 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDidactic to Constructive: Turning Expert Solutions into Learnable Reasoning
Feb 02, 2026Improving the reasoning capabilities of large language models (LLMs) typically relies either on the model's ability to sample a correct solution to be reinforced or on the existence of a stronger model able to solve the problem. However, many difficult problems remain intractable for even current frontier models, preventing the extraction of valid training signals. A promising alternative is to leverage high-quality expert human solutions, yet naive imitation of this data fails because it is fundamentally out of distribution: expert solutions are typically didactic, containing implicit reasoning gaps intended for human readers rather than computational models. Furthermore, high-quality expert solutions are expensive, necessitating generalizable sample-efficient training methods. We propose Distribution Aligned Imitation Learning (DAIL), a two-step method that bridges the distributional gap by first transforming expert solutions into detailed, in-distribution reasoning traces and then applying a contrastive objective to focus learning on expert insights and methodologies. We find that DAIL can leverage fewer than 1000 high-quality expert solutions to achieve 10-25% pass@k gains on Qwen2.5-Instruct and Qwen3 models, improve reasoning efficiency by 2x to 4x, and enable out-of-domain generalization.
Design and Development of a Locomotion Interface for Virtual Reality Lower-Body Haptic Interaction
Mar 03, 2025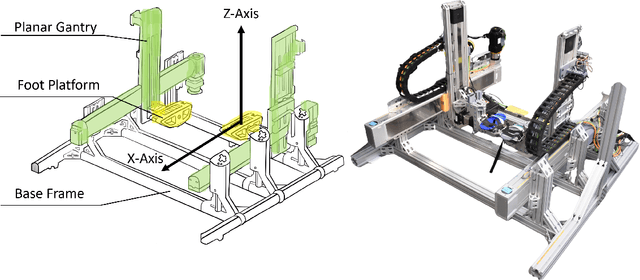

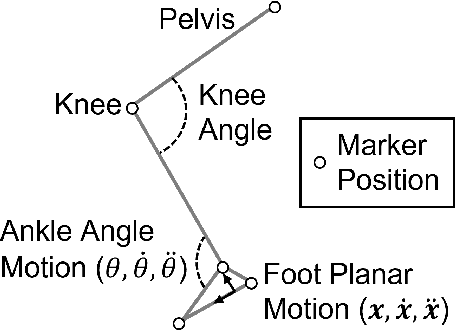
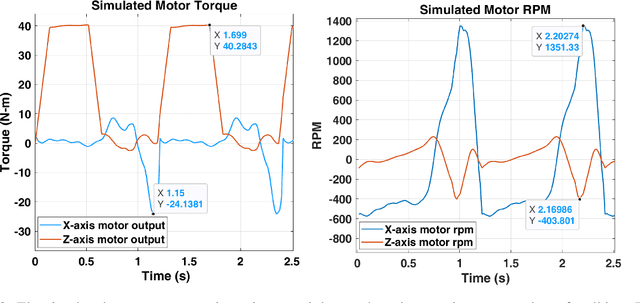
This work presents the design, build, control, and preliminary user data of a locomotion interface called ForceBot. It delivers lower-body haptic interaction in virtual reality (VR), enabling users to walk in VR while interacting with various simulated terrains. It utilizes two planar gantries to give each foot two degrees of freedom and passive heel-lifting motion. The design used motion capture data with dynamic simulation for ergonomic human-robot workspace and hardware selection. Its system framework uses open-source robotic software and pairs with a custom-built power delivery system that offers EtherCAT communication with a 1,000 Hz soft real-time computation rate. This system features an admittance controller to regulate physical human-robot interaction (pHRI) alongside a walking algorithm to generate walking motion and simulate virtual terrains. The system's performance is explored through three measurements that evaluate the relationship between user input force and output pHRI motion. Overall, this platform presents a unique approach by utilizing planar gantries to realize VR terrain interaction with an extensive workspace, reasonably compact footprint, and preliminary user data.
