 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFOAM: Frequency and Operator Error-Based Adaptive Damping Method for Reducing Staleness-Oriented Error for Shampoo
Jun 01, 2026Shampoo is attracting considerable attention for its superior performance on large-scale optimization benchmarks; yet it faces a significant practical bottleneck: the prohibitive computational overhead of matrix inversion. To mitigate this, practitioners typically rely on stale preconditioner updates, creating a fundamental trade-off between computational efficiency and optimization fidelity. In this work, we provide a theoretical study of staleness through the complementary lenses of convergence and stability. While staleness improves computational efficiency, it inherently degrades performance and introduces numerical instability. Crucially, we identify that damping, acting as a numerical stabilizer, can effectively suppress these negative effects. Guided by this analysis, we propose FOAM, an adaptive algorithm that stabilizes training by dynamically controlling both the damping factor and the eigendecomposition frequency based on an approximation of the staleness-oriented error. Experimental results demonstrate that FOAM reduces wall-clock time compared to standard Shampoo while maintaining robust convergence.
Neuro-RIT: Neuron-Guided Instruction Tuning for Robust Retrieval-Augmented Language Model
Apr 02, 2026Retrieval-Augmented Language Models (RALMs) have demonstrated significant potential in knowledge-intensive tasks; however, they remain vulnerable to performance degradation when presented with irrelevant or noisy retrieved contexts. Existing approaches to enhance robustness typically operate via coarse-grained parameter updates at the layer or module level, often overlooking the inherent neuron-level sparsity of Large Language Models (LLMs). To address this limitation, we propose Neuro-RIT (Neuron-guided Robust Instruction Tuning), a novel framework that shifts the paradigm from dense adaptation to precision-driven neuron alignment. Our method explicitly disentangles neurons that are responsible for processing relevant versus irrelevant contexts using attribution-based neuron mining. Subsequently, we introduce a two-stage instruction tuning strategy that enforces a dual capability for noise robustness: achieving direct noise suppression by functionally deactivating neurons exclusive to irrelevant contexts, while simultaneously optimizing targeted layers for evidence distillation. Extensive experiments across diverse QA benchmarks demonstrate that Neuro-RIT consistently outperforms strong baselines and robustness-enhancing methods.
When and Where to Attack? Stage-wise Attention-Guided Adversarial Attack on Large Vision Language Models
Feb 04, 2026Adversarial attacks against Large Vision-Language Models (LVLMs) are crucial for exposing safety vulnerabilities in modern multimodal systems. Recent attacks based on input transformations, such as random cropping, suggest that spatially localized perturbations can be more effective than global image manipulation. However, randomly cropping the entire image is inherently stochastic and fails to use the limited per-pixel perturbation budget efficiently. We make two key observations: (i) regional attention scores are positively correlated with adversarial loss sensitivity, and (ii) attacking high-attention regions induces a structured redistribution of attention toward subsequent salient regions. Based on these findings, we propose Stage-wise Attention-Guided Attack (SAGA), an attention-guided framework that progressively concentrates perturbations on high-attention regions. SAGA enables more efficient use of constrained perturbation budgets, producing highly imperceptible adversarial examples while consistently achieving state-of-the-art attack success rates across ten LVLMs. The source code is available at https://github.com/jackwaky/SAGA.
