 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Memorization: Distinguishing between Reductive and Epistemic Reasoning in LLMs using Classic Logic Puzzles
Mar 22, 2026Epistemic reasoning requires agents to infer the state of the world from partial observations and information about other agents' knowledge. Prior work evaluating LLMs on canonical epistemic puzzles interpreted their behavior through a dichotomy between epistemic reasoning and brittle memorization. We argue that this framing is incomplete: in recent models, memorization is better understood as a special case of reduction, where a new instance is mapped onto a known problem. Instead, we introduce a reduction ladder, a sequence of modifications that progressively move instances away from a canonical epistemic puzzle, making reduction increasingly difficult while preserving the underlying logic. We find that while some large models succeed via reduction, other models fail early, and all models struggle once epistemic reasoning is required.
Leveraging Digitized Newspapers to Collect Summarization Data in Low-Resource Languages
Nov 18, 2025High quality summarization data remains scarce in under-represented languages. However, historical newspapers, made available through recent digitization efforts, offer an abundant source of untapped, naturally annotated data. In this work, we present a novel method for collecting naturally occurring summaries via Front-Page Teasers, where editors summarize full length articles. We show that this phenomenon is common across seven diverse languages and supports multi-document summarization. To scale data collection, we develop an automatic process, suited to varying linguistic resource levels. Finally, we apply this process to a Hebrew newspaper title, producing HEBTEASESUM, the first dedicated multi-document summarization dataset in Hebrew.
Planted in Pretraining, Swayed by Finetuning: A Case Study on the Origins of Cognitive Biases in LLMs
Jul 09, 2025



Large language models (LLMs) exhibit cognitive biases -- systematic tendencies of irrational decision-making, similar to those seen in humans. Prior work has found that these biases vary across models and can be amplified by instruction tuning. However, it remains unclear if these differences in biases stem from pretraining, finetuning, or even random noise due to training stochasticity. We propose a two-step causal experimental approach to disentangle these factors. First, we finetune models multiple times using different random seeds to study how training randomness affects over $30$ cognitive biases. Second, we introduce \emph{cross-tuning} -- swapping instruction datasets between models to isolate bias sources. This swap uses datasets that led to different bias patterns, directly testing whether biases are dataset-dependent. Our findings reveal that while training randomness introduces some variability, biases are mainly shaped by pretraining: models with the same pretrained backbone exhibit more similar bias patterns than those sharing only finetuning data. These insights suggest that understanding biases in finetuned models requires considering their pretraining origins beyond finetuning effects. This perspective can guide future efforts to develop principled strategies for evaluating and mitigating bias in LLMs.
Time to Talk: LLM Agents for Asynchronous Group Communication in Mafia Games
Jun 05, 2025LLMs are used predominantly in synchronous communication, where a human user and a model communicate in alternating turns. In contrast, many real-world settings are inherently asynchronous. For example, in group chats, online team meetings, or social games, there is no inherent notion of turns; therefore, the decision of when to speak forms a crucial part of the participant's decision making. In this work, we develop an adaptive asynchronous LLM-agent which, in addition to determining what to say, also decides when to say it. To evaluate our agent, we collect a unique dataset of online Mafia games, including both human participants, as well as our asynchronous agent. Overall, our agent performs on par with human players, both in game performance, as well as in its ability to blend in with the other human players. Our analysis shows that the agent's behavior in deciding when to speak closely mirrors human patterns, although differences emerge in message content. We release all our data and code to support and encourage further research for more realistic asynchronous communication between LLM agents. This work paves the way for integration of LLMs into realistic human group settings, from assistance in team discussions to educational and professional environments where complex social dynamics must be navigated.
ReliableEval: A Recipe for Stochastic LLM Evaluation via Method of Moments
May 28, 2025



LLMs are highly sensitive to prompt phrasing, yet standard benchmarks typically report performance using a single prompt, raising concerns about the reliability of such evaluations. In this work, we argue for a stochastic method of moments evaluation over the space of meaning-preserving prompt perturbations. We introduce a formal definition of reliable evaluation that accounts for prompt sensitivity, and suggest ReliableEval - a method for estimating the number of prompt resamplings needed to obtain meaningful results. Using our framework, we stochastically evaluate five frontier LLMs and find that even top-performing models like GPT-4o and Claude-3.7-Sonnet exhibit substantial prompt sensitivity. Our approach is model-, task-, and metric-agnostic, offering a recipe for meaningful and robust LLM evaluation.
Cooking Up Creativity: A Cognitively-Inspired Approach for Enhancing LLM Creativity through Structured Representations
Apr 29, 2025Large Language Models (LLMs) excel at countless tasks, yet struggle with creativity. In this paper, we introduce a novel approach that couples LLMs with structured representations and cognitively inspired manipulations to generate more creative and diverse ideas. Our notion of creativity goes beyond superficial token-level variations; rather, we explicitly recombine structured representations of existing ideas, allowing our algorithm to effectively explore the more abstract landscape of ideas. We demonstrate our approach in the culinary domain with DishCOVER, a model that generates creative recipes. Experiments comparing our model's results to those of GPT-4o show greater diversity. Domain expert evaluations reveal that our outputs, which are mostly coherent and feasible culinary creations, significantly surpass GPT-4o in terms of novelty, thus outperforming it in creative generation. We hope our work inspires further research into structured creativity in AI.
More Documents, Same Length: Isolating the Challenge of Multiple Documents in RAG
Mar 06, 2025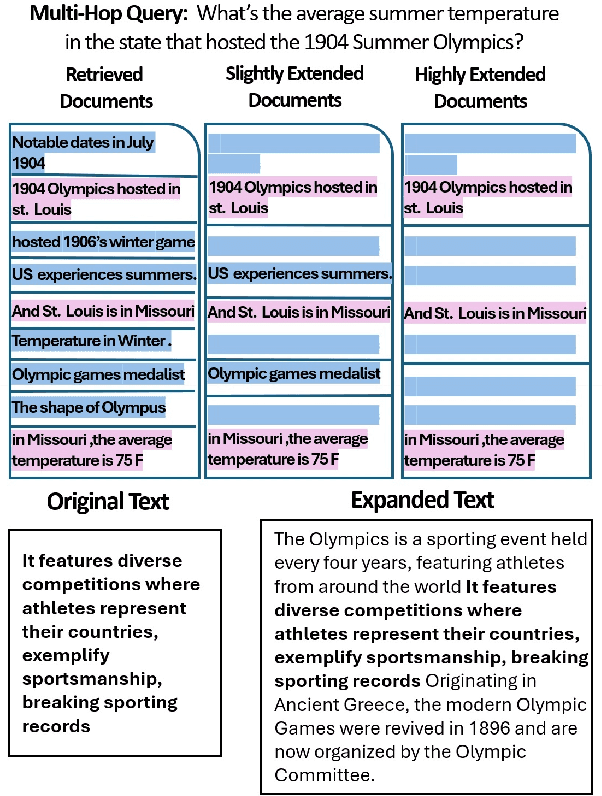


