 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Debate Fails: Bias Reinforcement in Large Language Models
Paper and Code
Mar 21, 2025
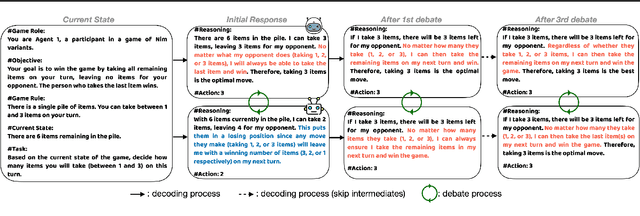
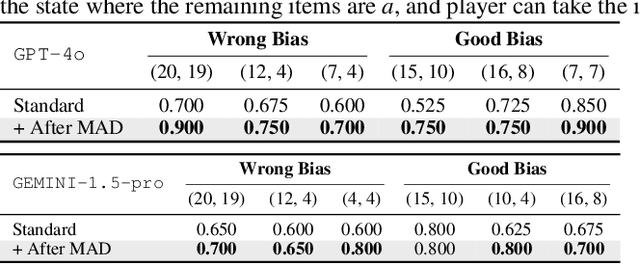
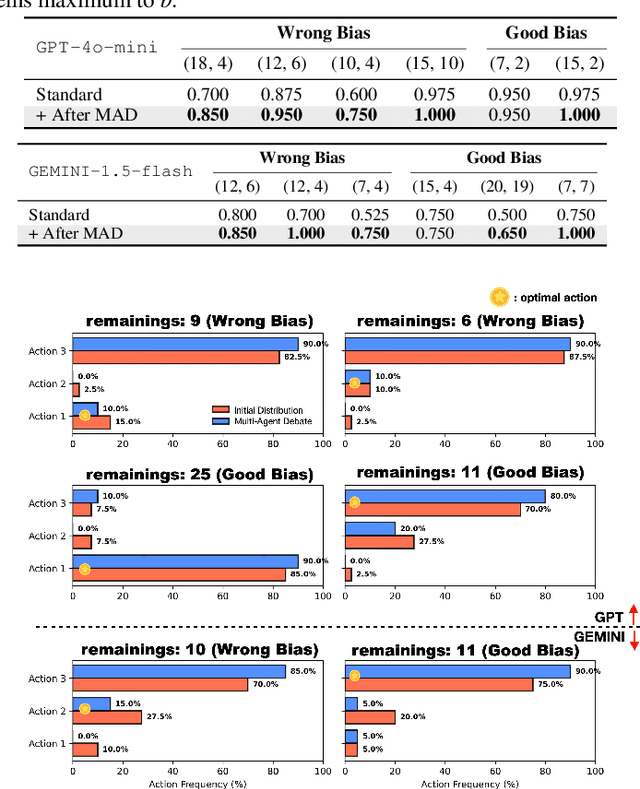
Large Language Models $($LLMs$)$ solve complex problems using training-free methods like prompt engineering and in-context learning, yet ensuring reasoning correctness remains challenging. While self-correction methods such as self-consistency and self-refinement aim to improve reliability, they often reinforce biases due to the lack of effective feedback mechanisms. Multi-Agent Debate $($MAD$)$ has emerged as an alternative, but we identify two key limitations: bias reinforcement, where debate amplifies model biases instead of correcting them, and lack of perspective diversity, as all agents share the same model and reasoning patterns, limiting true debate effectiveness. To systematically evaluate these issues, we introduce $\textit{MetaNIM Arena}$, a benchmark designed to assess LLMs in adversarial strategic decision-making, where dynamic interactions influence optimal decisions. To overcome MAD's limitations, we propose $\textbf{DReaMAD}$ $($$\textbf{D}$iverse $\textbf{Rea}$soning via $\textbf{M}$ulti-$\textbf{A}$gent $\textbf{D}$ebate with Refined Prompt$)$, a novel framework that $(1)$ refines LLM's strategic prior knowledge to improve reasoning quality and $(2)$ promotes diverse viewpoints within a single model by systematically modifying prompts, reducing bias. Empirical results show that $\textbf{DReaMAD}$ significantly improves decision accuracy, reasoning diversity, and bias mitigation across multiple strategic tasks, establishing it as a more effective approach for LLM-based decision-making.