Seeing the Forest for the Trees: A Large Scale, Continuously Updating Meta-Analysis of Frontier LLMs
Feb 26, 2025The surge of LLM studies makes synthesizing their findings challenging. Meta-analysis can uncover important trends across studies, but its use is limited by the time-consuming nature of manual data extraction. Our study presents a semi-automated approach for meta-analysis that accelerates data extraction using LLMs. It automatically identifies relevant arXiv papers, extracts experimental results and related attributes, and organizes them into a structured dataset. We conduct a comprehensive meta-analysis of frontier LLMs using an automatically extracted dataset, reducing the effort of paper surveying and data extraction by more than 93\% compared to manual approaches. We validate our dataset by showing that it reproduces key findings from a recent manual meta-analysis about Chain-of-Thought (CoT), and also uncovers new insights that go beyond it, showing for example that in-context examples benefit multimodal tasks but offer limited gains in mathematical tasks compared to CoT. Our automatically updatable dataset enables continuous tracking of target models by extracting evaluation studies as new data becomes available. Through our scientific artifacts and empirical analysis, we provide novel insights into LLMs while facilitating ongoing meta-analyses of their behavior.
HyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
TeSS: Zero-Shot Classification via Textual Similarity Comparison with Prompting using Sentence Encoder
Dec 20, 2022We introduce TeSS (Text Similarity Comparison using Sentence Encoder), a framework for zero-shot classification where the assigned label is determined by the embedding similarity between the input text and each candidate label prompt. We leverage representations from sentence encoders optimized to locate semantically similar samples closer to each other in embedding space during pre-training. The label prompt embeddings serve as prototypes of their corresponding class clusters. Furthermore, to compensate for the potentially poorly descriptive labels in their original format, we retrieve semantically similar sentences from external corpora and additionally use