 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerceptually Guided End-to-End Text-to-Speech
Paper and Code
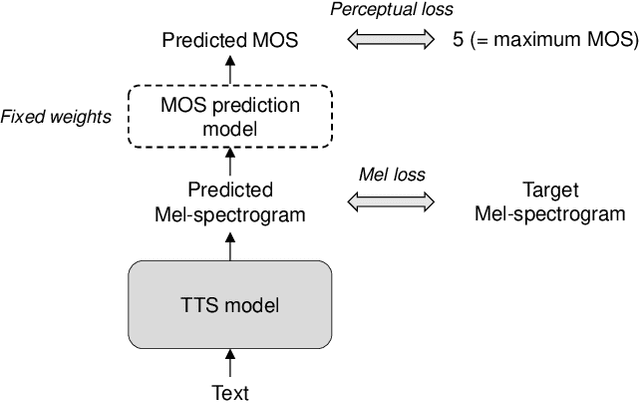
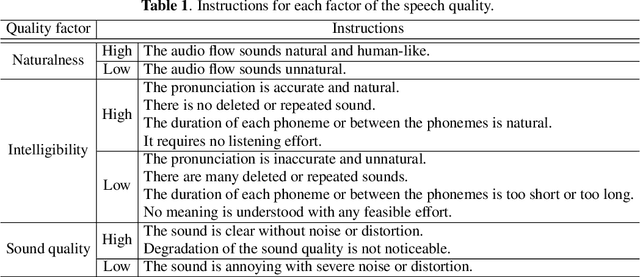
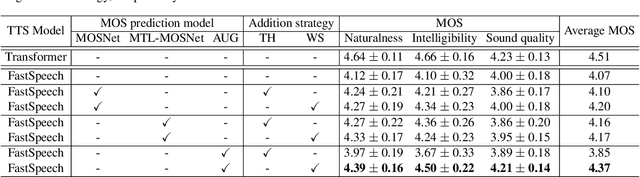
Several fast text-to-speech (TTS) models have been proposed for real-time processing, but there is room for improvement in speech quality. Meanwhile, there is a mismatch between the loss function for training and the mean opinion score (MOS) for evaluation, which may limit the speech quality of TTS models. In this work, we propose a method that can improve the speech quality of a fast TTS model while maintaining the inference speed. To do so, we train a TTS model using a perceptual loss based on the predicted MOS. Under the supervision of a MOS prediction model, a TTS model can learn to increase the perceptual quality of speech directly. In experiments, we train FastSpeech on our internal Korean dataset using the MOS prediction model pre-trained on the Voice Conversion Challenge 2018 evaluation results. The MOS test results show that our proposed approach outperforms FastSpeech in speech quality.