 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptVC: High Quality Voice Conversion with Adaptive Learning
Jan 07, 2025



The goal of voice conversion is to transform the speech of a source speaker to sound like that of a reference speaker while preserving the original content. A key challenge is to extract disentangled linguistic content from the source and voice style from the reference. While existing approaches leverage various methods to isolate the two, a generalization still requires further attention, especially for robustness in zero-shot scenarios. In this paper, we achieve successful disentanglement of content and speaker features by tuning self-supervised speech features with adapters. The adapters are trained to dynamically encode nuanced features from rich self-supervised features, and the decoder fuses them to produce speech that accurately resembles the reference with minimal loss of content. Moreover, we leverage a conditional flow matching decoder with cross-attention speaker conditioning to further boost the synthesis quality and efficiency. Subjective and objective evaluations in a zero-shot scenario demonstrate that the proposed method outperforms existing models in speech quality and similarity to the reference speech.
VoxSim: A perceptual voice similarity dataset
Jul 26, 2024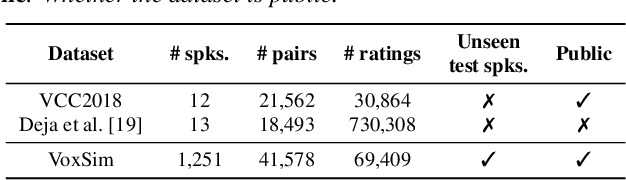
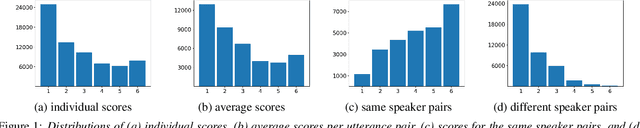


This paper introduces VoxSim, a dataset of perceptual voice similarity ratings. Recent efforts to automate the assessment of speech synthesis technologies have primarily focused on predicting mean opinion score of naturalness, leaving speaker voice similarity relatively unexplored due to a lack of extensive training data. To address this, we generate about 41k utterance pairs from the VoxCeleb dataset, a widely utilised speech dataset for speaker recognition, and collect nearly 70k speaker similarity scores through a listening test. VoxSim offers a valuable resource for the development and benchmarking of speaker similarity prediction models. We provide baseline results of speaker similarity prediction models on the VoxSim test set and further demonstrate that the model trained on our dataset generalises to the out-of-domain VCC2018 dataset.
Perceptually Guided End-to-End Text-to-Speech
Nov 02, 2020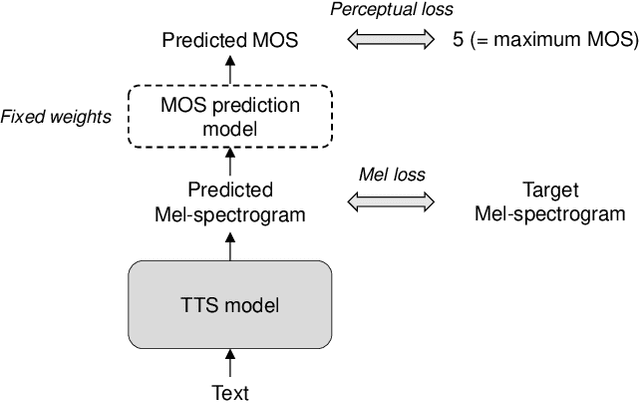
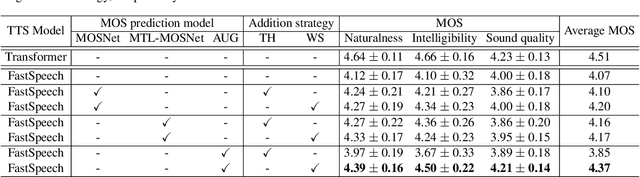
Several fast text-to-speech (TTS) models have been proposed for real-time processing, but there is room for improvement in speech quality. Meanwhile, there is a mismatch between the loss function for training and the mean opinion score (MOS) for evaluation, which may limit the speech quality of TTS models. In this work, we propose a method that can improve the speech quality of a fast TTS model while maintaining the inference speed. To do so, we train a TTS model using a perceptual loss based on the predicted MOS. Under the supervision of a MOS prediction model, a TTS model can learn to increase the perceptual quality of speech directly. In experiments, we train FastSpeech on our internal Korean dataset using the MOS prediction model pre-trained on the Voice Conversion Challenge 2018 evaluation results. The MOS test results show that our proposed approach outperforms FastSpeech in speech quality.
