 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Generation of Contrast Sets from Scene Graphs: Probing the Compositional Consistency of GQA
Paper and Code
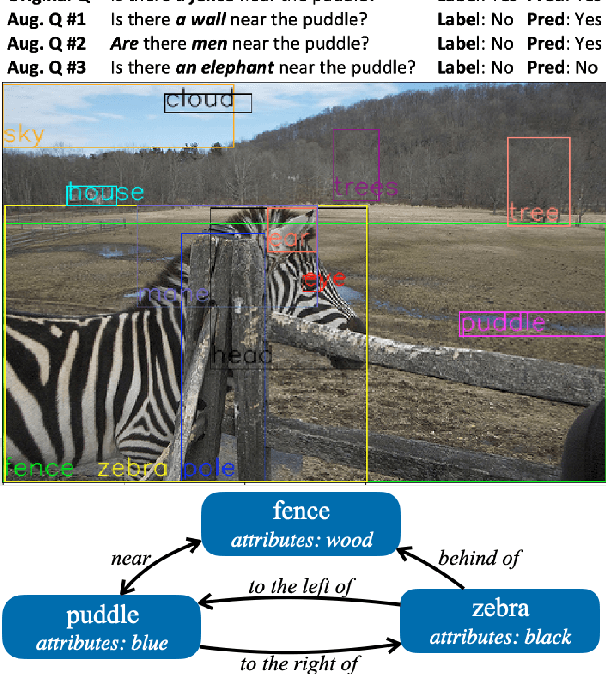



Recent works have shown that supervised models often exploit data artifacts to achieve good test scores while their performance severely degrades on samples outside their training distribution. Contrast sets (Gardneret al., 2020) quantify this phenomenon by perturbing test samples in a minimal way such that the output label is modified. While most contrast sets were created manually, requiring intensive annotation effort, we present a novel method which leverages rich semantic input representation to automatically generate contrast sets for the visual question answering task. Our method computes the answer of perturbed questions, thus vastly reducing annotation cost and enabling thorough evaluation of models' performance on various semantic aspects (e.g., spatial or relational reasoning). We demonstrate the effectiveness of our approach on the GQA dataset and its semantic scene graph image representation. We find that, despite GQA's compositionality and carefully balanced label distribution, two high-performing models drop 13-17% in accuracy compared to the original test set. Finally, we show that our automatic perturbation can be applied to the training set to mitigate the degradation in performance, opening the door to more robust models.