 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised curriculum learning for speaker verification
Apr 05, 2022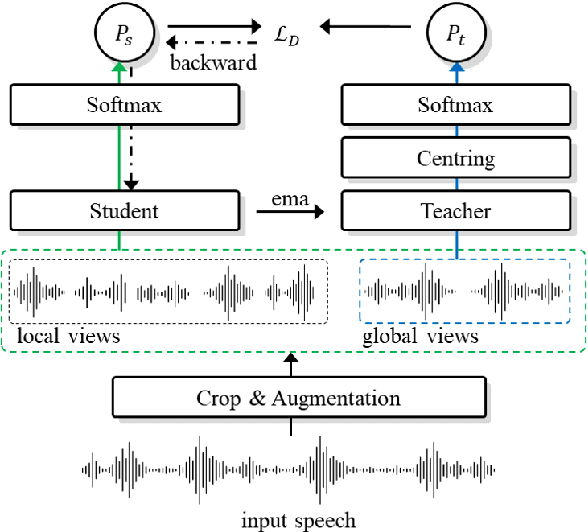
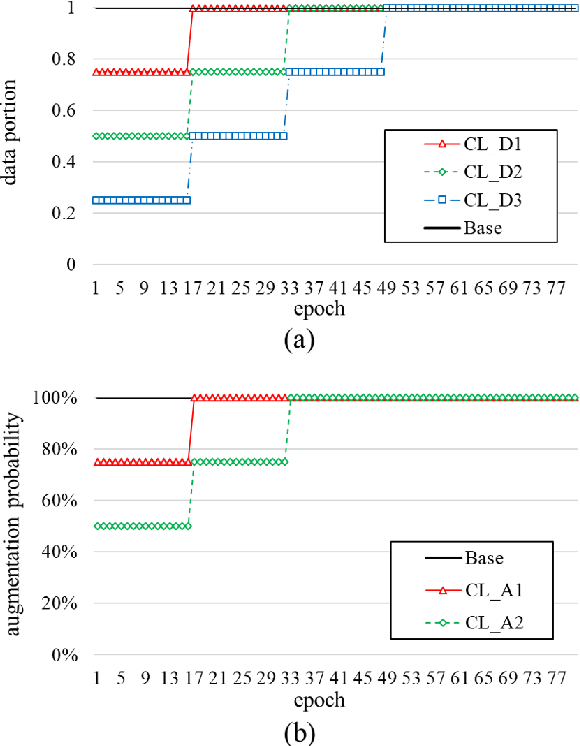
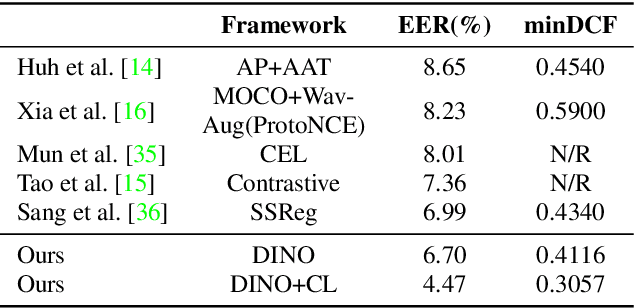
Self-supervised learning is one of the emerging approaches to machine learning today, and has been successfully applied to vision, speech and natural processing tasks. There is a range of frameworks within self-supervised learning literature, but the speaker recognition literature has particularly adopted self-supervision via contrastive loss functions. Our work adapts the DINO framework for speaker recognition, in which the model is trained without exploiting negative utterance pairs. We introduce a curriculum learning strategy to the self-supervised framework, which guides effective training of speaker recognition models. In particular, we propose two curriculum strategies where one gradually increases the number of speakers in training dataset, and the other gradually applies augmentations to more utterances within a mini-batch as the training proceeds. A range of experiments conducted on the VoxCeleb1 evaluation protocol demonstrate the effectiveness of both the DINO framework on speaker verification and our proposed curriculum learning strategies. We report the state-of-the-art equal error rate of 4.47% with a single-phase training.