A Unified Deep Learning Framework for Short-Duration Speaker Verification in Adverse Environments
Oct 06, 2020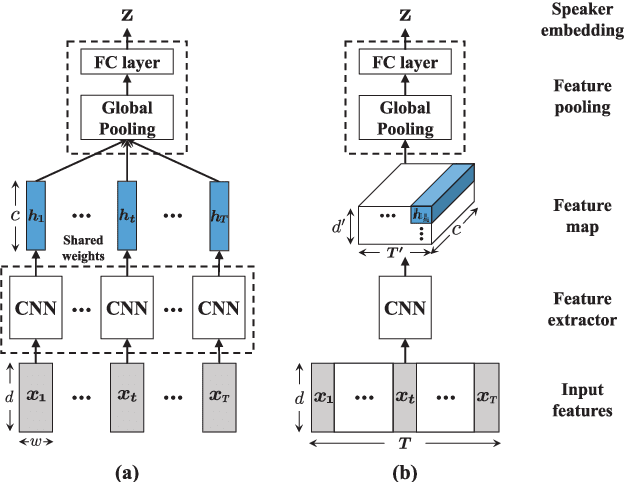
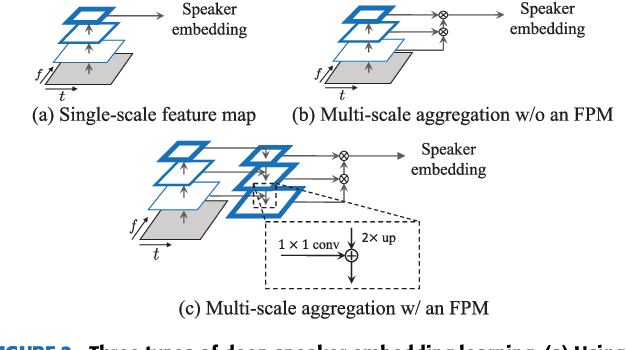
Speaker verification (SV) has recently attracted considerable research interest due to the growing popularity of virtual assistants. At the same time, there is an increasing requirement for an SV system: it should be robust to short speech segments, especially in noisy and reverberant environments. In this paper, we consider one more important requirement for practical applications: the system should be robust to an audio stream containing long non-speech segments, where a voice activity detection (VAD) is not applied. To meet these two requirements, we introduce feature pyramid module (FPM)-based multi-scale aggregation (MSA) and self-adaptive soft VAD (SAS-VAD). We present the FPM-based MSA to deal with short speech segments in noisy and reverberant environments. Also, we use the SAS-VAD to increase the robustness to long non-speech segments. To further improve the robustness to acoustic distortions (i.e., noise and reverberation), we apply a masking-based speech enhancement (SE) method. We combine SV, VAD, and SE models in a unified deep learning framework and jointly train the entire network in an end-to-end manner. To the best of our knowledge, this is the first work combining these three models in a deep learning framework. We conduct experiments on Korean indoor (KID) and VoxCeleb datasets, which are corrupted by noise and reverberation. The results show that the proposed method is effective for SV in the challenging conditions and performs better than the baseline i-vector and deep speaker embedding systems.
