 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Parametric SVD of Koopman Operator for Stochastic Dynamical Systems
Jul 09, 2025
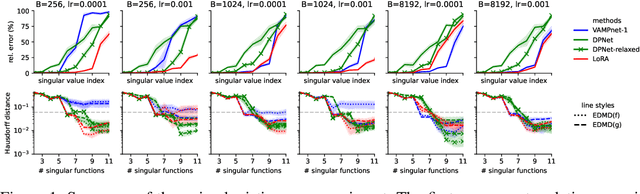
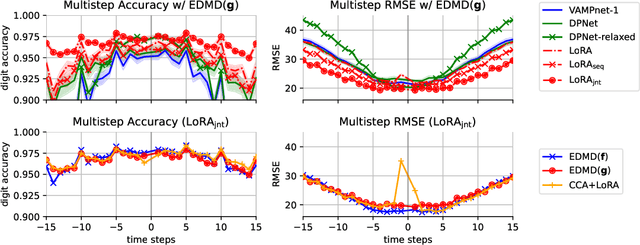
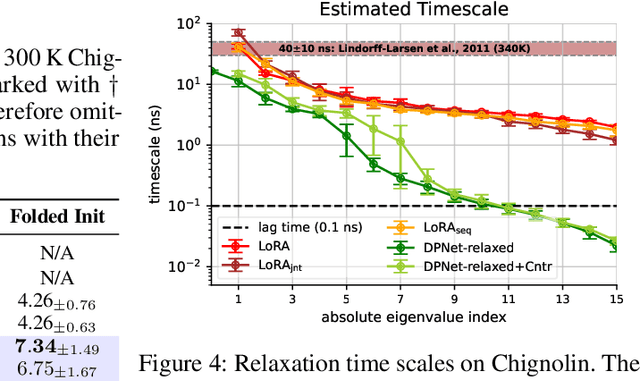
The Koopman operator provides a principled framework for analyzing nonlinear dynamical systems through linear operator theory. Recent advances in dynamic mode decomposition (DMD) have shown that trajectory data can be used to identify dominant modes of a system in a data-driven manner. Building on this idea, deep learning methods such as VAMPnet and DPNet have been proposed to learn the leading singular subspaces of the Koopman operator. However, these methods require backpropagation through potentially numerically unstable operations on empirical second moment matrices, such as singular value decomposition and matrix inversion, during objective computation, which can introduce biased gradient estimates and hinder scalability to large systems. In this work, we propose a scalable and conceptually simple method for learning the top-k singular functions of the Koopman operator for stochastic dynamical systems based on the idea of low-rank approximation. Our approach eliminates the need for unstable linear algebraic operations and integrates easily into modern deep learning pipelines. Empirical results demonstrate that the learned singular subspaces are both reliable and effective for downstream tasks such as eigen-analysis and multi-step prediction.
When Debate Fails: Bias Reinforcement in Large Language Models
Mar 21, 2025
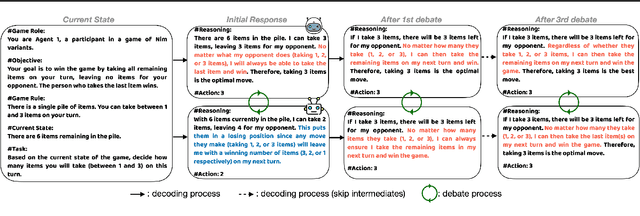
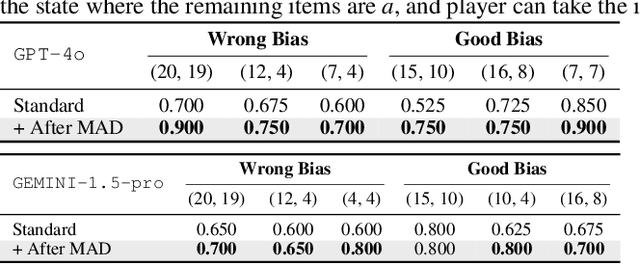
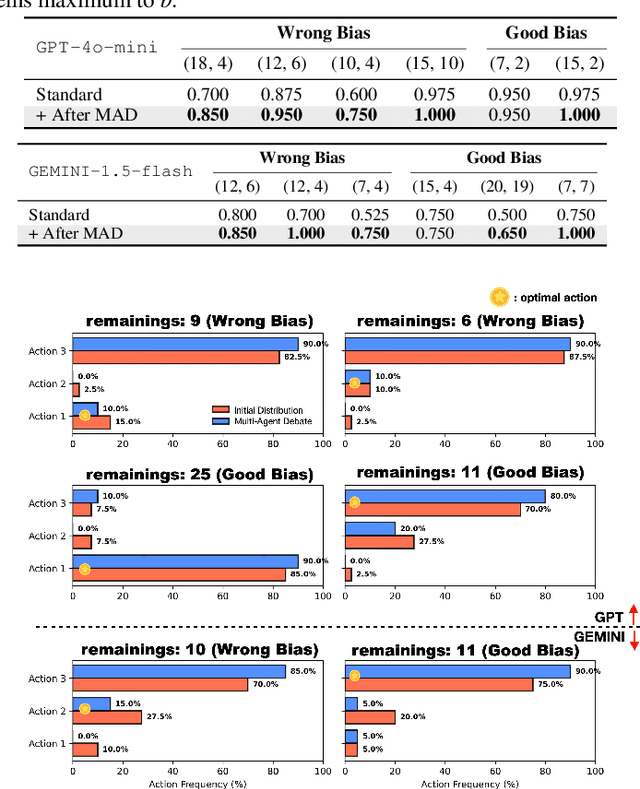
Large Language Models $($LLMs$)$ solve complex problems using training-free methods like prompt engineering and in-context learning, yet ensuring reasoning correctness remains challenging. While self-correction methods such as self-consistency and self-refinement aim to improve reliability, they often reinforce biases due to the lack of effective feedback mechanisms. Multi-Agent Debate $($MAD$)$ has emerged as an alternative, but we identify two key limitations: bias reinforcement, where debate amplifies model biases instead of correcting them, and lack of perspective diversity, as all agents share the same model and reasoning patterns, limiting