Distributed In-Context Learning under Non-IID Among Clients
Jul 31, 2024
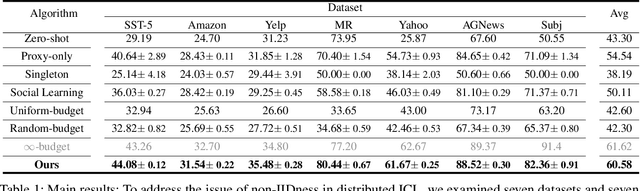
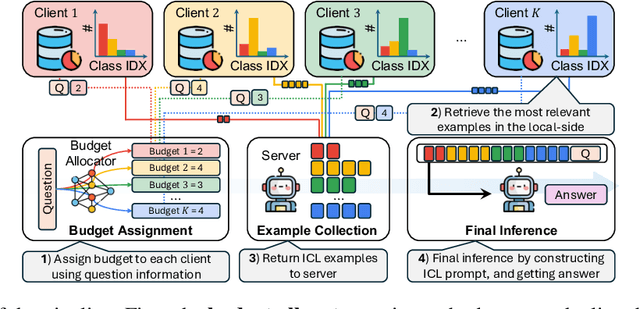
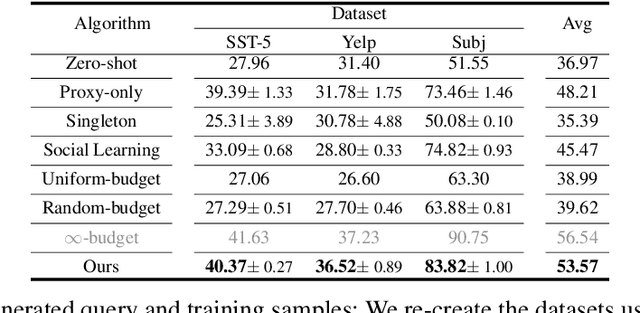
Advancements in large language models (LLMs) have shown their effectiveness in multiple complicated natural language reasoning tasks. A key challenge remains in adapting these models efficiently to new or unfamiliar tasks. In-context learning (ICL) provides a promising solution for few-shot adaptation by retrieving a set of data points relevant to a query, called in-context examples (ICE), from a training dataset and providing them during the inference as context. Most existing studies utilize a centralized training dataset, yet many real-world datasets may be distributed among multiple clients, and remote data retrieval can be associated with costs. Especially when the client data are non-identical independent distributions (non-IID), retrieving from clients a proper set of ICEs needed for a test query presents critical challenges. In this paper, we first show that in this challenging setting, test queries will have different preferences among clients because of non-IIDness, and equal contribution often leads to suboptimal performance. We then introduce a novel approach to tackle the distributed non-IID ICL problem when a data usage budget is present. The principle is that each client's proper contribution (budget) should be designed according to the preference of each query for that client. Our approach uses a data-driven manner to allocate a budget for each client, tailored to each test query. Through extensive empirical studies on diverse datasets, our framework demonstrates superior performance relative to competing baselines.
FedDr+: Stabilizing Dot-regression with Global Feature Distillation for Federated Learning
Jun 04, 2024Federated Learning (FL) has emerged as a pivotal framework for the development of effective global models (global FL) or personalized models (personalized FL) across clients with heterogeneous, non-iid data distribution. A key challenge in FL is client drift, where data heterogeneity impedes the aggregation of scattered knowledge. Recent studies have tackled the client drift issue by identifying significant divergence in the last classifier layer. To mitigate this divergence, strategies such as freezing the classifier weights and aligning the feature extractor accordingly have proven effective. Although the local alignment between classifier and feature extractor has been studied as a crucial factor in FL, we observe that it may lead the model to overemphasize the observed classes within each client. Thus, our objectives are twofold: (1) enhancing local alignment while (2) preserving the representation of unseen class samples. This approach aims to effectively integrate knowledge from individual clients, thereby improving performance for both global and personalized FL. To achieve this, we introduce a novel algorithm named FedDr+, which empowers local model alignment using dot-regression loss. FedDr+ freezes the classifier as a simplex ETF to align the features and improves aggregated global models by employing a feature distillation mechanism to retain information about unseen/missing classes. Consequently, we provide empirical evidence demonstrating that our algorithm surpasses existing methods that use a frozen classifier to boost alignment across the diverse distribution.