* 19 pages, 10 figures, 13 tables
Deep MOS Predictor for Synthetic Speech Using Cluster-Based Modeling
Aug 09, 2020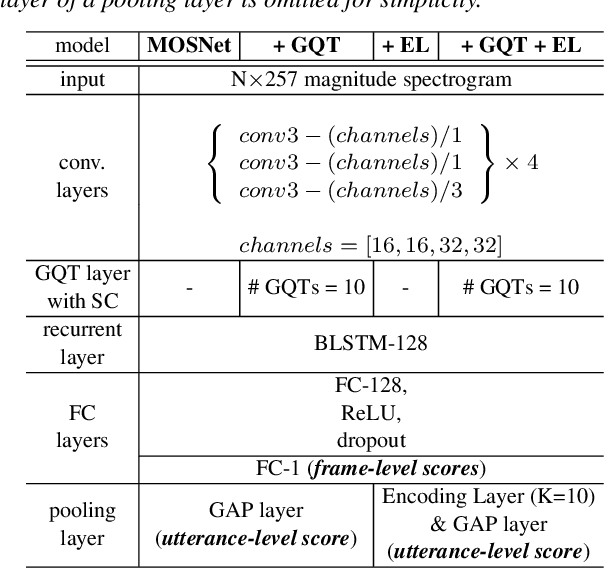

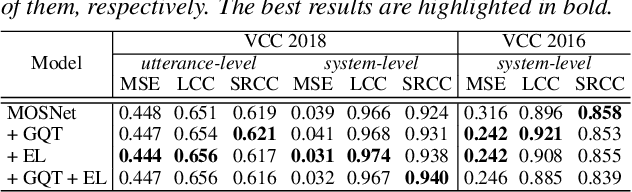
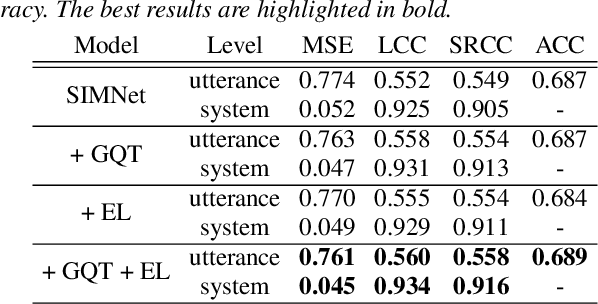
While deep learning has made impressive progress in speech synthesis and voice conversion, the assessment of the synthesized speech is still carried out by human participants. Several recent papers have proposed deep-learning-based assessment models and shown the potential to automate the speech quality assessment. To improve the previously proposed assessment model, MOSNet, we propose three models using cluster-based modeling methods: using a global quality token (GQT) layer, using an Encoding Layer, and using both of them. We perform experiments using the evaluation results of the Voice Conversion Challenge 2018 to predict the mean opinion score of synthesized speech and similarity score between synthesized speech and reference speech. The results show that the GQT layer helps to predict human assessment better by automatically learning the useful quality tokens for the task and that the Encoding Layer helps to utilize frame-level scores more precisely.
Neural MOS Prediction for Synthesized Speech Using Multi-Task Learning With Spoofing Detection and Spoofing Type Classification
Jul 16, 2020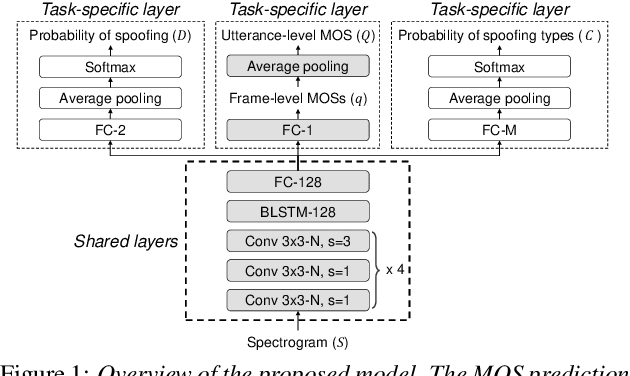
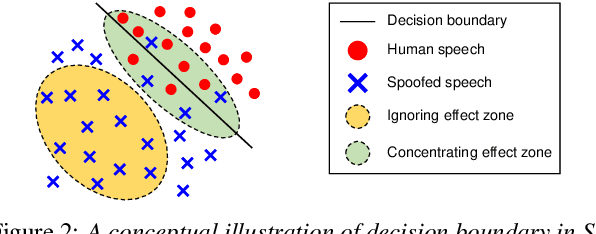
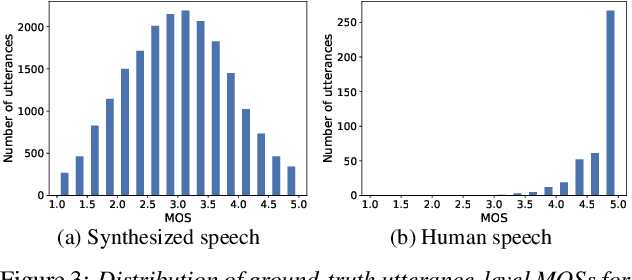
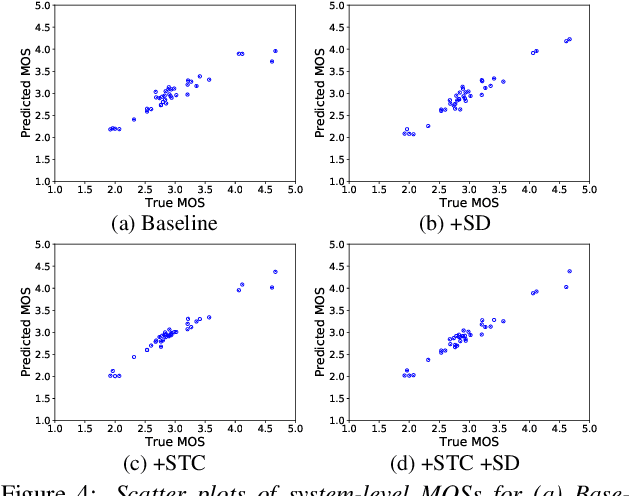
