 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM Agents for Bargaining with Utility-based Feedback
May 29, 2025Bargaining, a critical aspect of real-world interactions, presents challenges for large language models (LLMs) due to limitations in strategic depth and adaptation to complex human factors. Existing benchmarks often fail to capture this real-world complexity. To address this and enhance LLM capabilities in realistic bargaining, we introduce a comprehensive framework centered on utility-based feedback. Our contributions are threefold: (1) BargainArena, a novel benchmark dataset with six intricate scenarios (e.g., deceptive practices, monopolies) to facilitate diverse strategy modeling; (2) human-aligned, economically-grounded evaluation metrics inspired by utility theory, incorporating agent utility and negotiation power, which implicitly reflect and promote opponent-aware reasoning (OAR); and (3) a structured feedback mechanism enabling LLMs to iteratively refine their bargaining strategies. This mechanism can positively collaborate with in-context learning (ICL) prompts, including those explicitly designed to foster OAR. Experimental results show that LLMs often exhibit negotiation strategies misaligned with human preferences, and that our structured feedback mechanism significantly improves their performance, yielding deeper strategic and opponent-aware reasoning.
ReFeed: Multi-dimensional Summarization Refinement with Reflective Reasoning on Feedback
Mar 27, 2025Summarization refinement faces challenges when extending to multi-dimension. In this paper, we introduce ReFeed, a powerful summarization refinement pipeline that enhances multiple dimensions through reflective reasoning on feedback. To achieve this, we release SumFeed-CoT, a large-scale Long-CoT-based dataset optimized for training a lightweight model with reflective reasoning. Our experiments reveal how the number of dimensions, feedback exposure, and reasoning policy influence refinement performance, highlighting reflective reasoning and simultaneously addressing multiple feedback is crucial to mitigate trade-off between dimensions. Furthermore, ReFeed is robust to noisy feedback and feedback order. Lastly, our finding emphasizes that creating data with a proper goal and guideline constitutes a fundamental pillar of effective reasoning. The dataset and model will be released.
When Debate Fails: Bias Reinforcement in Large Language Models
Mar 21, 2025
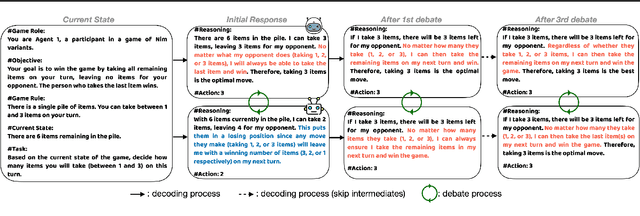
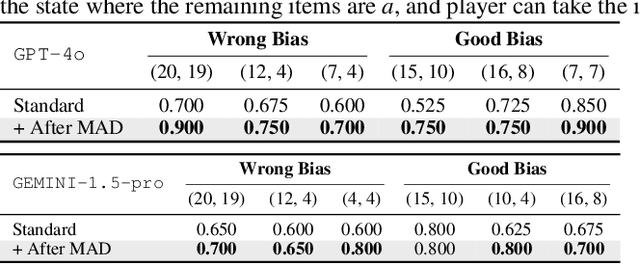
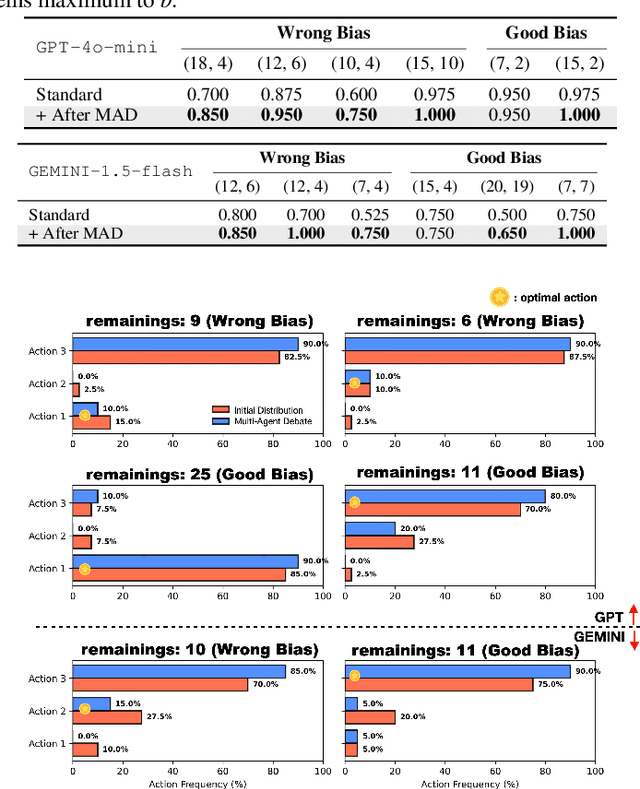