Augmented Risk Prediction for the Onset of Alzheimer's Disease from Electronic Health Records with Large Language Models
May 26, 2024



Alzheimer's disease (AD) is the fifth-leading cause of death among Americans aged 65 and older. Screening and early detection of AD and related dementias (ADRD) are critical for timely intervention and for identifying clinical trial participants. The widespread adoption of electronic health records (EHRs) offers an important resource for developing ADRD screening tools such as machine learning based predictive models. Recent advancements in large language models (LLMs) demonstrate their unprecedented capability of encoding knowledge and performing reasoning, which offers them strong potential for enhancing risk prediction. This paper proposes a novel pipeline that augments risk prediction by leveraging the few-shot inference power of LLMs to make predictions on cases where traditional supervised learning methods (SLs) may not excel. Specifically, we develop a collaborative pipeline that combines SLs and LLMs via a confidence-driven decision-making mechanism, leveraging the strengths of SLs in clear-cut cases and LLMs in more complex scenarios. We evaluate this pipeline using a real-world EHR data warehouse from Oregon Health \& Science University (OHSU) Hospital, encompassing EHRs from over 2.5 million patients and more than 20 million patient encounters. Our results show that our proposed approach effectively combines the power of SLs and LLMs, offering significant improvements in predictive performance. This advancement holds promise for revolutionizing ADRD screening and early detection practices, with potential implications for better strategies of patient management and thus improving healthcare.
Large Language Models in Medical Term Classification and Unexpected Misalignment Between Response and Reasoning
Dec 19, 2023
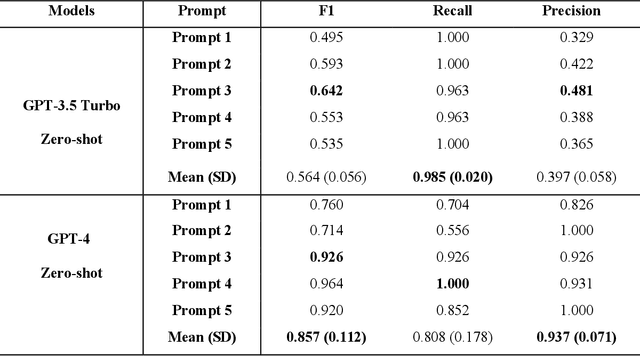

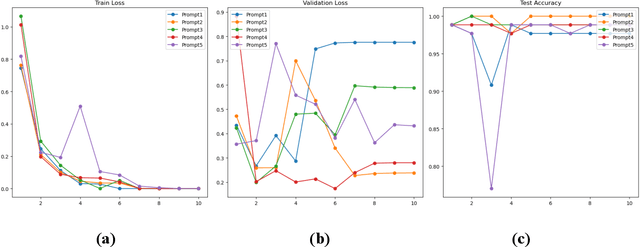
This study assesses the ability of state-of-the-art large language models (LLMs) including GPT-3.5, GPT-4, Falcon, and LLaMA 2 to identify patients with mild cognitive impairment (MCI) from discharge summaries and examines instances where the models' responses were misaligned with their reasoning. Utilizing the MIMIC-IV v2.2 database, we focused on a cohort aged 65 and older, verifying MCI diagnoses against ICD codes and expert evaluations. The data was partitioned into training, validation, and testing sets in a 7:2:1 ratio for model fine-tuning and evaluation, with an additional metastatic cancer dataset from MIMIC III used to further assess reasoning consistency. GPT-4 demonstrated superior interpretative capabilities, particularly in response to complex prompts, yet displayed notable response-reasoning inconsistencies. In contrast, open-source models like Falcon and LLaMA 2 achieved high accuracy but lacked explanatory reasoning, underscoring the necessity for further research to optimize both performance and interpretability. The study emphasizes the significance of prompt engineering and the need for further exploration into the unexpected reasoning-response misalignment observed in GPT-4. The results underscore the promise of incorporating LLMs into healthcare diagnostics, contingent upon methodological advancements to ensure accuracy and clinical coherence of AI-generated outputs, thereby improving the trustworthiness of LLMs for medical decision-making.
Active Prompt Learning in Vision Language Models
Nov 27, 2023



Pre-trained Vision Language Models (VLMs) have demonstrated notable progress in various zero-shot tasks, such as classification and retrieval. Despite their performance, because improving performance on new tasks requires task-specific knowledge, their adaptation is essential. While labels are needed for the adaptation, acquiring them is typically expensive. To overcome this challenge, active learning, a method of achieving a high performance by obtaining labels for a small number of samples from experts, has been studied. Active learning primarily focuses on selecting unlabeled samples for labeling and leveraging them to train models. In this study, we pose the question, "how can the pre-trained VLMs be adapted under the active learning framework?" In response to this inquiry, we observe that (1) simply applying a conventional active learning framework to pre-trained VLMs even may degrade performance compared to random selection because of the class imbalance in labeling candidates, and (2) the knowledge of VLMs can provide hints for achieving the balance before labeling. Based on these observations, we devise a novel active learning framework for VLMs, denoted as PCB. To assess the effectiveness of our approach, we conduct experiments on seven different real-world datasets, and the results demonstrate that PCB surpasses conventional active learning and random sampling methods.