Several papers have proposed deep-learning-based models to predict the mean opinion score (MOS) of synthesized speech, showing the possibility of replacing human raters. However, inter- and intra-rater variability in MOSs makes it hard to ensure the generalization ability of the models. In this paper, we propose a method using multi-task learning (MTL) with spoofing detection (SD) and spoofing type classification (STC) to improve the generalization ability of a MOS prediction model. Besides, we use the focal loss to maximize the synergy between SD and STC for MOS prediction. Experiments using the results of the Voice Conversion Challenge 2018 show that proposed MTL with two auxiliary tasks improves MOS prediction.
Multi-Scale Aggregation Using Feature Pyramid Module for Text-Independent Speaker Verification
Apr 14, 2020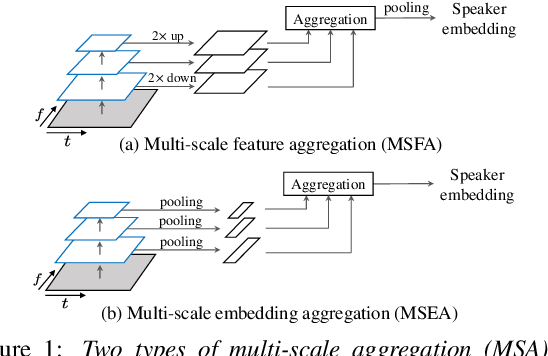
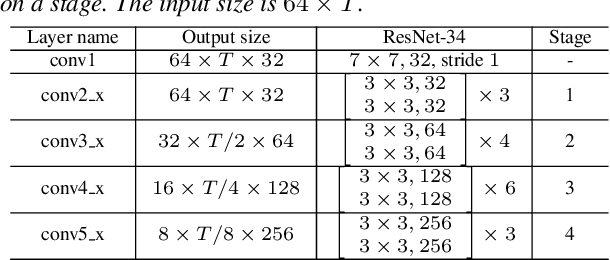
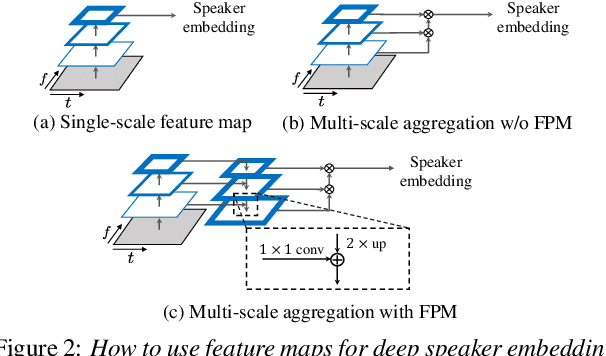
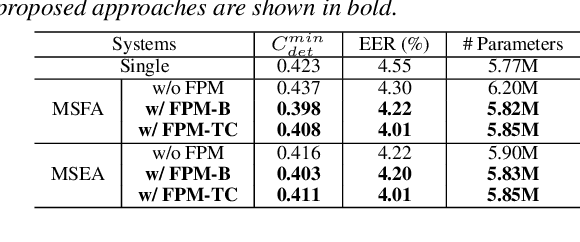
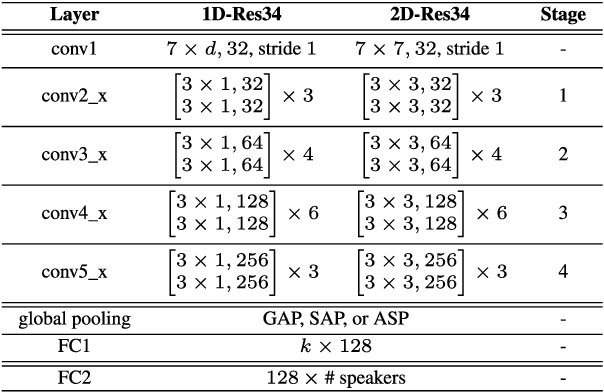
Currently, the most widely used approach for speaker verification is the deep speaker embedding learning. In this approach, convolutional neural networks are mainly used as a frame-level feature extractor, and speaker embeddings are extracted from the last layer of the feature extractor. Multi-scale aggregation (MSA), which utilizes multi-scale features from different layers of the feature extractor, has recently been introduced into the approach and has shown improved performance for both short and long utterances. This paper improves the MSA by using a feature pyramid module, which enhances speaker-discriminative