 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeK-EXAONE Technical Report
Jan 05, 2026This technical report presents K-EXAONE, a large-scale multilingual language model developed by LG AI Research. K-EXAONE is built on a Mixture-of-Experts architecture with 236B total parameters, activating 23B parameters during inference. It supports a 256K-token context window and covers six languages: Korean, English, Spanish, German, Japanese, and Vietnamese. We evaluate K-EXAONE on a comprehensive benchmark suite spanning reasoning, agentic, general, Korean, and multilingual abilities. Across these evaluations, K-EXAONE demonstrates performance comparable to open-weight models of similar size. K-EXAONE, designed to advance AI for a better life, is positioned as a powerful proprietary AI foundation model for a wide range of industrial and research applications.
How Far Do SSL Speech Models Listen for Tone? Temporal Focus of Tone Representation under Low-resource Transfer
Nov 15, 2025



Lexical tone is central to many languages but remains underexplored in self-supervised learning (SSL) speech models, especially beyond Mandarin. We study four languages with complex and diverse tone systems: Burmese, Thai, Lao, and Vietnamese, to examine how far such models listen for tone and how transfer operates in low-resource conditions. As a baseline reference, we estimate the temporal span of tone cues to be about 100 ms in Burmese and Thai, and about 180 ms in Lao and Vietnamese. Probes and gradient analyses on fine-tuned SSL models reveal that tone transfer varies by downstream task: automatic speech recognition fine-tuning aligns spans with language-specific tone cues, while prosody- and voice-related tasks bias the model toward overly long spans. These findings indicate that tone transfer is shaped by downstream task, highlighting task effects on temporal focus in tone modeling.
ParaNoise-SV: Integrated Approach for Noise-Robust Speaker Verification with Parallel Joint Learning of Speech Enhancement and Noise Extraction
Aug 10, 2025


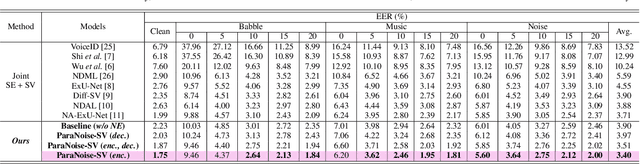
Noise-robust speaker verification leverages joint learning of speech enhancement (SE) and speaker verification (SV) to improve robustness. However, prevailing approaches rely on implicit noise suppression, which struggles to separate noise from speaker characteristics as they do not explicitly distinguish noise from speech during training. Although integrating SE and SV helps, it remains limited in handling noise effectively. Meanwhile, recent SE studies suggest that explicitly modeling noise, rather than merely suppressing it, enhances noise resilience. Reflecting this, we propose ParaNoise-SV, with dual U-Nets combining a noise extraction (NE) network and a speech enhancement (SE) network. The NE U-Net explicitly models noise, while the SE U-Net refines speech with guidance from NE through parallel connections, preserving speaker-relevant features. Experimental results show that ParaNoise-SV achieves a relatively 8.4% lower equal error rate (EER) than previous joint SE-SV models.
Guiding Reasoning in Small Language Models with LLM Assistance
Apr 14, 2025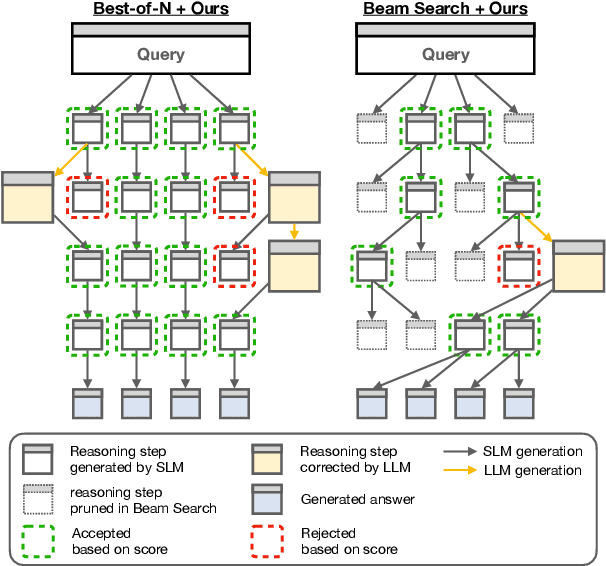
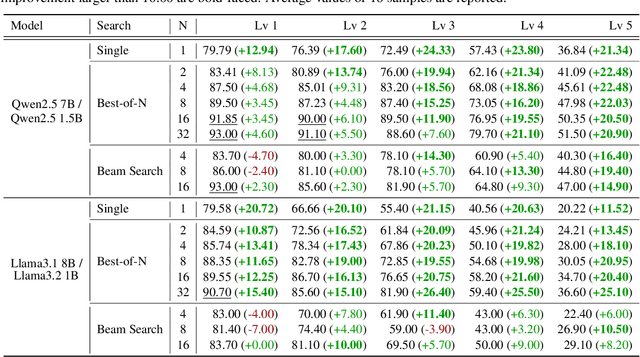
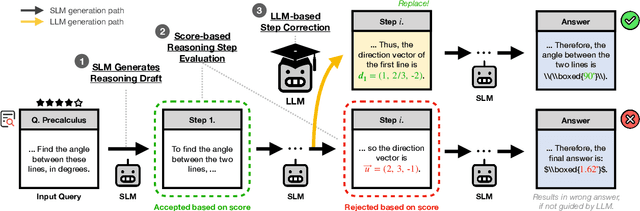

