 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Diffusion via Hybrid Data-Pipeline Parallelism Based on Conditional Guidance Scheduling
Feb 25, 2026Diffusion models have achieved remarkable progress in high-fidelity image, video, and audio generation, yet inference remains computationally expensive. Nevertheless, current diffusion acceleration methods based on distributed parallelism suffer from noticeable generation artifacts and fail to achieve substantial acceleration proportional to the number of GPUs. Therefore, we propose a hybrid parallelism framework that combines a novel data parallel strategy, condition-based partitioning, with an optimal pipeline scheduling method, adaptive parallelism switching, to reduce generation latency and achieve high generation quality in conditional diffusion models. The key ideas are to (i) leverage the conditional and unconditional denoising paths as a new data-partitioning perspective and (ii) adaptively enable optimal pipeline parallelism according to the denoising discrepancy between these two paths. Our framework achieves $2.31\times$ and $2.07\times$ latency reductions on SDXL and SD3, respectively, using two NVIDIA RTX~3090 GPUs, while preserving image quality. This result confirms the generality of our approach across U-Net-based diffusion models and DiT-based flow-matching architectures. Our approach also outperforms existing methods in acceleration under high-resolution synthesis settings. Code is available at https://github.com/kaist-dmlab/Hybridiff.
See and Fix the Flaws: Enabling VLMs and Diffusion Models to Comprehend Visual Artifacts via Agentic Data Synthesis
Feb 24, 2026Despite recent advances in diffusion models, AI generated images still often contain visual artifacts that compromise realism. Although more thorough pre-training and bigger models might reduce artifacts, there is no assurance that they can be completely eliminated, which makes artifact mitigation a highly crucial area of study. Previous artifact-aware methodologies depend on human-labeled artifact datasets, which are costly and difficult to scale, underscoring the need for an automated approach to reliably acquire artifact-annotated datasets. In this paper, we propose ArtiAgent, which efficiently creates pairs of real and artifact-injected images. It comprises three agents: a perception agent that recognizes and grounds entities and subentities from real images, a synthesis agent that introduces artifacts via artifact injection tools through novel patch-wise embedding manipulation within a diffusion transformer, and a curation agent that filters the synthesized artifacts and generates both local and global explanations for each instance. Using ArtiAgent, we synthesize 100K images with rich artifact annotations and demonstrate both efficacy and versatility across diverse applications. Code is available at link.
Completing Missing Annotation: Multi-Agent Debate for Accurate and Scalable Relevant Assessment for IR Benchmarks
Feb 06, 2026Information retrieval (IR) evaluation remains challenging due to incomplete IR benchmark datasets that contain unlabeled relevant chunks. While LLMs and LLM-human hybrid strategies reduce costly human effort, they remain prone to LLM overconfidence and ineffective AI-to-human escalation. To address this, we propose DREAM, a multi-round debate-based relevance assessment framework with LLM agents, built on opposing initial stances and iterative reciprocal critique. Through our agreement-based debate, it yields more accurate labeling for certain cases and more reliable AI-to-human escalation for uncertain ones, achieving 95.2% labeling accuracy with only 3.5% human involvement. Using DREAM, we build BRIDGE, a refined benchmark that mitigates evaluation bias and enables fairer retriever comparison by uncovering 29,824 missing relevant chunks. We then re-benchmark IR systems and extend evaluation to RAG, showing that unaddressed holes not only distort retriever rankings but also drive retrieval-generation misalignment. The relevance assessment framework is available at https: //github.com/DISL-Lab/DREAM-ICLR-26; and the BRIDGE dataset is available at https://github.com/DISL-Lab/BRIDGE-Benchmark.
TimelyFreeze: Adaptive Parameter Freezing Mechanism for Pipeline Parallelism
Feb 05, 2026Pipeline parallelism enables training models that exceed single-device memory, but practical throughput remains limited by pipeline bubbles. Although parameter freezing can improve training throughput by adaptively skipping backward computation, existing methods often over-freeze parameters, resulting in unnecessary accuracy degradation. To address this issue, we propose TimelyFreeze, which models the pipeline schedule as a directed acyclic graph and solves a linear program to compute optimal freeze ratios that minimize batch execution time under accuracy constraints. Experiments show that TimelyFreeze achieves up to 40% training throughput improvement on LLaMA-8B with comparable accuracy. Overall, it enables faster large-scale model training without compromising convergence and generalizes across diverse pipeline-parallel settings.