Layer Pruning on Demand with Intermediate CTC
Jun 17, 2021
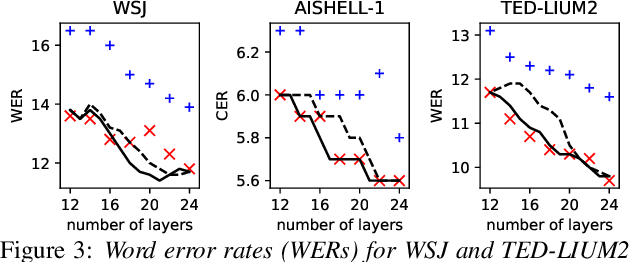
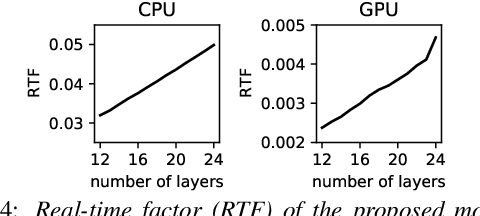
Deploying an end-to-end automatic speech recognition (ASR) model on mobile/embedded devices is a challenging task, since the device computational power and energy consumption requirements are dynamically changed in practice. To overcome the issue, we present a training and pruning method for ASR based on the connectionist temporal classification (CTC) which allows reduction of model depth at run-time without any extra fine-tuning. To achieve the goal, we adopt two regularization methods, intermediate CTC and stochastic depth, to train a model whose performance does not degrade much after pruning. We present an in-depth analysis of layer behaviors using singular vector canonical correlation analysis (SVCCA), and efficient strategies for finding layers which are safe to prune. Using the proposed method, we show that a Transformer-CTC model can be pruned in various depth on demand, improving real-time factor from 0.005 to 0.002 on GPU, while each pruned sub-model maintains the accuracy of individually trained model of the same depth.
Dynamic CT Reconstruction from Limited Views with Implicit Neural Representations and Parametric Motion Fields
Apr 23, 2021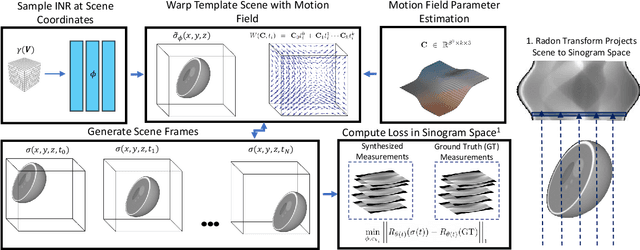
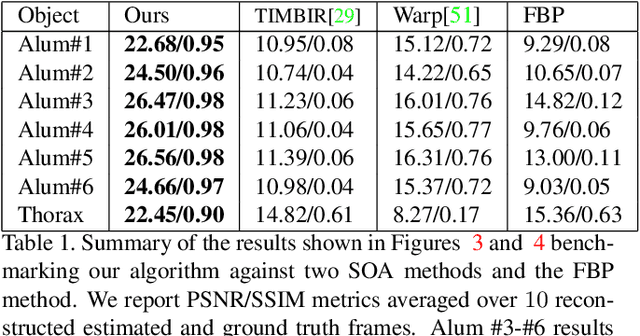
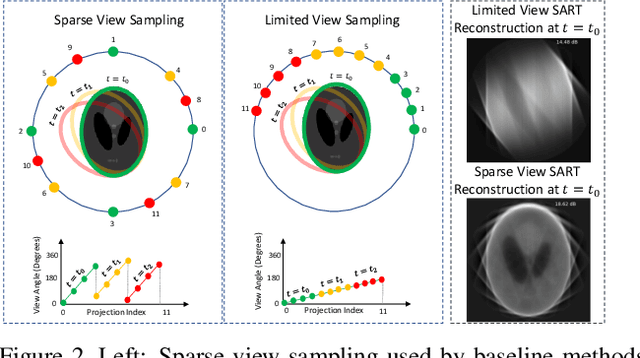

Reconstructing dynamic, time-varying scenes with computed tomography (4D-CT) is a challenging and ill-posed problem common to industrial and medical settings. Existing 4D-CT reconstructions are designed for sparse sampling schemes that require fast CT scanners to capture multiple, rapid revolutions around the scene in order to generate high quality results. However, if the scene is moving too fast, then the sampling occurs along a limited view and is difficult to reconstruct due to spatiotemporal ambiguities. In this work, we design a reconstruction pipeline using implicit neural representations coupled with a novel parametric motion field warping to perform limited view 4D-CT reconstruction of rapidly deforming scenes. Importantly, we utilize a differentiable analysis-by-synthesis approach to compare with captured x-ray sinogram data in a self-supervised fashion. Thus, our resulting optimization method requires no training data to reconstruct the scene. We demonstrate that our proposed system robustly reconstructs scenes containing deformable and periodic motion and validate against state-of-the-art baselines. Further, we demonstrate an ability to reconstruct continuous spatiotemporal representations of our scenes and upsample them to arbitrary volumes and frame rates post-optimization. This research opens a new avenue for implicit neural representations in computed tomography reconstruction in general.
