 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Far Do SSL Speech Models Listen for Tone? Temporal Focus of Tone Representation under Low-resource Transfer
Nov 15, 2025



Lexical tone is central to many languages but remains underexplored in self-supervised learning (SSL) speech models, especially beyond Mandarin. We study four languages with complex and diverse tone systems: Burmese, Thai, Lao, and Vietnamese, to examine how far such models listen for tone and how transfer operates in low-resource conditions. As a baseline reference, we estimate the temporal span of tone cues to be about 100 ms in Burmese and Thai, and about 180 ms in Lao and Vietnamese. Probes and gradient analyses on fine-tuned SSL models reveal that tone transfer varies by downstream task: automatic speech recognition fine-tuning aligns spans with language-specific tone cues, while prosody- and voice-related tasks bias the model toward overly long spans. These findings indicate that tone transfer is shaped by downstream task, highlighting task effects on temporal focus in tone modeling.
HuBERT-VIC: Improving Noise-Robust Automatic Speech Recognition of Speech Foundation Model via Variance-Invariance-Covariance Regularization
Aug 17, 2025Noise robustness in speech foundation models (SFMs) has been a critical challenge, as most models are primarily trained on clean data and experience performance degradation when the models are exposed to noisy speech. To address this issue, we propose HuBERT-VIC, a noise-robust SFM with variance, in-variance, and covariance regularization (VICReg) objectives. These objectives adjust the statistics of noisy speech representations, enabling the model to capture diverse acoustic characteristics and improving the generalization ability across different types of noise. When applied to HuBERT, our model shows relative performance improvements of 23.3% on LibriSpeech test-clean and 13.2% on test-other, compared to the baseline model pre-trained on noisy speech.
ParaNoise-SV: Integrated Approach for Noise-Robust Speaker Verification with Parallel Joint Learning of Speech Enhancement and Noise Extraction
Aug 10, 2025


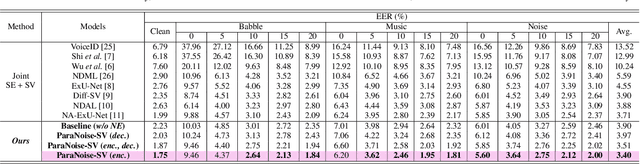
Noise-robust speaker verification leverages joint learning of speech enhancement (SE) and speaker verification (SV) to improve robustness. However, prevailing approaches rely on implicit noise suppression, which struggles to separate noise from speaker characteristics as they do not explicitly distinguish noise from speech during training. Although integrating SE and SV helps, it remains limited in handling noise effectively. Meanwhile, recent SE studies suggest that explicitly modeling noise, rather than merely suppressing it, enhances noise resilience. Reflecting this, we propose ParaNoise-SV, with dual U-Nets combining a noise extraction (NE) network and a speech enhancement (SE) network. The NE U-Net explicitly models noise, while the SE U-Net refines speech with guidance from NE through parallel connections, preserving speaker-relevant features. Experimental results show that ParaNoise-SV achieves a relatively 8.4% lower equal error rate (EER) than previous joint SE-SV models.
Improving Cross-Lingual Phonetic Representation of Low-Resource Languages Through Language Similarity Analysis
Jan 12, 2025



This paper examines how linguistic similarity affects cross-lingual phonetic representation in speech processing for low-resource languages, emphasizing effective source language selection. Previous cross-lingual research has used various source languages to enhance performance for the target low-resource language without thorough consideration of selection. Our study stands out by providing an in-depth analysis of language selection, supported by a practical approach to assess phonetic proximity among multiple language families. We investigate how within-family similarity impacts performance in multilingual training, which aids in understanding language dynamics. We also evaluate the effect of using phonologically similar languages, regardless of family. For the phoneme recognition task, utilizing phonologically similar languages consistently achieves a relative improvement of 55.6% over monolingual training, even surpassing the performance of a large-scale self-supervised learning model. Multilingual training within the same language family demonstrates that higher phonological similarity enhances performance, while lower similarity results in degraded performance compared to monolingual training.
Learning Video Temporal Dynamics with Cross-Modal Attention for Robust Audio-Visual Speech Recognition
Jul 04, 2024