Large Language Models $($LLMs$)$ solve complex problems using training-free methods like prompt engineering and in-context learning, yet ensuring reasoning correctness remains challenging. While self-correction methods such as self-consistency and self-refinement aim to improve reliability, they often reinforce biases due to the lack of effective feedback mechanisms. Multi-Agent Debate $($MAD$)$ has emerged as an alternative, but we identify two key limitations: bias reinforcement, where debate amplifies model biases instead of correcting them, and lack of perspective diversity, as all agents share the same model and reasoning patterns, limiting true debate effectiveness. To systematically evaluate these issues, we introduce $\textit{MetaNIM Arena}$, a benchmark designed to assess LLMs in adversarial strategic decision-making, where dynamic interactions influence optimal decisions. To overcome MAD's limitations, we propose $\textbf{DReaMAD}$ $($$\textbf{D}$iverse $\textbf{Rea}$soning via $\textbf{M}$ulti-$\textbf{A}$gent $\textbf{D}$ebate with Refined Prompt$)$, a novel framework that $(1)$ refines LLM's strategic prior knowledge to improve reasoning quality and $(2)$ promotes diverse viewpoints within a single model by systematically modifying prompts, reducing bias. Empirical results show that $\textbf{DReaMAD}$ significantly improves decision accuracy, reasoning diversity, and bias mitigation across multiple strategic tasks, establishing it as a more effective approach for LLM-based decision-making.
Learning to Verify Summary Facts with Fine-Grained LLM Feedback
Dec 14, 2024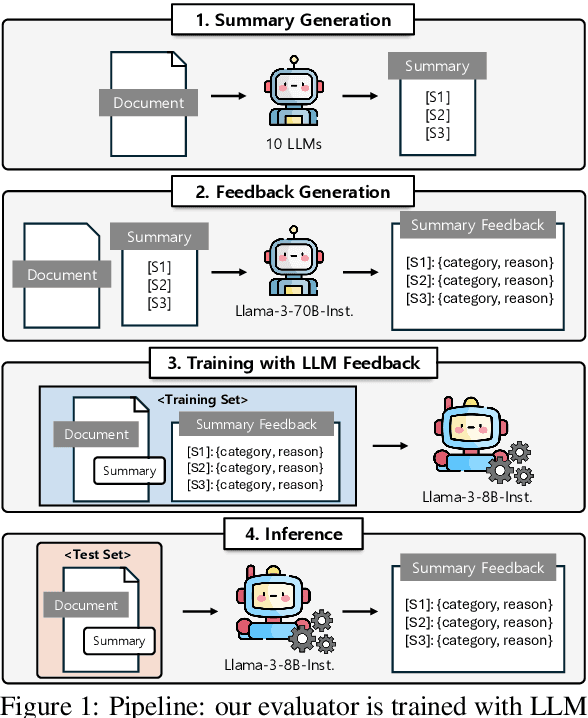
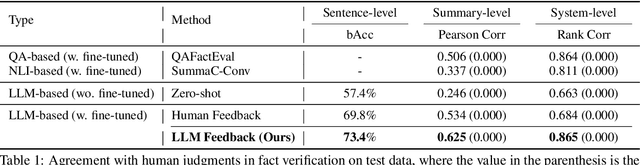


Training automatic summary fact verifiers often faces the challenge of a lack of human-labeled data. In this paper, we explore alternative way of leveraging Large Language Model (LLM) generated feedback to address the inherent limitation of using human-labeled data. We introduce FineSumFact, a large-scale dataset containing fine-grained factual feedback on summaries. We employ 10 distinct LLMs for diverse summary generation and Llama-3-70B-Instruct for feedback. We utilize this dataset to fine-tune the lightweight open-source model Llama-3-8B-Instruct, optimizing resource efficiency while maintaining high performance. Our experimental results reveal that the model trained on extensive LLM-generated datasets surpasses that trained on smaller human-annotated datasets when evaluated using human-generated test sets. Fine-tuning fact verification models with LLM feedback can be more effective and cost-efficient than using human feedback. The dataset is available at https://github.com/DISL-Lab/FineSumFact.
