 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
TeSS: Zero-Shot Classification via Textual Similarity Comparison with Prompting using Sentence Encoder
Dec 20, 2022We introduce TeSS (Text Similarity Comparison using Sentence Encoder), a framework for zero-shot classification where the assigned label is determined by the embedding similarity between the input text and each candidate label prompt. We leverage representations from sentence encoders optimized to locate semantically similar samples closer to each other in embedding space during pre-training. The label prompt embeddings serve as prototypes of their corresponding class clusters. Furthermore, to compensate for the potentially poorly descriptive labels in their original format, we retrieve semantically similar sentences from external corpora and additionally use them with the original label prompt (TeSS-R). TeSS outperforms strong baselines on various closed-set and open-set classification datasets under zero-shot setting, with further gains when combined with label prompt diversification through retrieval. These results are robustly attained to verbalizer variations, an ancillary benefit of using a bi-encoder. Altogether, our method serves as a reliable baseline for zero-shot classification and a simple interface to assess the quality of sentence encoders.
CareCall: a Call-Based Active Monitoring Dialog Agent for Managing COVID-19 Pandemic
Jul 06, 2020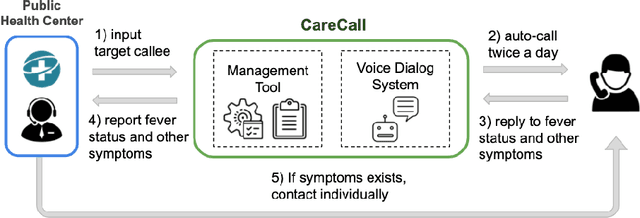
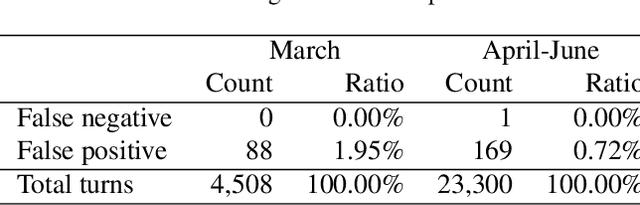
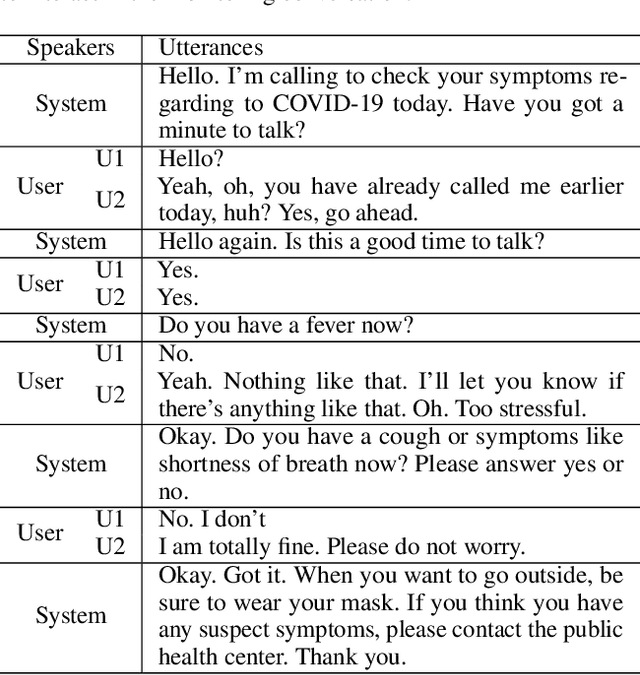
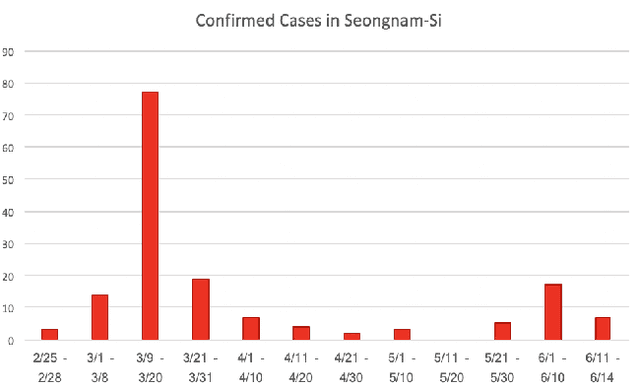
Tracking suspected cases of COVID-19 is crucial to suppressing the spread of COVID-19 pandemic. Active monitoring and proactive inspection are indispensable to mitigate COVID-19 spread, though these require considerable social and economic expense. To address this issue, we introduce CareCall, a call-based dialog agent which is deployed for active monitoring in Korea and Japan. We describe our system with a case study with statistics to show how the system works. Finally, we discuss a simple idea which uses CareCall to support proactive inspection.