Audio-visual speech recognition (AVSR) aims to transcribe human speech using both audio and video modalities. In practical environments with noise-corrupted audio, the role of video information becomes crucial. However, prior works have primarily focused on enhancing audio features in AVSR, overlooking the importance of video features. In this study, we strengthen the video features by learning three temporal dynamics in video data: context order, playback direction, and the speed of video frames. Cross-modal attention modules are introduced to enrich video features with audio information so that speech variability can be taken into account when training on the video temporal dynamics. Based on our approach, we achieve the state-of-the-art performance on the LRS2 and LRS3 AVSR benchmarks for the noise-dominant settings. Our approach excels in scenarios especially for babble and speech noise, indicating the ability to distinguish the speech signal that should be recognized from lip movements in the video modality. We support the validity of our methodology by offering the ablation experiments for the temporal dynamics losses and the cross-modal attention architecture design.
One-Class Learning with Adaptive Centroid Shift for Audio Deepfake Detection
Jun 24, 2024



As speech synthesis systems continue to make remarkable advances in recent years, the importance of robust deepfake detection systems that perform well in unseen systems has grown. In this paper, we propose a novel adaptive centroid shift (ACS) method that updates the centroid representation by continually shifting as the weighted average of bonafide representations. Our approach uses only bonafide samples to define their centroid, which can yield a specialized centroid for one-class learning. Integrating our ACS with one-class learning gathers bonafide representations into a single cluster, forming well-separated embeddings robust to unseen spoofing attacks. Our proposed method achieves an equal error rate (EER) of 2.19% on the ASVspoof 2021 deepfake dataset, outperforming all existing systems. Furthermore, the t-SNE visualization illustrates that our method effectively maps the bonafide embeddings into a single cluster and successfully disentangles the bonafide and spoof classes.
STaR: Distilling Speech Temporal Relation for Lightweight Speech Self-Supervised Learning Models
Dec 14, 2023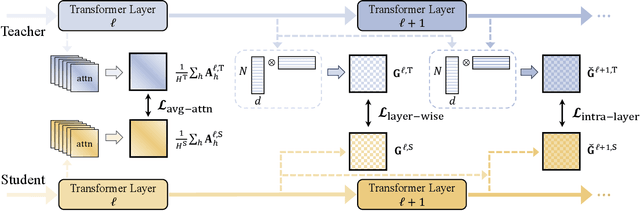