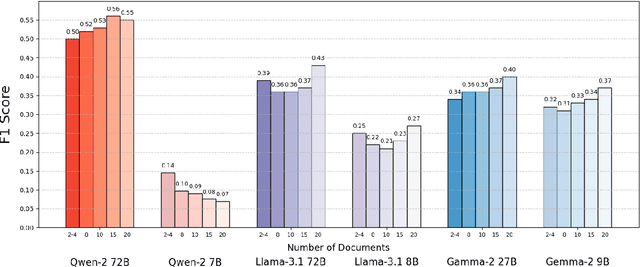
Retrieval-augmented generation (RAG) provides LLMs with relevant documents. Although previous studies noted that retrieving many documents can degrade performance, they did not isolate how the quantity of documents affects performance while controlling for context length. We evaluate various language models on custom datasets derived from a multi-hop QA task. We keep the context length and position of relevant information constant while varying the number of documents, and find that increasing the document count in RAG settings poses significant challenges for LLMs. Additionally, our results indicate that processing multiple documents is a separate challenge from handling long contexts. We also make the datasets and code available: https://github.com/shaharl6000/MoreDocsSameLen .
DOVE: A Large-Scale Multi-Dimensional Predictions Dataset Towards Meaningful LLM Evaluation
Mar 04, 2025Recent work found that LLMs are sensitive to a wide range of arbitrary prompt dimensions, including the type of delimiters, answer enumerators, instruction wording, and more. This throws into question popular single-prompt evaluation practices. We present DOVE (Dataset Of Variation Evaluation) a large-scale dataset containing prompt perturbations of various evaluation benchmarks. In contrast to previous work, we examine LLM sensitivity from an holistic perspective, and assess the joint effects of perturbations along various dimensions, resulting in thousands of perturbations per instance. We evaluate several model families against DOVE, leading to several findings, including efficient methods for choosing well-performing prompts, observing that few-shot examples reduce sensitivity, and identifying instances which are inherently hard across all perturbations. DOVE consists of more than 250M prompt perturbations and model outputs, which we make publicly available to spur a community-wide effort toward meaningful, robust, and efficient evaluation. Browse the data, contribute, and more: https://slab-nlp.github.io/DOVE/
Seeing the Forest for the Trees: A Large Scale, Continuously Updating Meta-Analysis of Frontier LLMs
Feb 26, 2025The surge of LLM studies makes synthesizing their findings challenging. Meta-analysis can uncover important trends across studies, but its use is limited by the time-consuming nature of manual data extraction. Our study presents a semi-automated approach for meta-analysis that accelerates data extraction using LLMs. It automatically identifies relevant arXiv papers, extracts experimental results and related attributes, and organizes them into a structured dataset. We conduct a comprehensive meta-analysis of frontier LLMs using an automatically extracted dataset, reducing the effort of paper surveying and data extraction by more than 93\% compared to manual approaches. We validate our dataset by showing that it reproduces key findings from a recent manual meta-analysis about Chain-of-Thought (CoT), and also uncovers new insights that go beyond it, showing for example that in-context examples benefit multimodal tasks but offer limited gains in mathematical tasks compared to CoT. Our automatically updatable dataset enables continuous tracking of target models by extracting evaluation studies as new data becomes available. Through our scientific artifacts and empirical analysis, we provide novel insights into LLMs while facilitating ongoing meta-analyses of their behavior.
WildFrame: Comparing Framing in Humans and LLMs on Naturally Occurring Texts
Feb 24, 2025



Humans are influenced by how information is presented, a phenomenon known as the framing effect. Previous work has shown that LLMs may also be susceptible to framing but has done so on synthetic data and did not compare to human behavior. We introduce WildFrame, a dataset for evaluating LLM responses to positive and negative framing, in naturally-occurring sentences, and compare humans on the same data. WildFrame consists of 1,000 texts, first selecting real-world statements with clear sentiment, then reframing them in either positive or negative light, and lastly, collecting human sentiment annotations. By evaluating eight state-of-the-art LLMs on WildFrame, we find that all models exhibit framing effects similar to humans ($r\geq0.57$), with both humans and models being more influenced by positive rather than negative reframing. Our findings benefit model developers, who can either harness framing or mitigate its effects, depending on the downstream application.