 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDSAI: Unbiased and Interpretable Latent Feature Extraction for Data-Centric AI
Dec 09, 2024



Large language models (LLMs) often struggle to objectively identify latent characteristics in large datasets due to their reliance on pre-trained knowledge rather than actual data patterns. To address this data grounding issue, we propose Data Scientist AI (DSAI), a framework that enables unbiased and interpretable feature extraction through a multi-stage pipeline with quantifiable prominence metrics for evaluating extracted features. On synthetic datasets with known ground-truth features, DSAI demonstrates high recall in identifying expert-defined features while faithfully reflecting the underlying data. Applications on real-world datasets illustrate the framework's practical utility in uncovering meaningful patterns with minimal expert oversight, supporting use cases such as interpretable classification. The title of our paper is chosen from multiple candidates based on DSAI-generated criteria.
Navigating the Path of Writing: Outline-guided Text Generation with Large Language Models
Apr 22, 2024



Large Language Models (LLMs) have significantly impacted the writing process, enabling collaborative content creation and enhancing productivity. However, generating high-quality, user-aligned text remains challenging. In this paper, we propose Writing Path, a framework that uses explicit outlines to guide LLMs in generating goal-oriented, high-quality pieces of writing. Our approach draws inspiration from structured writing planning and reasoning paths, focusing on capturing and reflecting user intentions throughout the writing process. We construct a diverse dataset from unstructured blog posts to benchmark writing performance and introduce a comprehensive evaluation framework assessing the quality of outlines and generated texts. Our evaluations with GPT-3.5-turbo, GPT-4, and HyperCLOVA X demonstrate that the Writing Path approach significantly enhances text quality according to both LLMs and human evaluations. This study highlights the potential of integrating writing-specific techniques into LLMs to enhance their ability to meet the diverse writing needs of users.
TeSS: Zero-Shot Classification via Textual Similarity Comparison with Prompting using Sentence Encoder
Dec 20, 2022
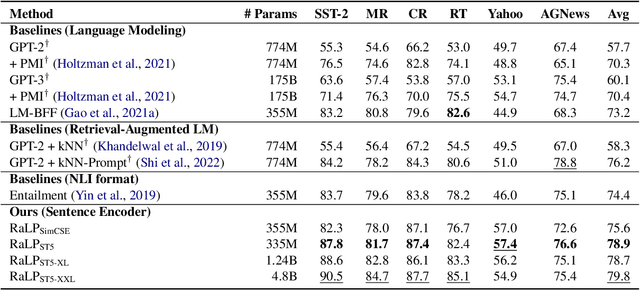
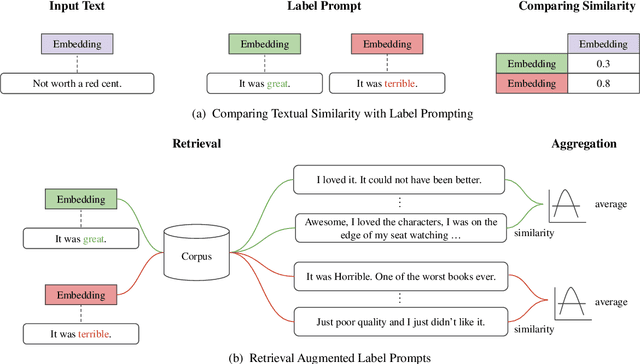