true debate effectiveness. To systematically evaluate these issues, we introduce $\textit{MetaNIM Arena}$, a benchmark designed to assess LLMs in adversarial strategic decision-making, where dynamic interactions influence optimal decisions. To overcome MAD's limitations, we propose $\textbf{DReaMAD}$ $($$\textbf{D}$iverse $\textbf{Rea}$soning via $\textbf{M}$ulti-$\textbf{A}$gent $\textbf{D}$ebate with Refined Prompt$)$, a novel framework that $(1)$ refines LLM's strategic prior knowledge to improve reasoning quality and $(2)$ promotes diverse viewpoints within a single model by systematically modifying prompts, reducing bias. Empirical results show that $\textbf{DReaMAD}$ significantly improves decision accuracy, reasoning diversity, and bias mitigation across multiple strategic tasks, establishing it as a more effective approach for LLM-based decision-making.
Hard Prompts Made Interpretable: Sparse Entropy Regularization for Prompt Tuning with RL
Jul 20, 2024With the advent of foundation models, prompt tuning has positioned itself as an important technique for directing model behaviors and eliciting desired responses. Prompt tuning regards selecting appropriate keywords included into the input, thereby adapting to the downstream task without adjusting or fine-tuning the model parameters. There is a wide range of work in prompt tuning, from approaches that directly harness the backpropagated gradient signals from the model, to those employing black-box optimization such as reinforcement learning (RL) methods. Our primary focus is on RLPrompt, which aims to find optimal prompt tokens leveraging soft Q-learning. While the results show promise, we have observed that the prompts frequently appear unnatural, which impedes their interpretability. We address this limitation by using sparse Tsallis entropy regularization, a principled approach to filtering out unlikely tokens from consideration. We extensively evaluate our approach across various tasks, including few-shot text classification, unsupervised text style transfer, and textual inversion from images. The results indicate a notable improvement over baselines, highlighting the efficacy of our approach in addressing the challenges of prompt tuning. Moreover, we show that the prompts discovered using our method are more natural and interpretable compared to those from other baselines.
