 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the Gap between Audio and Text using Parallel-attention for User-defined Keyword Spotting
Aug 07, 2024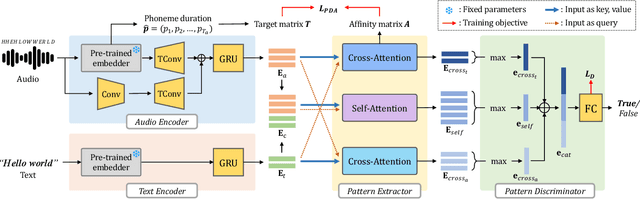
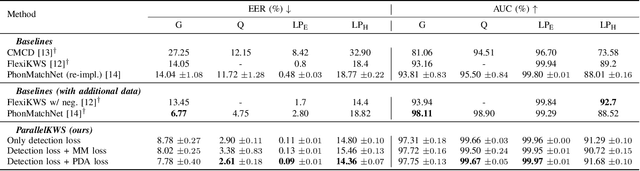

This paper proposes a novel user-defined keyword spotting framework that accurately detects audio keywords based on text enrollment. Since audio data possesses additional acoustic information compared to text, there are discrepancies between these two modalities. To address this challenge, we present ParallelKWS, which utilises self- and cross-attention in a parallel architecture to effectively capture information both within and across the two modalities. We further propose a phoneme duration-based alignment loss that enforces the sequential correspondence between audio and text features. Extensive experimental results demonstrate that our proposed method achieves state-of-the-art performance on several benchmark datasets in both seen and unseen domains, without incorporating extra data beyond the dataset used in previous studies.
VoxSim: A perceptual voice similarity dataset
Jul 26, 2024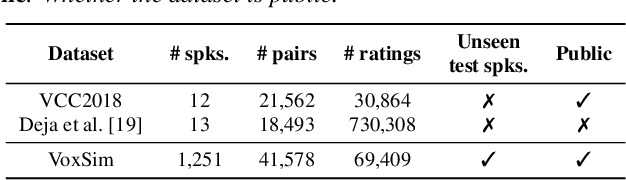
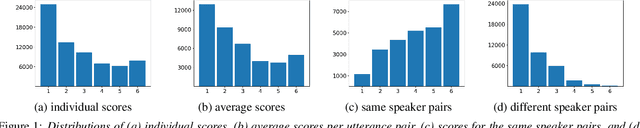


This paper introduces VoxSim, a dataset of perceptual voice similarity ratings. Recent efforts to automate the assessment of speech synthesis technologies have primarily focused on predicting mean opinion score of naturalness, leaving speaker voice similarity relatively unexplored due to a lack of extensive training data. To address this, we generate about 41k utterance pairs from the VoxCeleb dataset, a widely utilised speech dataset for speaker recognition, and collect nearly 70k speaker similarity scores through a listening test. VoxSim offers a valuable resource for the development and benchmarking of speaker similarity prediction models. We provide baseline results of speaker similarity prediction models on the VoxSim test set and further demonstrate that the model trained on our dataset generalises to the out-of-domain VCC2018 dataset.
Metric Learning for User-defined Keyword Spotting
Nov 01, 2022The goal of this work is to detect new spoken terms defined by users. While most previous works address Keyword Spotting (KWS) as a closed-set classification problem, this limits their transferability to unseen terms. The ability to define custom keywords has advantages in terms of user experience. In this paper, we propose a metric learning-based training strategy for user-defined keyword spotting. In particular, we make the following contributions: (1) we construct a large-scale keyword dataset with an existing speech corpus and propose a filtering method to remove data that degrade model training; (2) we propose a metric learning-based two-stage training strategy, and demonstrate that the proposed method improves the performance on the user-defined keyword spotting task by enriching their representations; (3) to facilitate the fair comparison in the user-defined KWS field, we propose unified evaluation protocol and metrics. Our proposed system does not require an incremental training on the user-defined keywords, and outperforms previous works by a significant margin on the Google Speech Commands dataset using the proposed as well as the existing metrics.
Disentangled representation learning for multilingual speaker recognition
Nov 01, 2022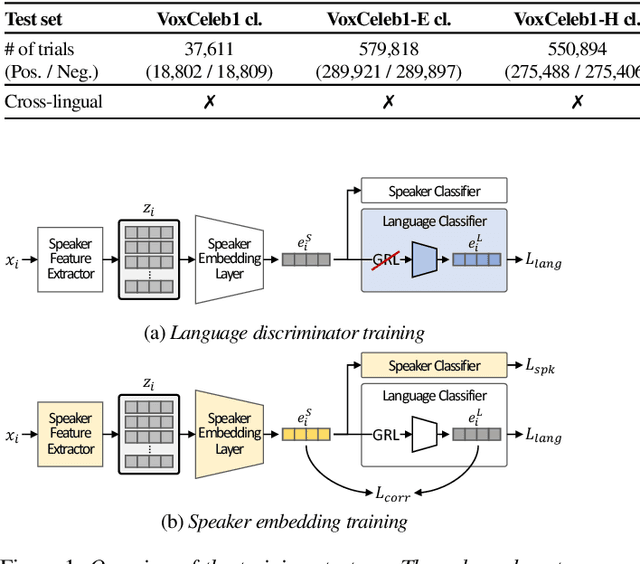

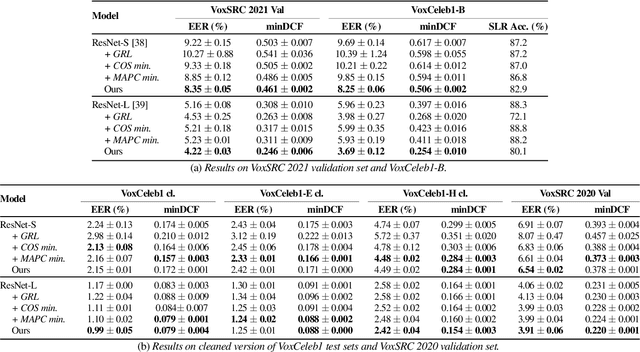
The goal of this paper is to train speaker embeddings that are robust to bilingual speaking scenario. The majority of the world's population speak at least two languages; however, most speaker recognition systems fail to recognise the same speaker when speaking in different languages. Popular speaker recognition evaluation sets do not consider the bilingual scenario, making it difficult to analyse the effect of bilingual speakers on speaker recognition performance. This paper proposes a new large-scale evaluation set derived from VoxCeleb that considers bilingual scenarios. We also introduce a representation learning strategy, which disentangles language information from speaker representation to account for the bilingual scenario. This language-disentangled representation learning strategy can be adapted to existing models with small changes to the training pipeline. Experimental results demonstrate that the baseline models suffer significant performance degradation when evaluated on the proposed bilingual test set. On the contrary, the model trained with the proposed disentanglement strategy shows significant improvement under the bilingual evaluation scenario while simultaneously retaining competitive performance on existing monolingual test sets.