Albeit great performance of Transformer-based speech selfsupervised learning (SSL) models, their large parameter size and computational cost make them unfavorable to utilize. In this study, we propose to compress the speech SSL models by distilling speech temporal relation (STaR). Unlike previous works that directly match the representation for each speech frame, STaR distillation transfers temporal relation between speech frames, which is more suitable for lightweight student with limited capacity. We explore three STaR distillation objectives and select the best combination as the final STaR loss. Our model distilled from HuBERT BASE achieves an overall score of 79.8 on SUPERB benchmark, the best performance among models with up to 27 million parameters. We show that our method is applicable across different speech SSL models and maintains robust performance with further reduced parameters.
Recycle-and-Distill: Universal Compression Strategy for Transformer-based Speech SSL Models with Attention Map Reusing and Masking Distillation
May 19, 2023Transformer-based speech self-supervised learning (SSL) models, such as HuBERT, show surprising performance in various speech processing tasks. However, huge number of parameters in speech SSL models necessitate the compression to a more compact model for wider usage in academia or small companies. In this study, we suggest to reuse attention maps across the Transformer layers, so as to remove key and query parameters while retaining the number of layers. Furthermore, we propose a novel masking distillation strategy to improve the student model's speech representation quality. We extend the distillation loss to utilize both masked and unmasked speech frames to fully leverage the teacher model's high-quality representation. Our universal compression strategy yields the student model that achieves phoneme error rate (PER) of 7.72% and word error rate (WER) of 9.96% on the SUPERB benchmark.
Deep Metric Learning with Adaptive Margin and Adaptive Scale for Acoustic Word Discrimination
Oct 26, 2022Many recent loss functions in deep metric learning are expressed with logarithmic and exponential forms, and they involve margin and scale as essential hyper-parameters. Since each data class has an intrinsic characteristic, several previous works have tried to learn embedding space close to the real distribution by introducing adaptive margins. However, there was no work on adaptive scales at all. We argue that both margin and scale should be adaptively adjustable during the training. In this paper, we propose a method called Adaptive Margin and Scale (AdaMS), where hyper-parameters of margin and scale are replaced with learnable parameters of adaptive margins and adaptive scales for each class. Our method is evaluated on Wall Street Journal dataset, and we achieve outperforming results for word discrimination tasks.
FitHuBERT: Going Thinner and Deeper for Knowledge Distillation of Speech Self-Supervised Learning
Jul 01, 2022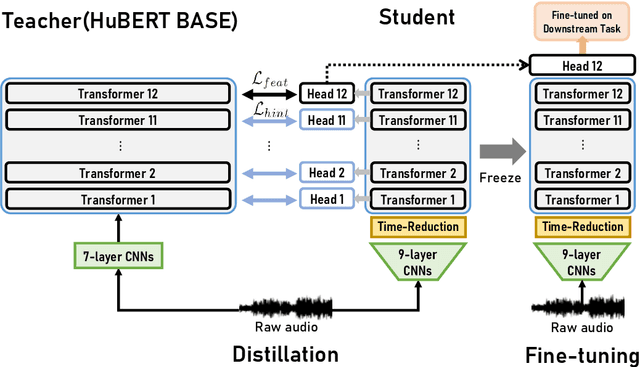
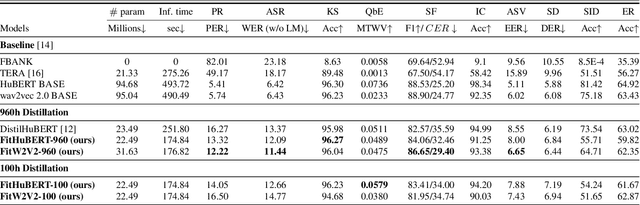
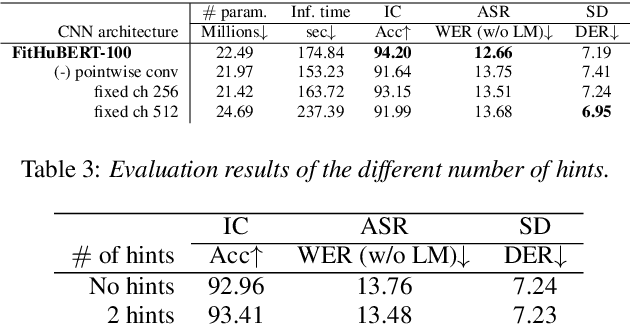

Large-scale speech self-supervised learning (SSL) has emerged to the main field of speech processing, however, the problem of computational cost arising from its vast size makes a high entry barrier to academia. In addition, existing distillation techniques of speech SSL models compress the model by reducing layers, which induces performance degradation in linguistic pattern recognition tasks such as phoneme recognition (PR). In this paper, we propose FitHuBERT, which makes thinner in dimension throughout almost all model components and deeper in layer compared to prior speech SSL distillation works. Moreover, we employ a time-reduction layer to speed up inference time and propose a method of hint-based distillation for less performance degradation. Our method reduces the model to 23.8% in size and 35.9% in inference time compared to HuBERT. Also, we achieve 12.1% word error rate and 13.3% phoneme error rate on the SUPERB benchmark which is superior than prior work.