We introduce TeSS (Text Similarity Comparison using Sentence Encoder), a framework for zero-shot classification where the assigned label is determined by the embedding similarity between the input text and each candidate label prompt. We leverage representations from sentence encoders optimized to locate semantically similar samples closer to each other in embedding space during pre-training. The label prompt embeddings serve as prototypes of their corresponding class clusters. Furthermore, to compensate for the potentially poorly descriptive labels in their original format, we retrieve semantically similar sentences from external corpora and additionally use them with the original label prompt (TeSS-R). TeSS outperforms strong baselines on various closed-set and open-set classification datasets under zero-shot setting, with further gains when combined with label prompt diversification through retrieval. These results are robustly attained to verbalizer variations, an ancillary benefit of using a bi-encoder. Altogether, our method serves as a reliable baseline for zero-shot classification and a simple interface to assess the quality of sentence encoders.
ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision
Feb 05, 2021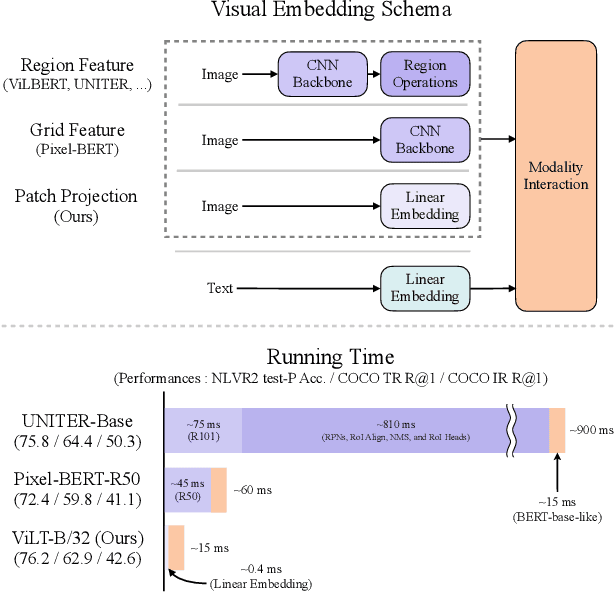
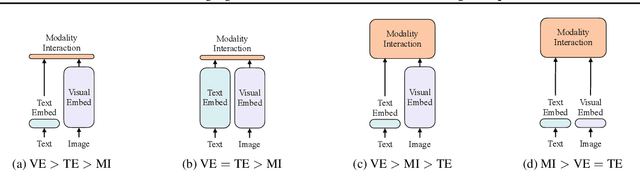
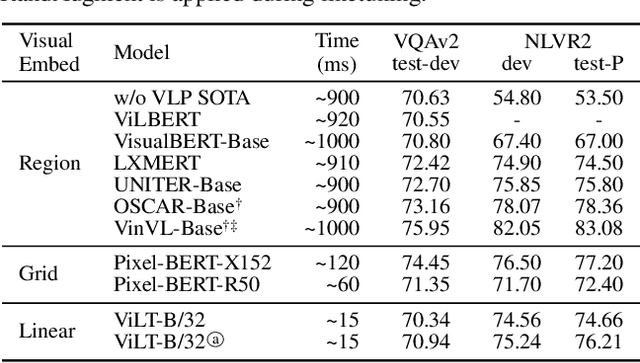
Vision-and-Language Pretraining (VLP) has improved performance on various joint vision-and-language downstream tasks. Current approaches for VLP heavily rely on image feature extraction processes, most of which involve region supervisions (e.g., object detection) and the convolutional architecture (e.g., ResNet). Although disregarded in the literature, we find it problematic in terms of both (1) efficiency/speed, that simply extracting input features requires much more computation than the actual multimodal interaction steps; and (2) expressive power, as it is upper bounded to the expressive power of the visual encoder and its predefined visual vocabulary. In this paper, we present a minimal VLP model, Vision-and-Language Transformer (ViLT), monolithic in the sense that processing of visual inputs is drastically simplified to just the same convolution-free manner that we process textual inputs. We show that ViLT is up to 60 times faster than previous VLP models, yet with competitive or better downstream task performance.
Revisiting Modularized Multilingual NMT to Meet Industrial Demands
Oct 19, 2020
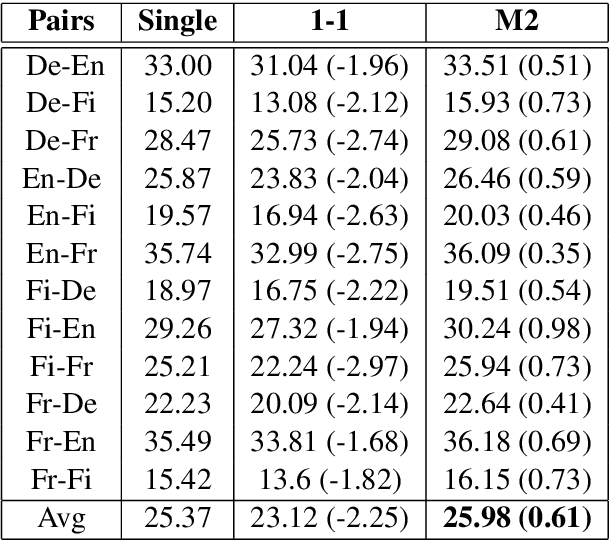
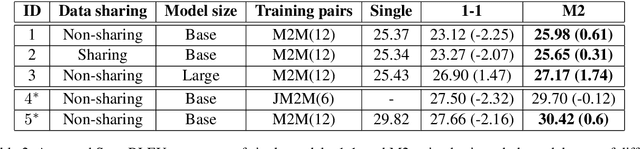
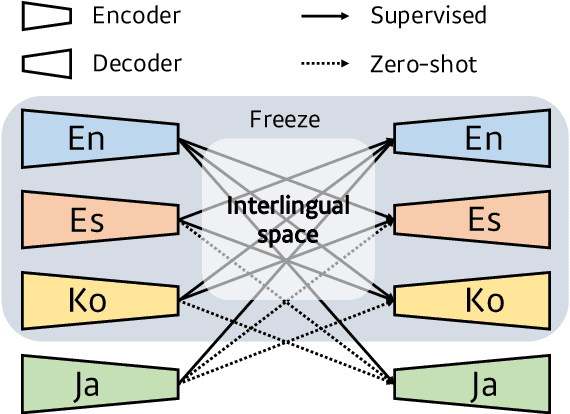
The complete sharing of parameters for multilingual translation (1-1) has been the mainstream approach in current research. However, degraded performance due to the capacity bottleneck and low maintainability hinders its extensive adoption in industries. In this study, we revisit the multilingual neural machine translation model that only share modules among the same languages (M2) as a practical alternative to 1-1 to satisfy industrial requirements. Through comprehensive experiments, we identify the benefits of multi-way training and demonstrate that the M2 can enjoy these benefits without suffering from the capacity bottleneck. Furthermore, the interlingual space of the M2 allows convenient modification of the model. By leveraging trained modules, we find that incrementally added modules exhibit better performance than singly trained models. The zero-shot performance of the added modules is even comparable to supervised models. Our findings suggest that the M2 can be a competent candidate for multilingual translation in industries.