The limited reasoning capabilities of small language models (SLMs) cast doubt on their suitability for tasks demanding deep, multi-step logical deduction. This paper introduces a framework called Small Reasons, Large Hints (SMART), which selectively augments SLM reasoning with targeted guidance from large language models (LLMs). Inspired by the concept of cognitive scaffolding, SMART employs a score-based evaluation to identify uncertain reasoning steps and injects corrective LLM-generated reasoning only when necessary. By framing structured reasoning as an optimal policy search, our approach steers the reasoning trajectory toward correct solutions without exhaustive sampling. Our experiments on mathematical reasoning datasets demonstrate that targeted external scaffolding significantly improves performance, paving the way for collaborative use of both SLM and LLM to tackle complex reasoning tasks that are currently unsolvable by SLMs alone.
Improving Cross-Lingual Phonetic Representation of Low-Resource Languages Through Language Similarity Analysis
Jan 12, 2025



This paper examines how linguistic similarity affects cross-lingual phonetic representation in speech processing for low-resource languages, emphasizing effective source language selection. Previous cross-lingual research has used various source languages to enhance performance for the target low-resource language without thorough consideration of selection. Our study stands out by providing an in-depth analysis of language selection, supported by a practical approach to assess phonetic proximity among multiple language families. We investigate how within-family similarity impacts performance in multilingual training, which aids in understanding language dynamics. We also evaluate the effect of using phonologically similar languages, regardless of family. For the phoneme recognition task, utilizing phonologically similar languages consistently achieves a relative improvement of 55.6% over monolingual training, even surpassing the performance of a large-scale self-supervised learning model. Multilingual training within the same language family demonstrates that higher phonological similarity enhances performance, while lower similarity results in degraded performance compared to monolingual training.
Inter-linguistic Phonetic Composition (IPC): A Theoretical and Computational Approach to Enhance Second Language Pronunciation
Nov 17, 2024



Learners of a second language (L2) often unconsciously substitute unfamiliar L2 phonemes with similar phonemes from their native language (L1), even though native speakers of the L2 perceive these sounds as distinct and non-interchangeable. This phonemic substitution leads to deviations from the standard phonological patterns of the L2, creating challenges for learners in acquiring accurate L2 pronunciation. To address this, we propose Inter-linguistic Phonetic Composition (IPC), a novel computational method designed to minimize incorrect phonological transfer by reconstructing L2 phonemes as composite sounds derived from multiple L1 phonemes. Tests with two automatic speech recognition models demonstrated that when L2 speakers produced IPC-generated composite sounds, the recognition rate of target L2 phonemes improved by 20% compared to when their pronunciation was influenced by original phonological transfer patterns. The improvement was observed within a relatively shorter time frame, demonstrating rapid acquisition of the composite sound.
Preference Alignment with Flow Matching
May 30, 2024



We present Preference Flow Matching (PFM), a new framework for preference-based reinforcement learning (PbRL) that streamlines the integration of preferences into an arbitrary class of pre-trained models. Existing PbRL methods require fine-tuning pre-trained models, which presents challenges such as scalability, inefficiency, and the need for model modifications, especially with black-box APIs like GPT-4. In contrast, PFM utilizes flow matching techniques to directly learn from preference data, thereby reducing the dependency on extensive fine-tuning of pre-trained models. By leveraging flow-based models, PFM transforms less preferred data into preferred outcomes, and effectively aligns model outputs with human preferences without relying on explicit or implicit reward function estimation, thus avoiding common issues like overfitting in reward models. We provide theoretical insights that support our method's alignment with standard PbRL objectives. Experimental results indicate the practical effectiveness of our method, offering a new direction in aligning a pre-trained model to preference.