them with the original label prompt (TeSS-R). TeSS outperforms strong baselines on various closed-set and open-set classification datasets under zero-shot setting, with further gains when combined with label prompt diversification through retrieval. These results are robustly attained to verbalizer variations, an ancillary benefit of using a bi-encoder. Altogether, our method serves as a reliable baseline for zero-shot classification and a simple interface to assess the quality of sentence encoders.
Refining Query Representations for Dense Retrieval at Test Time
May 25, 2022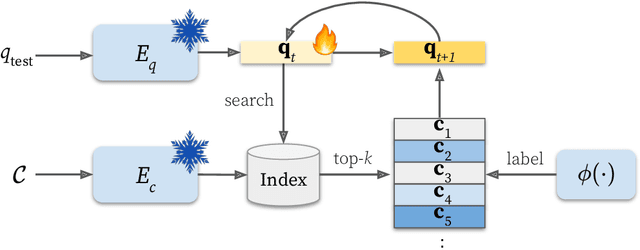
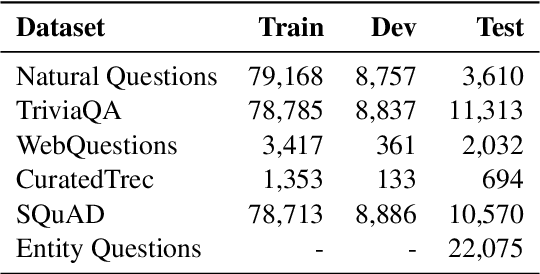
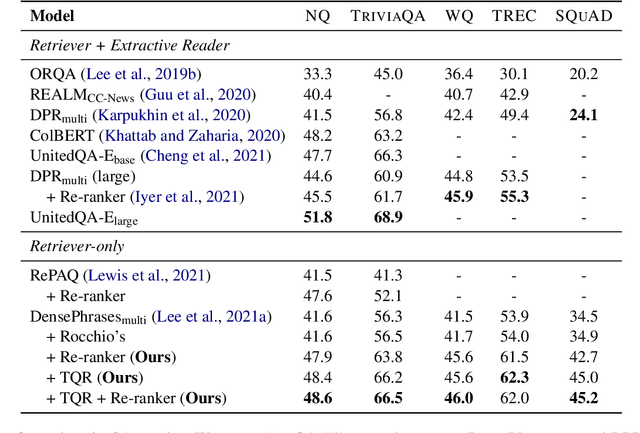
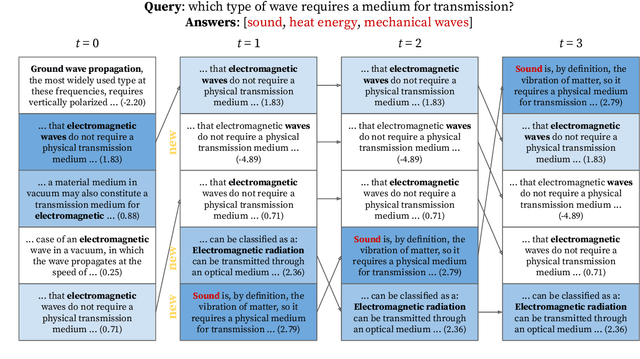
Dense retrieval uses a contrastive learning framework to learn dense representations of queries and contexts. Trained encoders are directly used for each test query, but they often fail to accurately represent out-of-domain queries. In this paper, we introduce a framework that refines instance-level query representations at test time, with only the signals coming from the intermediate retrieval results. We optimize the query representation based on the retrieval result similar to pseudo relevance feedback (PRF) in information retrieval. Specifically, we adopt a cross-encoder labeler to provide pseudo labels over the retrieval result and iteratively refine the query representation with a gradient descent method, treating each test query as a single data point to train on. Our theoretical analysis reveals that our framework can be viewed as a generalization of the classical Rocchio's algorithm for PRF, which leads us to propose interesting variants of our method. We show that our test-time query refinement strategy improves the performance of phrase retrieval (+8.1% Acc@1) and passage retrieval (+3.7% Acc@20) for open-domain QA with large improvements on out-of-domain queries.
FaVIQ: FAct Verification from Information-seeking Questions
Jul 05, 2021

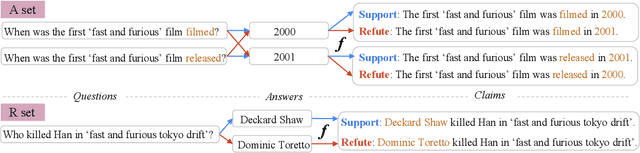