information of features at multiple layers via a top-down pathway and lateral connections. We extract speaker embeddings using the enhanced features that contain rich speaker information at different resolutions. Experiments on the VoxCeleb dataset show that the proposed module improves previous MSA methods with a smaller number of parameters, providing better performance than state-of-the-art approaches.
Self-Adaptive Soft Voice Activity Detection using Deep Neural Networks for Robust Speaker Verification
Sep 26, 2019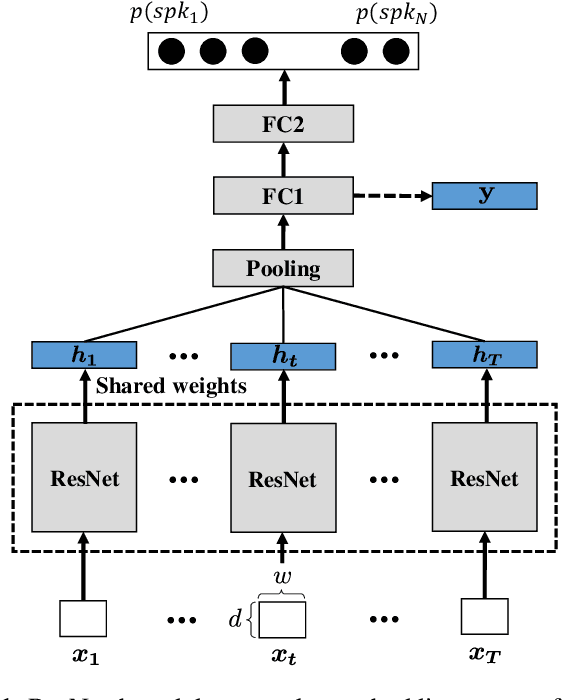


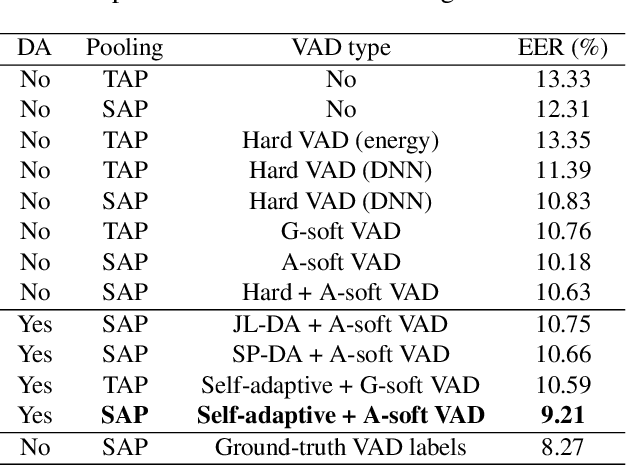
Voice activity detection (VAD), which classifies frames as speech or non-speech, is an important module in many speech applications including speaker verification. In this paper, we propose a novel method, called self-adaptive soft VAD, to incorporate a deep neural network (DNN)-based VAD into a deep speaker embedding system. The proposed method is a combination of the following two approaches. The first approach is soft VAD, which performs a soft selection of frame-level features extracted from a speaker feature extractor. The frame-level features are weighted by their corresponding speech posteriors estimated from the DNN-based VAD, and then aggregated to generate a speaker embedding. The second approach is self-adaptive VAD, which fine-tunes the pre-trained VAD on the speaker verification data to reduce the domain mismatch. Here, we introduce two unsupervised domain adaptation (DA) schemes, namely speech posterior-based DA (SP-DA) and joint learning-based DA (JL-DA). Experiments on a Korean speech database demonstrate that the verification performance is improved significantly in real-world environments by using self-adaptive soft VAD.