Diffusion-based Episodes Augmentation for Offline Multi-Agent Reinforcement Learning
Aug 23, 2024Offline multi-agent reinforcement learning (MARL) is increasingly recognized as crucial for effectively deploying RL algorithms in environments where real-time interaction is impractical, risky, or costly. In the offline setting, learning from a static dataset of past interactions allows for the development of robust and safe policies without the need for live data collection, which can be fraught with challenges. Building on this foundational importance, we present EAQ, Episodes Augmentation guided by Q-total loss, a novel approach for offline MARL framework utilizing diffusion models. EAQ integrates the Q-total function directly into the diffusion model as a guidance to maximize the global returns in an episode, eliminating the need for separate training. Our focus primarily lies on cooperative scenarios, where agents are required to act collectively towards achieving a shared goal-essentially, maximizing global returns. Consequently, we demonstrate that our episodes augmentation in a collaborative manner significantly boosts offline MARL algorithm compared to the original dataset, improving the normalized return by +17.3% and +12.9% for medium and poor behavioral policies in SMAC simulator, respectively.
Preference Alignment with Flow Matching
May 30, 2024



We present Preference Flow Matching (PFM), a new framework for preference-based reinforcement learning (PbRL) that streamlines the integration of preferences into an arbitrary class of pre-trained models. Existing PbRL methods require fine-tuning pre-trained models, which presents challenges such as scalability, inefficiency, and the need for model modifications, especially with black-box APIs like GPT-4. In contrast, PFM utilizes flow matching techniques to directly learn from preference data, thereby reducing the dependency on extensive fine-tuning of pre-trained models. By leveraging flow-based models, PFM transforms less preferred data into preferred outcomes, and effectively aligns model outputs with human preferences without relying on explicit or implicit reward function estimation, thus avoiding common issues like overfitting in reward models. We provide theoretical insights that support our method's alignment with standard PbRL objectives. Experimental results indicate the practical effectiveness of our method, offering a new direction in aligning a pre-trained model to preference.
Toward Risk-based Optimistic Exploration for Cooperative Multi-Agent Reinforcement Learning
Mar 03, 2023The multi-agent setting is intricate and unpredictable since the behaviors of multiple agents influence one another. To address this environmental uncertainty, distributional reinforcement learning algorithms that incorporate uncertainty via distributional output have been integrated with multi-agent reinforcement learning (MARL) methods, achieving state-of-the-art performance. However, distributional MARL algorithms still rely on the traditional $\epsilon$-greedy, which does not take cooperative strategy into account. In this paper, we present a risk-based exploration that leads to collaboratively optimistic behavior by shifting the sampling region of distribution. Initially, we take expectations from the upper quantiles of state-action values for exploration, which are optimistic actions, and gradually shift the sampling region of quantiles to the full distribution for exploitation. By ensuring that each agent is exposed to the same level of risk, we can force them to take cooperatively optimistic actions. Our method shows remarkable performance in multi-agent settings requiring cooperative exploration based on quantile regression appropriately controlling the level of risk.