Despite significant interest in developing general purpose fact checking models, it is challenging to construct a large-scale fact verification dataset with realistic claims that would occur in the real world. Existing claims are either authored by crowdworkers, thereby introducing subtle biases that are difficult to control for, or manually verified by professional fact checkers, causing them to be expensive and limited in scale. In this paper, we construct a challenging, realistic, and large-scale fact verification dataset called FaVIQ, using information-seeking questions posed by real users who do not know how to answer. The ambiguity in information-seeking questions enables automatically constructing true and false claims that reflect confusions arisen from users (e.g., the year of the movie being filmed vs. being released). Our claims are verified to be natural, contain little lexical bias, and require a complete understanding of the evidence for verification. Our experiments show that the state-of-the-art models are far from solving our new task. Moreover, training on our data helps in professional fact-checking, outperforming models trained on the most widely used dataset FEVER or in-domain data by up to 17% absolute. Altogether, our data will serve as a challenging benchmark for natural language understanding and support future progress in professional fact checking.
Learn to Resolve Conversational Dependency: A Consistency Training Framework for Conversational Question Answering
Jun 22, 2021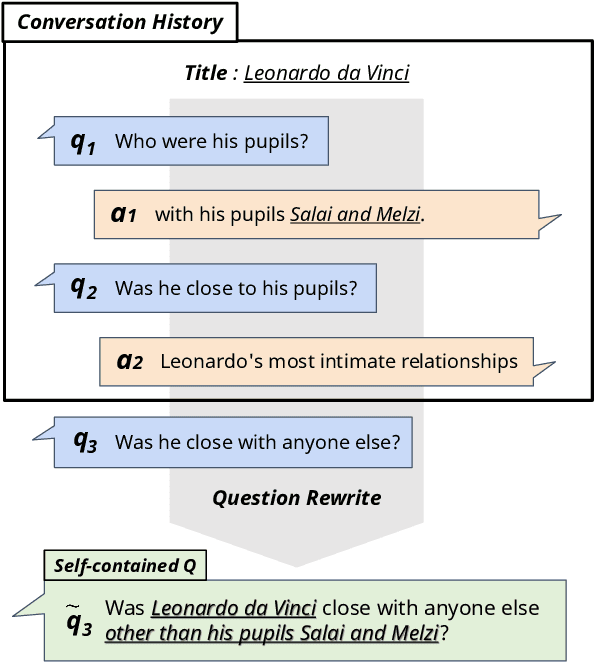
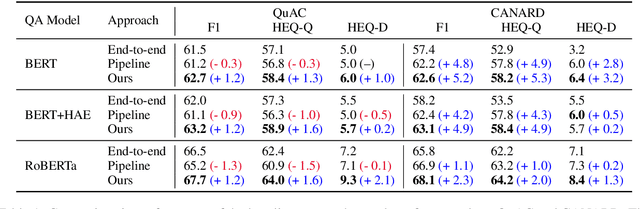
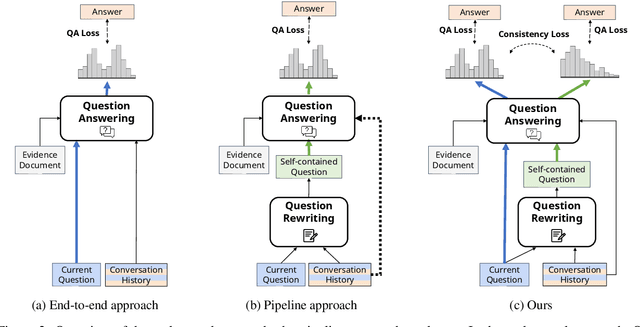
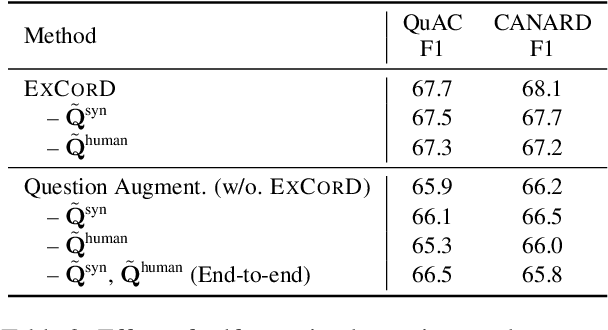
One of the main challenges in conversational question answering (CQA) is to resolve the conversational dependency, such as anaphora and ellipsis. However, existing approaches do not explicitly train QA models on how to resolve the dependency, and thus these models are limited in understanding human dialogues. In this paper, we propose a novel framework, ExCorD (Explicit guidance on how to resolve Conversational Dependency) to enhance the abilities of QA models in comprehending conversational context. ExCorD first generates self-contained questions that can be understood without the conversation history, then trains a QA model with the pairs of original and self-contained questions using a consistency-based regularizer. In our experiments, we demonstrate that ExCorD significantly improves the QA models' performance by up to 1.2 F1 on QuAC, and 5.2 F1 on CANARD, while addressing the limitations of the existing approaches.