Augmentation adversarial training for unsupervised speaker recognition
Aug 09, 2020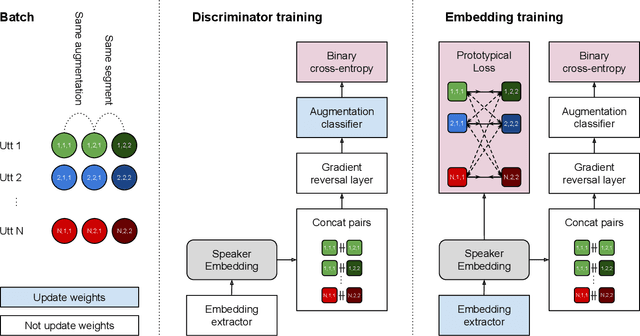

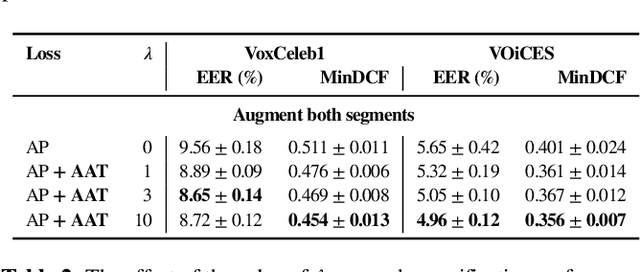
The goal of this work is to train robust speaker recognition models without speaker labels. Recent works on unsupervised speaker representations are based on contrastive learning in which they encourage within-utterance embeddings to be similar and across-utterance embeddings to be dissimilar. However, since the within-utterance segments share the same acoustic characteristics, it is difficult to separate the speaker information from the channel information. To this end, we propose augmentation adversarial training strategy that trains the network to be discriminative for the speaker information, while invariant to the augmentation applied. Since the augmentation simulates the acoustic characteristics, training the network to be invariant to augmentation also encourages the network to be invariant to the channel information in general. Extensive experiments on the VoxCeleb and VOiCES datasets show significant improvements over previous works using self-supervision, and the performance of our self-supervised models far exceed that of humans.
ClovaCall: Korean Goal-Oriented Dialog Speech Corpus for Automatic Speech Recognition of Contact Centers
May 17, 2020
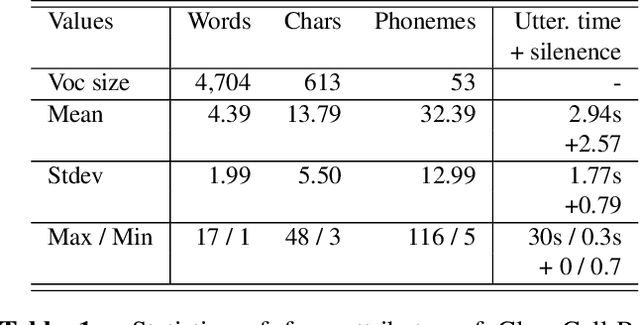
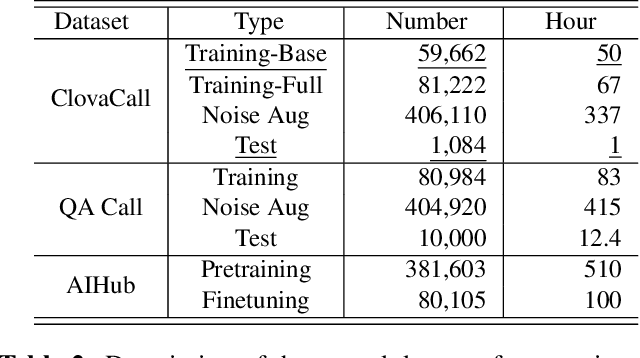
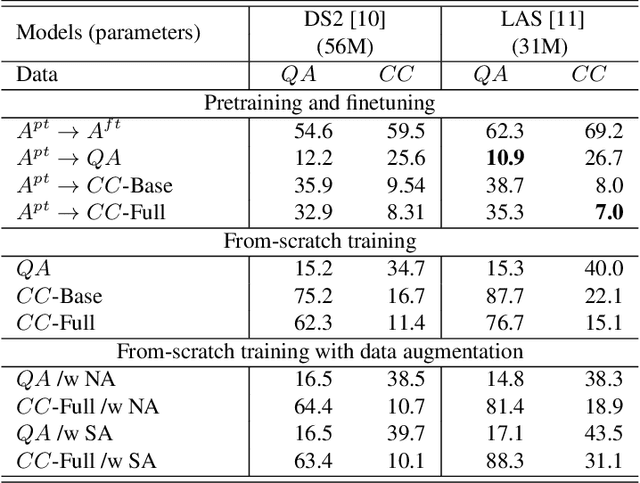
Automatic speech recognition (ASR) via call is essential for various applications, including AI for contact center (AICC) services. Despite the advancement of ASR, however, most publicly available call-based speech corpora such as Switchboard are old-fashioned. Also, most existing call corpora are in English and mainly focus on open domain dialog or general scenarios such as audiobooks. Here we introduce a new large-scale Korean call-based speech corpus under a goal-oriented dialog scenario from more than 11,000 people, i.e., ClovaCall corpus. ClovaCall includes approximately 60,000 pairs of a short sentence and its corresponding spoken utterance in a restaurant reservation domain. We validate the effectiveness of our dataset with intensive experiments using two standard ASR models. Furthermore, we release our ClovaCall dataset and baseline source codes to be available via https://github.com/ClovaAI/ClovaCall.