The StarCraft Multi-Agent Challenges+ : Learning of Multi-Stage Tasks and Environmental Factors without Precise Reward Functions
Jul 07, 2022


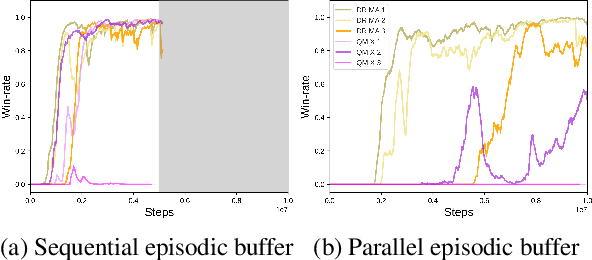
In this paper, we propose a novel benchmark called the StarCraft Multi-Agent Challenges+, where agents learn to perform multi-stage tasks and to use environmental factors without precise reward functions. The previous challenges (SMAC) recognized as a standard benchmark of Multi-Agent Reinforcement Learning are mainly concerned with ensuring that all agents cooperatively eliminate approaching adversaries only through fine manipulation with obvious reward functions. This challenge, on the other hand, is interested in the exploration capability of MARL algorithms to efficiently learn implicit multi-stage tasks and environmental factors as well as micro-control. This study covers both offensive and defensive scenarios. In the offensive scenarios, agents must learn to first find opponents and then eliminate them. The defensive scenarios require agents to use topographic features. For example, agents need to position themselves behind protective structures to make it harder for enemies to attack. We investigate MARL algorithms under SMAC+ and observe that recent approaches work well in similar settings to the previous challenges, but misbehave in offensive scenarios. Additionally, we observe that an enhanced exploration approach has a positive effect on performance but is not able to completely solve all scenarios. This study proposes new directions for future research.
Risk Perspective Exploration in Distributional Reinforcement Learning
Jul 01, 2022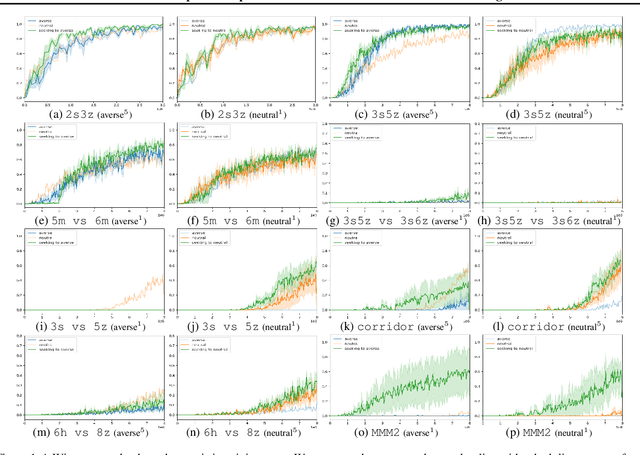
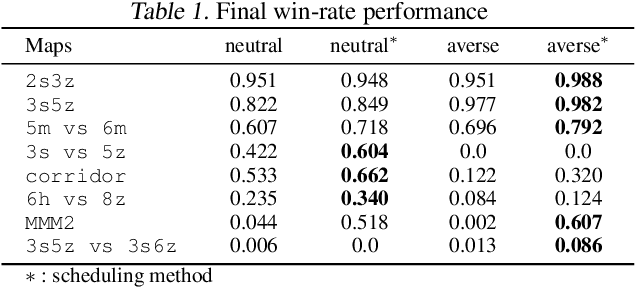


Distributional reinforcement learning demonstrates state-of-the-art performance in continuous and discrete control settings with the features of variance and risk, which can be used to explore. However, the exploration method employing the risk property is hard to find, although numerous exploration methods in Distributional RL employ the variance of return distribution per action. In this paper, we present risk scheduling approaches that explore risk levels and optimistic behaviors from a risk perspective. We demonstrate the performance enhancement of the DMIX algorithm using risk scheduling in a multi-agent setting with comprehensive experiments.