BAPO: Base-Anchored Preference Optimization for Personalized Alignment in Large Language Models
Jun 30, 2024While learning to align Large Language Models (LLMs) with human preferences has shown remarkable success, aligning these models to meet the diverse user preferences presents further challenges in preserving previous knowledge. This paper examines the impact of personalized preference optimization on LLMs, revealing that the extent of knowledge loss varies significantly with preference heterogeneity. Although previous approaches have utilized the KL constraint between the reference model and the policy model, we observe that they fail to maintain general knowledge and alignment when facing personalized preferences. To this end, we introduce Base-Anchored Preference Optimization (BAPO), a simple yet effective approach that utilizes the initial responses of reference model to mitigate forgetting while accommodating personalized alignment. BAPO effectively adapts to diverse user preferences while minimally affecting global knowledge or general alignment. Our experiments demonstrate the efficacy of BAPO in various setups.
FedDr+: Stabilizing Dot-regression with Global Feature Distillation for Federated Learning
Jun 04, 2024Federated Learning (FL) has emerged as a pivotal framework for the development of effective global models (global FL) or personalized models (personalized FL) across clients with heterogeneous, non-iid data distribution. A key challenge in FL is client drift, where data heterogeneity impedes the aggregation of scattered knowledge. Recent studies have tackled the client drift issue by identifying significant divergence in the last classifier layer. To mitigate this divergence, strategies such as freezing the classifier weights and aligning the feature extractor accordingly have proven effective. Although the local alignment between classifier and feature extractor has been studied as a crucial factor in FL, we observe that it may lead the model to overemphasize the observed classes within each client. Thus, our objectives are twofold: (1) enhancing local alignment while (2) preserving the representation of unseen class samples. This approach aims to effectively integrate knowledge from individual clients, thereby improving performance for both global and personalized FL. To achieve this, we introduce a novel algorithm named FedDr+, which empowers local model alignment using dot-regression loss. FedDr+ freezes the classifier as a simplex ETF to align the features and improves aggregated global models by employing a feature distillation mechanism to retain information about unseen/missing classes. Consequently, we provide empirical evidence demonstrating that our algorithm surpasses existing methods that use a frozen classifier to boost alignment across the diverse distribution.
Bayesian Multi-Task Transfer Learning for Soft Prompt Tuning
Feb 13, 2024



Prompt tuning, in which prompts are optimized to adapt large-scale pre-trained language models to downstream tasks instead of fine-tuning the full model parameters, has been shown to be particularly effective when the prompts are trained in a multi-task transfer learning setting. These methods generally involve individually training prompts for each source task and then aggregating them to provide the initialization of the prompt for the target task. However, this approach critically ignores the fact that some of the source tasks could be negatively or positively interfering with each other. We argue that when we extract knowledge from source tasks via training source prompts, we need to consider this correlation among source tasks for better transfer to target tasks. To this end, we propose a Bayesian approach where we work with the posterior distribution of prompts across source tasks. We obtain representative source prompts corresponding to the samples from the posterior utilizing Stein Variational Gradient Descent, which are then aggregated to constitute the initial target prompt. We show extensive experimental results on the standard benchmark NLP tasks, where our Bayesian multi-task transfer learning approach outperforms the state-of-the-art methods in many settings. Furthermore, our approach requires no auxiliary models other than the prompt itself, achieving a high degree of parameter efficiency.
FedSoL: Bridging Global Alignment and Local Generality in Federated Learning
Aug 24, 2023



Federated Learning (FL) aggregates locally trained models from individual clients to construct a global model. While FL enables learning a model with data privacy, it often suffers from significant performance degradation when client data distributions are heterogeneous. Many previous FL algorithms have addressed this issue by introducing various proximal restrictions. These restrictions aim to encourage global alignment by constraining the deviation of local learning from the global objective. However, they inherently limit local learning by interfering with the original local objectives. Recently, an alternative approach has emerged to improve local learning generality. By obtaining local models within a smooth loss landscape, this approach mitigates conflicts among different local objectives of the clients. Yet, it does not ensure stable global alignment, as local learning does not take the global objective into account. In this study, we propose Federated Stability on Learning (FedSoL), which combines both the concepts of global alignment and local generality. In FedSoL, the local learning seeks a parameter region robust against proximal perturbations. This strategy introduces an implicit proximal restriction effect in local learning while maintaining the original local objective for parameter update. Our experiments show that FedSoL consistently achieves state-of-the-art performance on various setups.
