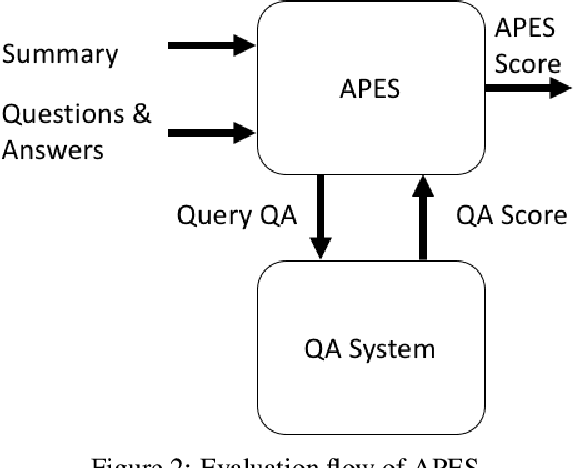

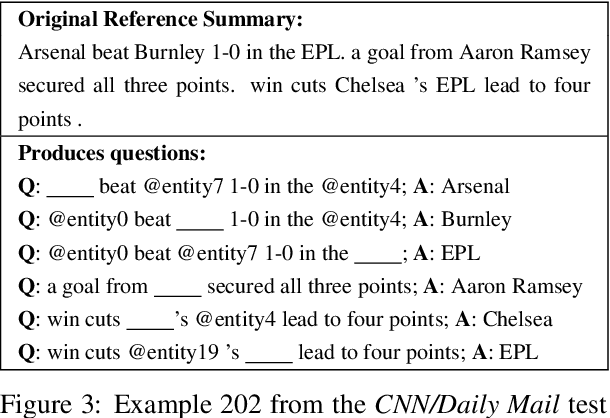
Recent work in the field of automatic summarization and headline generation focuses on maximizing ROUGE scores for various news datasets. We present an alternative, extrinsic, evaluation metric for this task, Answering Performance for Evaluation of Summaries. APES utilizes recent progress in the field of reading-comprehension to quantify the ability of a summary to answer a set of manually created questions regarding central entities in the source article. We first analyze the strength of this metric by comparing it to known manual evaluation metrics. We then present an end-to-end neural abstractive model that maximizes APES, while increasing ROUGE scores to competitive results.
Query Focused Abstractive Summarization: Incorporating Query Relevance, Multi-Document Coverage, and Summary Length Constraints into seq2seq Models
Jan 25, 2018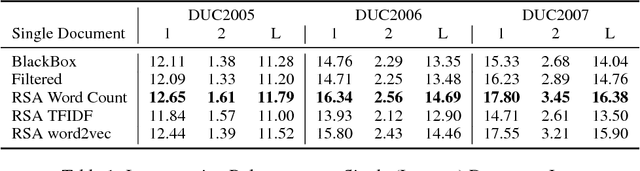
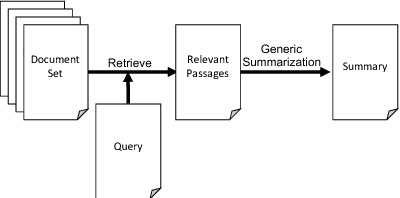

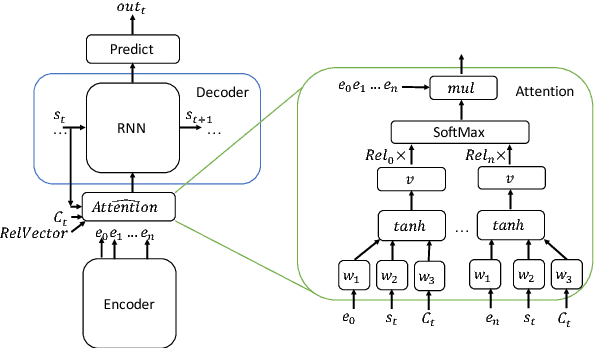
Query Focused Summarization (QFS) has been addressed mostly using extractive methods. Such methods, however, produce text which suffers from low coherence. We investigate how abstractive methods can be applied to QFS, to overcome such limitations. Recent developments in neural-attention based sequence-to-sequence models have led to state-of-the-art results on the task of abstractive generic single document summarization. Such models are trained in an end to end method on large amounts of training data. We address three aspects to make abstractive summarization applicable to QFS: (a)since there is no training data, we incorporate query relevance into a pre-trained abstractive model; (b) since existing abstractive models are trained in a single-document setting, we design an iterated method to embed abstractive models within the multi-document requirement of QFS; (c) the abstractive models we adapt are trained to generate text of specific length (about 100 words), while we aim at generating output of a different size (about 250 words); we design a way to adapt the target size of the generated summaries to a given size ratio. We compare our method (Relevance Sensitive Attention for QFS) to extractive baselines and with various ways to combine abstractive models on the DUC QFS datasets and demonstrate solid improvements on ROUGE performance.
Multi-Label Classification of Patient Notes a Case Study on ICD Code Assignment
Nov 20, 2017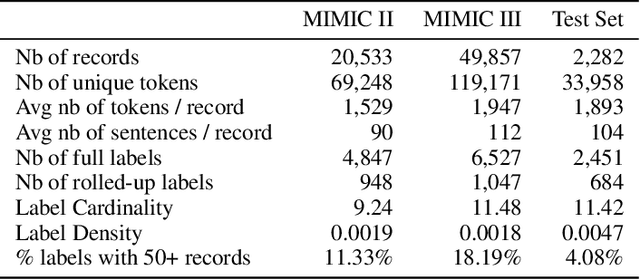
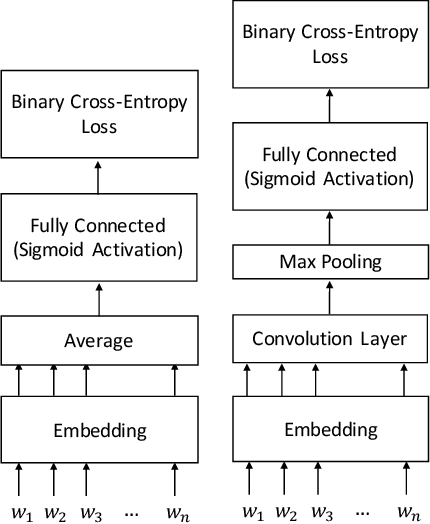

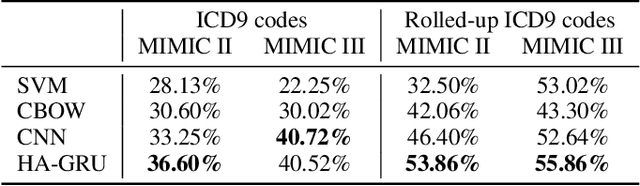
In the context of the Electronic Health Record, automated diagnosis coding of patient notes is a useful task, but a challenging one due to the large number of codes and the length of patient notes. We investigate four models for assigning multiple ICD codes to discharge summaries taken from both MIMIC II and III. We present Hierarchical Attention-GRU (HA-GRU), a hierarchical approach to tag a document by identifying the sentences relevant for each label. HA-GRU achieves state-of-the art results. Furthermore, the learned sentence-level attention layer highlights the model decision process, allows easier error analysis, and suggests future directions for improvement.