Fine tuning Pre trained Models for Robustness Under Noisy Labels
Oct 24, 2023



The presence of noisy labels in a training dataset can significantly impact the performance of machine learning models. To tackle this issue, researchers have explored methods for Learning with Noisy Labels to identify clean samples and reduce the influence of noisy labels. However, constraining the influence of a certain portion of the training dataset can result in a reduction in overall generalization performance. To alleviate this, recent studies have considered the careful utilization of noisy labels by leveraging huge computational resources. Therefore, the increasing training cost necessitates a reevaluation of efficiency. In other areas of research, there has been a focus on developing fine-tuning techniques for large pre-trained models that aim to achieve both high generalization performance and efficiency. However, these methods have mainly concentrated on clean datasets, and there has been limited exploration of the noisy label scenario. In this research, our aim is to find an appropriate way to fine-tune pre-trained models for noisy labeled datasets. To achieve this goal, we investigate the characteristics of pre-trained models when they encounter noisy datasets. Through empirical analysis, we introduce a novel algorithm called TURN, which robustly and efficiently transfers the prior knowledge of pre-trained models. The algorithm consists of two main steps: (1) independently tuning the linear classifier to protect the feature extractor from being distorted by noisy labels, and (2) reducing the noisy label ratio and fine-tuning the entire model based on the noise-reduced dataset to adapt it to the target dataset. The proposed algorithm has been extensively tested and demonstrates efficient yet improved denoising performance on various benchmarks compared to previous methods.
NASH: A Simple Unified Framework of Structured Pruning for Accelerating Encoder-Decoder Language Models
Oct 16, 2023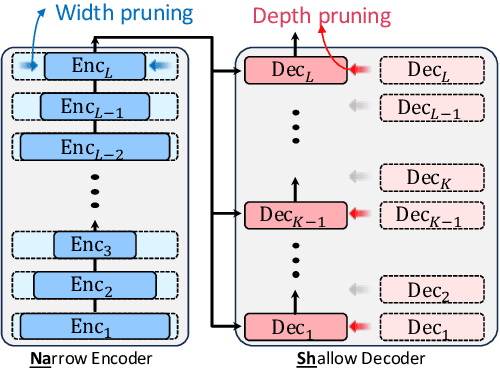


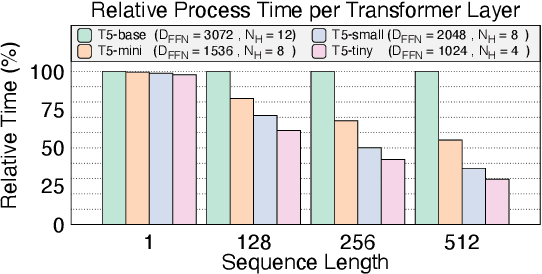
Structured pruning methods have proven effective in reducing the model size and accelerating inference speed in various network architectures such as Transformers. Despite the versatility of encoder-decoder models in numerous NLP tasks, the structured pruning methods on such models are relatively less explored compared to encoder-only models. In this study, we investigate the behavior of the structured pruning of the encoder-decoder models in the decoupled pruning perspective of the encoder and decoder component, respectively. Our findings highlight two insights: (1) the number of decoder layers is the dominant factor of inference speed, and (2) low sparsity in the pruned encoder network enhances generation quality. Motivated by these findings, we propose a simple and effective framework, NASH, that narrows the encoder and shortens the decoder networks of encoder-decoder models. Extensive experiments on diverse generation and inference tasks validate the effectiveness of our method in both speedup and output quality.