Deep Learning Reconstruction for 9-View Dual Energy CT Baggage Scanner
Jan 04, 2018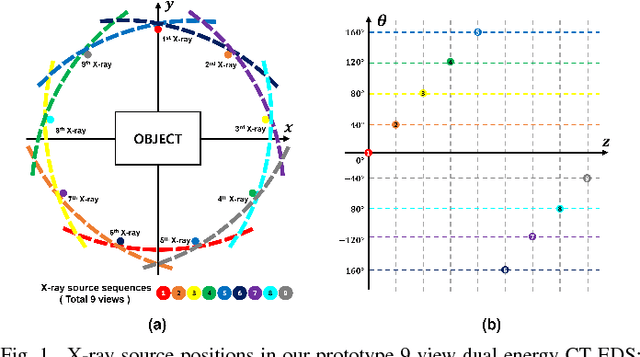

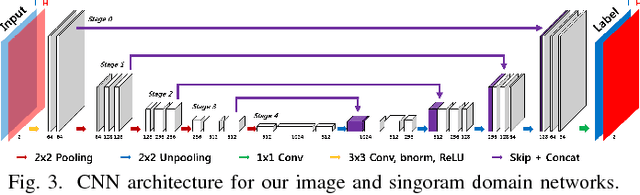
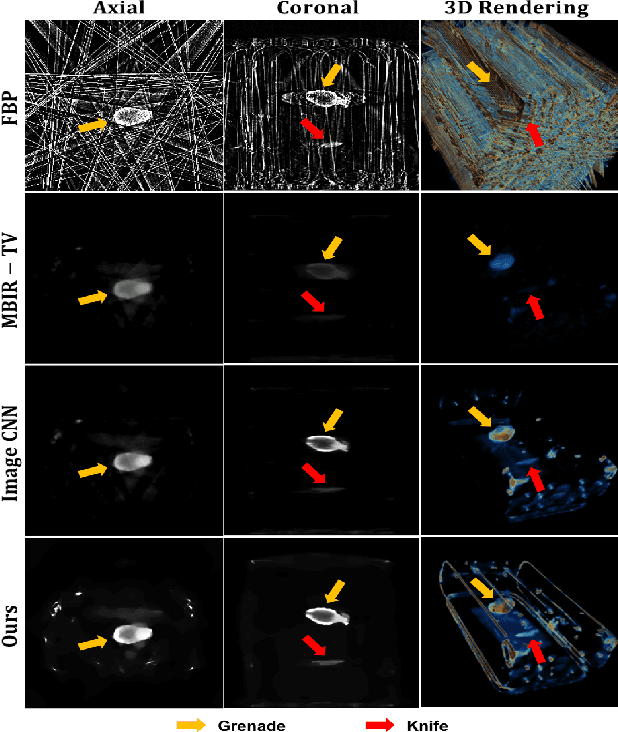
For homeland and transportation security applications, 2D X-ray explosive detection system (EDS) have been widely used, but they have limitations in recognizing 3D shape of the hidden objects. Among various types of 3D computed tomography (CT) systems to address this issue, this paper is interested in a stationary CT using fixed X-ray sources and detectors. However, due to the limited number of projection views, analytic reconstruction algorithms produce severe streaking artifacts. Inspired by recent success of deep learning approach for sparse view CT reconstruction, here we propose a novel image and sinogram domain deep learning architecture for 3D reconstruction from very sparse view measurement. The algorithm has been tested with the real data from a prototype 9-view dual energy stationary CT EDS carry-on baggage scanner developed by GEMSS Medical Systems, Korea, which confirms the superior reconstruction performance over the existing approaches.