Spatial Pyramid Encoding with Convex Length Normalization for Text-Independent Speaker Verification
Jun 19, 2019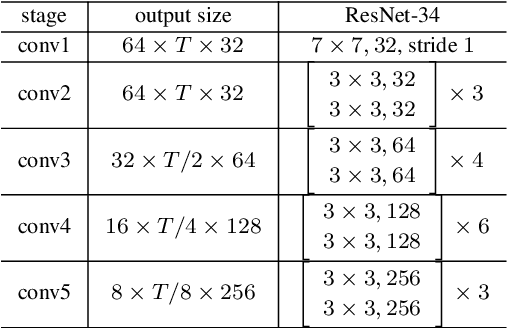
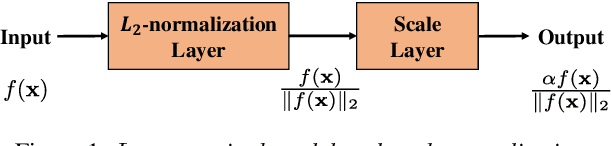
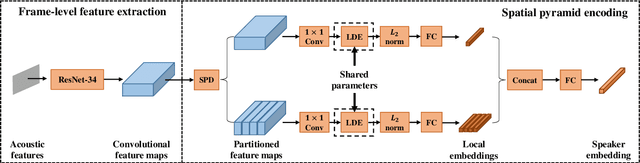
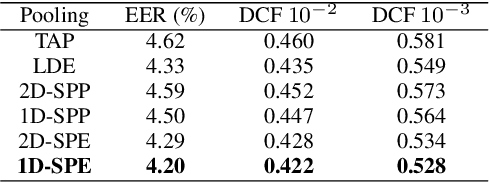
In this paper, we propose a new pooling method called spatial pyramid encoding (SPE) to generate speaker embeddings for text-independent speaker verification. We first partition the output feature maps from a deep residual network (ResNet) into increasingly fine sub-regions and extract speaker embeddings from each sub-region through a learnable dictionary encoding layer. These embeddings are concatenated to obtain the final speaker representation. The SPE layer not only generates a fixed-dimensional speaker embedding for a variable-length speech segment, but also aggregates the information of feature distribution from multi-level temporal bins. Furthermore, we apply deep length normalization by augmenting the loss function with ring loss. By applying ring loss, the network gradually learns to normalize the speaker embeddings using model weights themselves while preserving convexity, leading to more robust speaker embeddings. Experiments on the VoxCeleb1 dataset show that the proposed system using the SPE layer and ring loss-based deep length normalization outperforms both i-vector and d-vector baselines.