Consistency Training with Virtual Adversarial Discrete Perturbation
Apr 15, 2021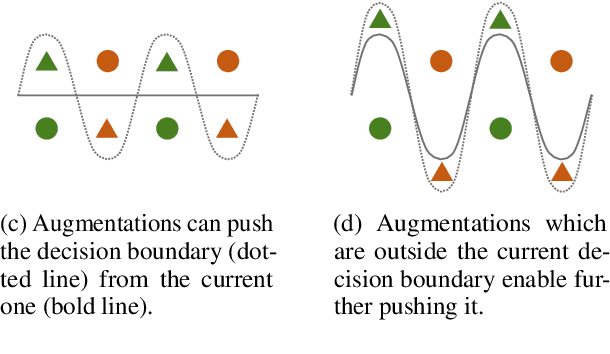
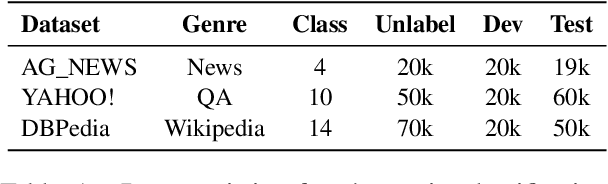
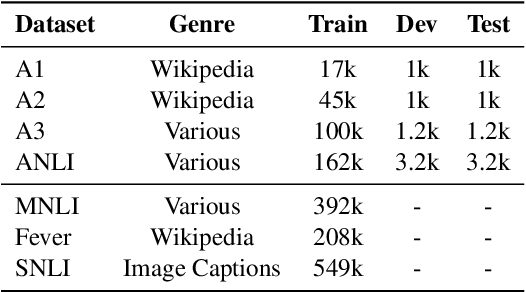
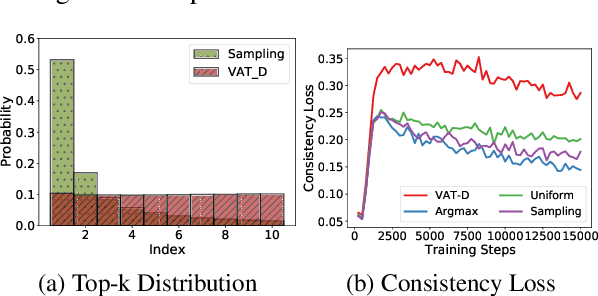
We propose an effective consistency training framework that enforces a training model's predictions given original and perturbed inputs to be similar by adding a discrete noise that would incur the highest divergence between predictions. This virtual adversarial discrete noise obtained by replacing a small portion of tokens while keeping original semantics as much as possible efficiently pushes a training model's decision boundary. Moreover, we perform an iterative refinement process to alleviate the degraded fluency of the perturbed sentence due to the conditional independence assumption. Experimental results show that our proposed method outperforms other consistency training baselines with text editing, paraphrasing, or a continuous noise on semi-supervised text classification tasks and a robustness benchmark.
Adversarial Subword Regularization for Robust Neural Machine Translation
Apr 29, 2020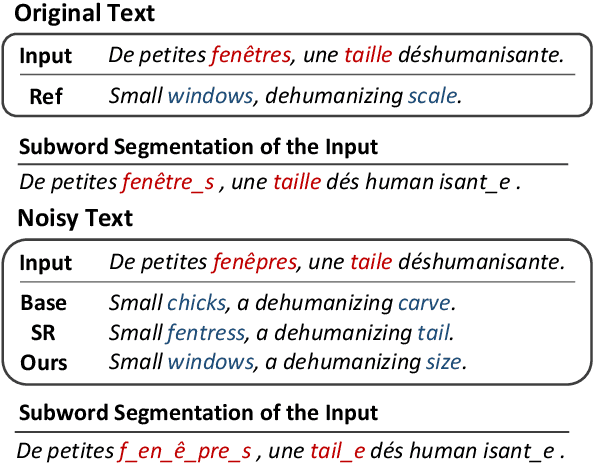

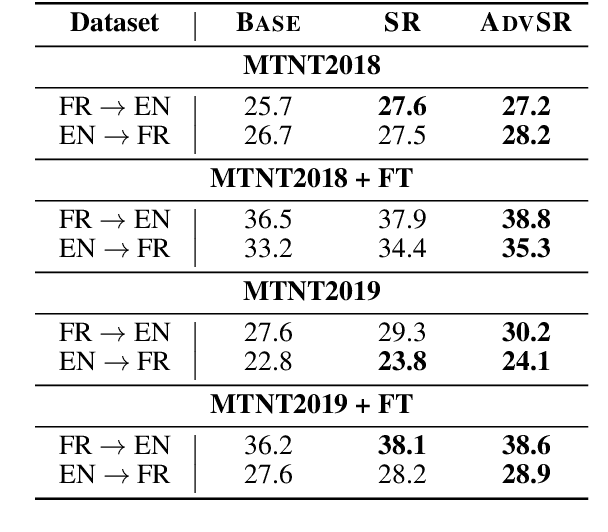
Exposing diverse subword segmentations to neural machine translation (NMT) models often improves the robustness of machine translation. As NMT models experience various subword candidates, they become more robust to segmentation errors. However, the distribution of subword segmentations heavily relies on the subword language models from which erroneous segmentations of unseen words are less likely to be sampled. In this paper, we present adversarial subword regularization (ADVSR) to study whether gradient signals during training can be a substitute criterion for choosing segmentation among candidates. We experimentally show that our model-based adversarial samples effectively encourage NMT models to be less sensitive to segmentation errors and improve the robustness of NMT models in low-resource datasets.