Toward Risk-based Optimistic Exploration for Cooperative Multi-Agent Reinforcement Learning
Mar 03, 2023The multi-agent setting is intricate and unpredictable since the behaviors of multiple agents influence one another. To address this environmental uncertainty, distributional reinforcement learning algorithms that incorporate uncertainty via distributional output have been integrated with multi-agent reinforcement learning (MARL) methods, achieving state-of-the-art performance. However, distributional MARL algorithms still rely on the traditional $\epsilon$-greedy, which does not take cooperative strategy into account. In this paper, we present a risk-based exploration that leads to collaboratively optimistic behavior by shifting the sampling region of distribution. Initially, we take expectations from the upper quantiles of state-action values for exploration, which are optimistic actions, and gradually shift the sampling region of quantiles to the full distribution for exploitation. By ensuring that each agent is exposed to the same level of risk, we can force them to take cooperatively optimistic actions. Our method shows remarkable performance in multi-agent settings requiring cooperative exploration based on quantile regression appropriately controlling the level of risk.
Revisiting Intermediate Layer Distillation for Compressing Language Models: An Overfitting Perspective
Feb 03, 2023



Knowledge distillation (KD) is a highly promising method for mitigating the computational problems of pre-trained language models (PLMs). Among various KD approaches, Intermediate Layer Distillation (ILD) has been a de facto standard KD method with its performance efficacy in the NLP field. In this paper, we find that existing ILD methods are prone to overfitting to training datasets, although these methods transfer more information than the original KD. Next, we present the simple observations to mitigate the overfitting of ILD: distilling only the last Transformer layer and conducting ILD on supplementary tasks. Based on our two findings, we propose a simple yet effective consistency-regularized ILD (CR-ILD), which prevents the student model from overfitting the training dataset. Substantial experiments on distilling BERT on the GLUE benchmark and several synthetic datasets demonstrate that our proposed ILD method outperforms other KD techniques. Our code is available at https://github.com/jongwooko/CR-ILD.
Preservation of the Global Knowledge by Not-True Self Knowledge Distillation in Federated Learning
Jun 06, 2021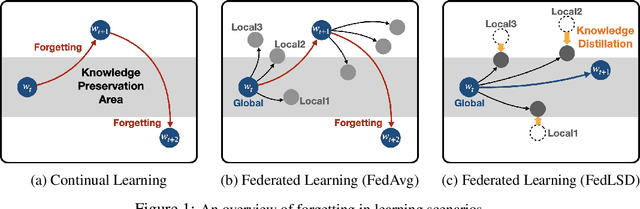


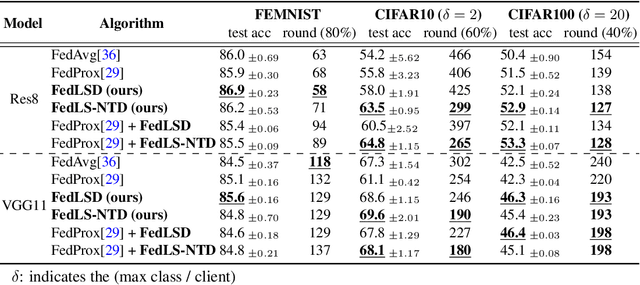
In Federated Learning (FL), a strong global model is collaboratively learned by aggregating the clients' locally trained models. Although this allows no need to access clients' data directly, the global model's convergence often suffers from data heterogeneity. This paper suggests that forgetting could be the bottleneck of global convergence. We observe that fitting on biased local distribution shifts the feature on global distribution and results in forgetting of global knowledge. We consider this phenomenon as an analogy to Continual Learning, which also faces catastrophic forgetting when fitted on the new task distribution. Based on our findings, we hypothesize that tackling down the forgetting in local training relives the data heterogeneity problem. To this end, we propose a simple yet effective framework Federated Local Self-Distillation (FedLSD), which utilizes the global knowledge on locally available data. By following the global perspective on local data, FedLSD encourages the learned features to preserve global knowledge and have consistent views across local models, thus improving convergence without compromising data privacy. Under our framework, we further extend FedLSD to FedLS-NTD, which only considers the not-true class signals to compensate noisy prediction of the global model. We validate that both FedLSD and FedLS-NTD significantly improve the performance in standard FL benchmarks in various setups, especially in the extreme data heterogeneity cases.