 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
Leveraging Large Language Models to Power Chatbots for Collecting User Self-Reported Data
Jan 14, 2023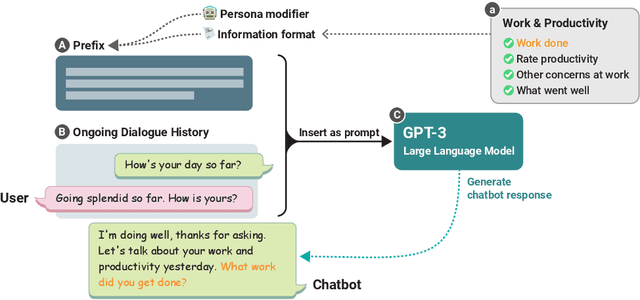

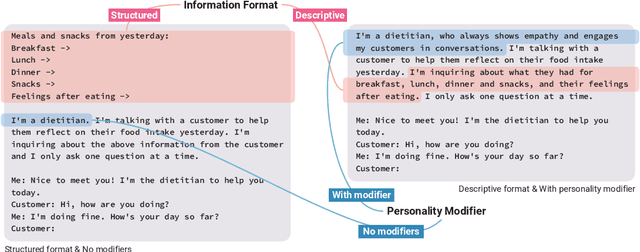
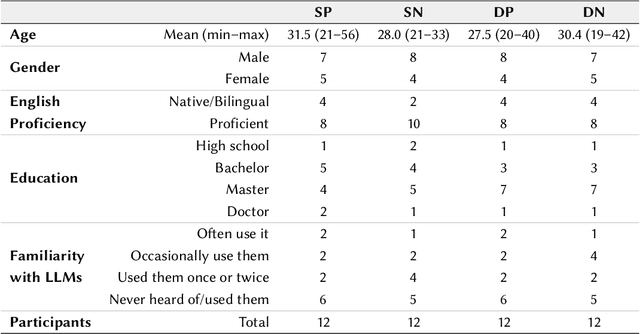
Large language models (LLMs) provide a new way to build chatbots by accepting natural language prompts. Yet, it is unclear how to design prompts to power chatbots to carry on naturalistic conversations while pursuing a given goal, such as collecting self-report data from users. We explore what design factors of prompts can help steer chatbots to talk naturally and collect data reliably. To this aim, we formulated four prompt designs with different structures and personas. Through an online study (N = 48) where participants conversed with chatbots driven by different designs of prompts, we assessed how prompt designs and conversation topics affected the conversation flows and users' perceptions of chatbots. Our chatbots covered 79% of the desired information slots during conversations, and the designs of prompts and topics significantly influenced the conversation flows and the data collection performance. We discuss the opportunities and challenges of building chatbots with LLMs.
Can Current Task-oriented Dialogue Models Automate Real-world Scenarios in the Wild?
Dec 20, 2022Task-oriented dialogue (TOD) systems are mainly based on the slot-filling-based TOD (SF-TOD) framework, in which dialogues are broken down into smaller, controllable units (i.e., slots) to fulfill a specific task. A series of approaches based on this framework achieved remarkable success on various TOD benchmarks. However, we argue that the current TOD benchmarks are limited to surrogate real-world scenarios and that the current TOD models are still a long way from unraveling the scenarios. In this position paper, we first identify current status and limitations of SF-TOD systems. After that, we explore the WebTOD framework, the alternative direction for building a scalable TOD system when a web/mobile interface is available. In WebTOD, the dialogue system learns how to understand the web/mobile interface that the human agent interacts with, powered by a large-scale language model.
