 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangled representation learning for multilingual speaker recognition
Nov 01, 2022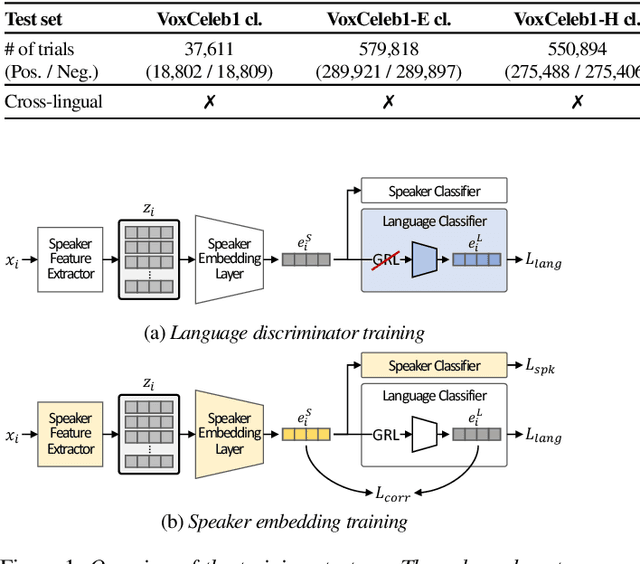

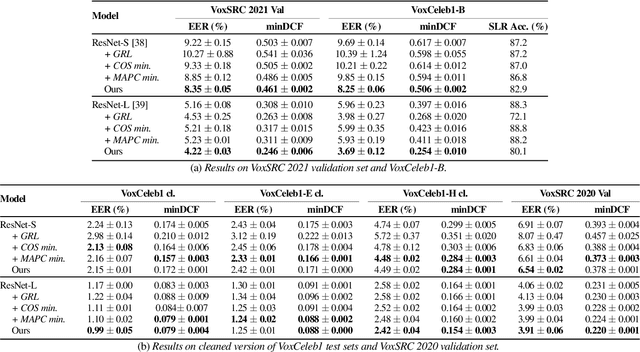
The goal of this paper is to train speaker embeddings that are robust to bilingual speaking scenario. The majority of the world's population speak at least two languages; however, most speaker recognition systems fail to recognise the same speaker when speaking in different languages. Popular speaker recognition evaluation sets do not consider the bilingual scenario, making it difficult to analyse the effect of bilingual speakers on speaker recognition performance. This paper proposes a new large-scale evaluation set derived from VoxCeleb that considers bilingual scenarios. We also introduce a representation learning strategy, which disentangles language information from speaker representation to account for the bilingual scenario. This language-disentangled representation learning strategy can be adapted to existing models with small changes to the training pipeline. Experimental results demonstrate that the baseline models suffer significant performance degradation when evaluated on the proposed bilingual test set. On the contrary, the model trained with the proposed disentanglement strategy shows significant improvement under the bilingual evaluation scenario while simultaneously retaining competitive performance on existing monolingual test sets.
Augmentation adversarial training for unsupervised speaker recognition
Aug 09, 2020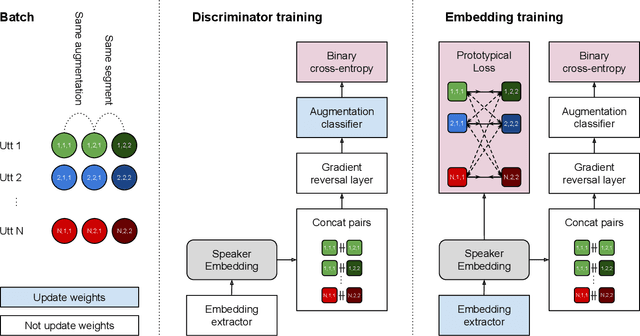

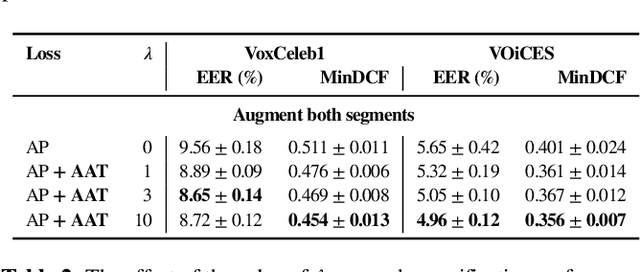
The goal of this work is to train robust speaker recognition models without speaker labels. Recent works on unsupervised speaker representations are based on contrastive learning in which they encourage within-utterance embeddings to be similar and across-utterance embeddings to be dissimilar. However, since the within-utterance segments share the same acoustic characteristics, it is difficult to separate the speaker information from the channel information. To this end, we propose augmentation adversarial training strategy that trains the network to be discriminative for the speaker information, while invariant to the augmentation applied. Since the augmentation simulates the acoustic characteristics, training the network to be invariant to augmentation also encourages the network to be invariant to the channel information in general. Extensive experiments on the VoxCeleb and VOiCES datasets show significant improvements over previous works using self-supervision, and the performance of our self-supervised models far exceed that of humans.
End-to-End Lip Synchronisation
May 18, 2020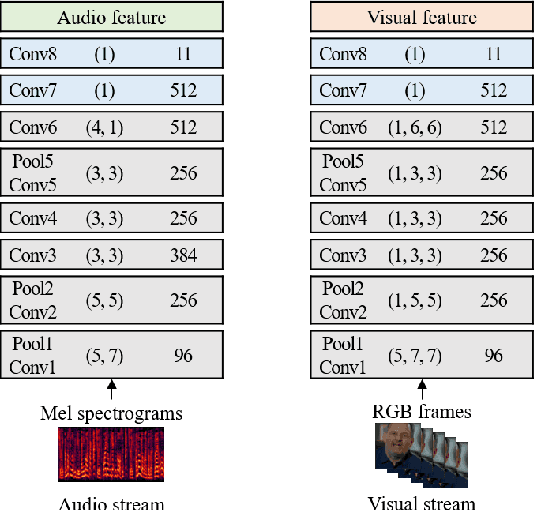



The goal of this work is to synchronise audio and video of a talking face using deep neural network models. Existing works have trained networks on proxy tasks such as cross-modal similarity learning, and then computed similarities between audio and video frames using a sliding window approach. While these methods demonstrate satisfactory performance, the networks are not trained directly on the task. To this end, we propose an end-to-end trained network that can directly predict the offset between an audio stream and the corresponding video stream. The similarity matrix between the two modalities is first computed from the features, then the inference of the offset can be considered to be a pattern recognition problem where the matrix is considered equivalent to an image. The feature extractor and the classifier are trained jointly. We demonstrate that the proposed approach outperforms the previous work by a large margin on LRS2 and LRS3 datasets.