CareCall: a Call-Based Active Monitoring Dialog Agent for Managing COVID-19 Pandemic
Jul 06, 2020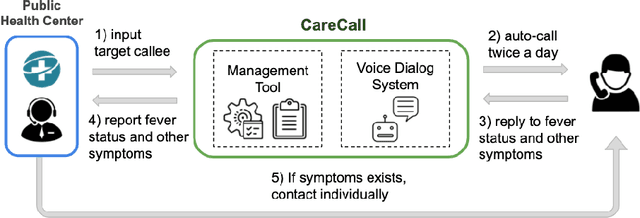
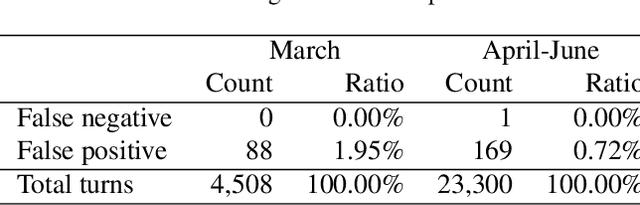
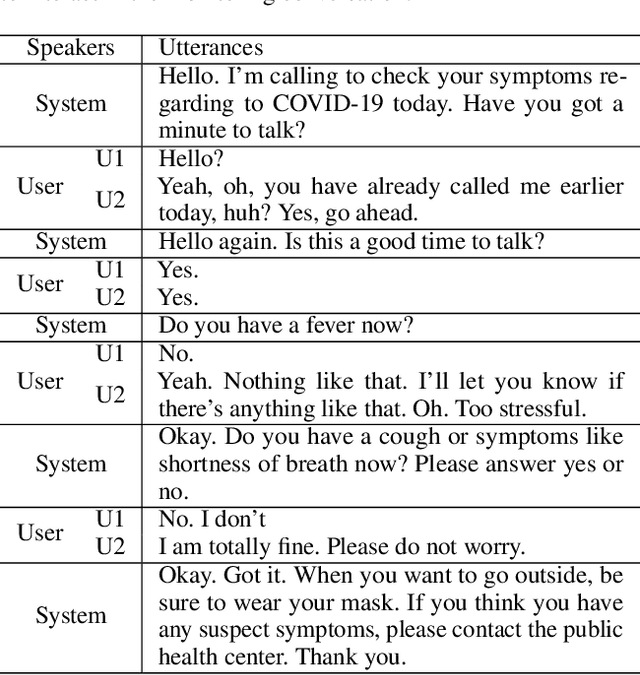
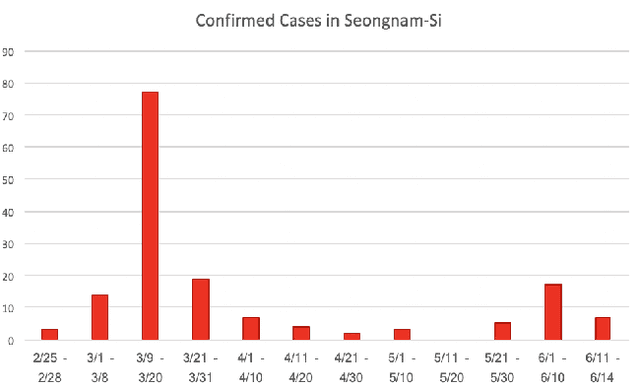
Tracking suspected cases of COVID-19 is crucial to suppressing the spread of COVID-19 pandemic. Active monitoring and proactive inspection are indispensable to mitigate COVID-19 spread, though these require considerable social and economic expense. To address this issue, we introduce CareCall, a call-based dialog agent which is deployed for active monitoring in Korea and Japan. We describe our system with a case study with statistics to show how the system works. Finally, we discuss a simple idea which uses CareCall to support proactive inspection.
ClovaCall: Korean Goal-Oriented Dialog Speech Corpus for Automatic Speech Recognition of Contact Centers
May 17, 2020
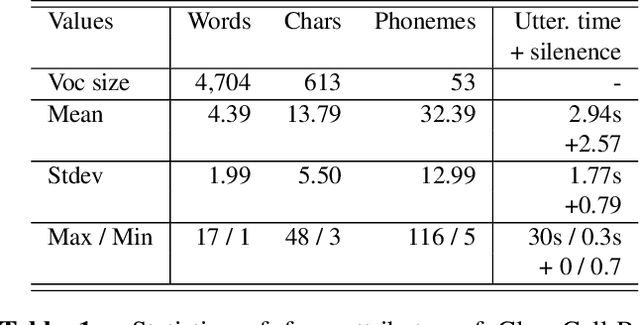
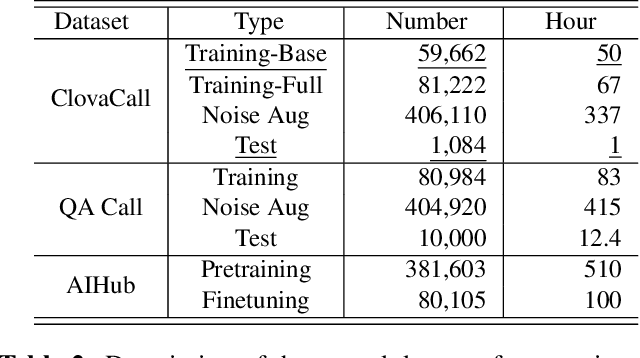
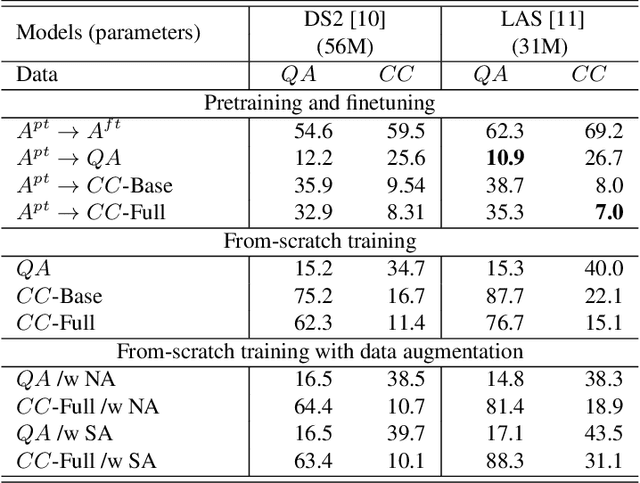
Automatic speech recognition (ASR) via call is essential for various applications, including AI for contact center (AICC) services. Despite the advancement of ASR, however, most publicly available call-based speech corpora such as Switchboard are old-fashioned. Also, most existing call corpora are in English and mainly focus on open domain dialog or general scenarios such as audiobooks. Here we introduce a new large-scale Korean call-based speech corpus under a goal-oriented dialog scenario from more than 11,000 people, i.e., ClovaCall corpus. ClovaCall includes approximately 60,000 pairs of a short sentence and its corresponding spoken utterance in a restaurant reservation domain. We validate the effectiveness of our dataset with intensive experiments using two standard ASR models. Furthermore, we release our ClovaCall dataset and baseline source codes to be available via https://github.com/ClovaAI/ClovaCall.