Solar Open Technical Report
Jan 11, 2026We introduce Solar Open, a 102B-parameter bilingual Mixture-of-Experts language model for underserved languages. Solar Open demonstrates a systematic methodology for building competitive LLMs by addressing three interconnected challenges. First, to train effectively despite data scarcity for underserved languages, we synthesize 4.5T tokens of high-quality, domain-specific, and RL-oriented data. Second, we coordinate this data through a progressive curriculum jointly optimizing composition, quality thresholds, and domain coverage across 20 trillion tokens. Third, to enable reasoning capabilities through scalable RL, we apply our proposed framework SnapPO for efficient optimization. Across benchmarks in English and Korean, Solar Open achieves competitive performance, demonstrating the effectiveness of this methodology for underserved language AI development.
MONAQ: Multi-Objective Neural Architecture Querying for Time-Series Analysis on Resource-Constrained Devices
May 15, 2025



The growing use of smartphones and IoT devices necessitates efficient time-series analysis on resource-constrained hardware, which is critical for sensing applications such as human activity recognition and air quality prediction. Recent efforts in hardware-aware neural architecture search (NAS) automate architecture discovery for specific platforms; however, none focus on general time-series analysis with edge deployment. Leveraging the problem-solving and reasoning capabilities of large language models (LLM), we propose MONAQ, a novel framework that reformulates NAS into Multi-Objective Neural Architecture Querying tasks. MONAQ is equipped with multimodal query generation for processing multimodal time-series inputs and hardware constraints, alongside an LLM agent-based multi-objective search to achieve deployment-ready models via code generation. By integrating numerical data, time-series images, and textual descriptions, MONAQ improves an LLM's understanding of time-series data. Experiments on fifteen datasets demonstrate that MONAQ-discovered models outperform both handcrafted models and NAS baselines while being more efficient.
References Indeed Matter? Reference-Free Preference Optimization for Conversational Query Reformulation
May 10, 2025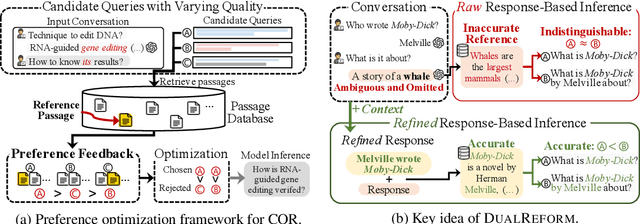
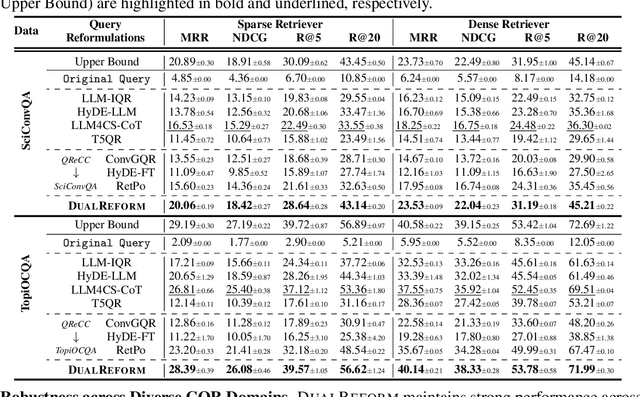
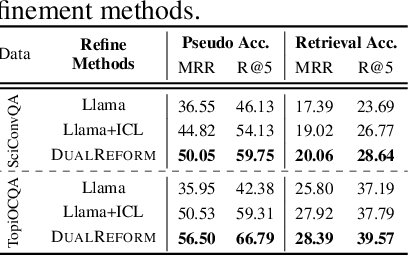
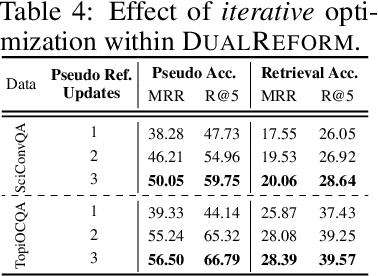
Conversational query reformulation (CQR) has become indispensable for improving retrieval in dialogue-based applications. However, existing approaches typically rely on reference passages for optimization, which are impractical to acquire in real-world scenarios. To address this limitation, we introduce a novel reference-free preference optimization framework DualReform that generates pseudo reference passages from commonly-encountered conversational datasets containing only queries and responses. DualReform attains this goal through two key innovations: (1) response-based inference, where responses serve as proxies to infer pseudo reference passages, and (2) response refinement via the dual-role of CQR, where a CQR model refines responses based on the shared objectives between response refinement and CQR. Despite not relying on reference passages, DualReform achieves 96.9--99.1% of the retrieval accuracy attainable only with reference passages and surpasses the state-of-the-art method by up to 31.6%.
VarDrop: Enhancing Training Efficiency by Reducing Variate Redundancy in Periodic Time Series Forecasting
Jan 24, 2025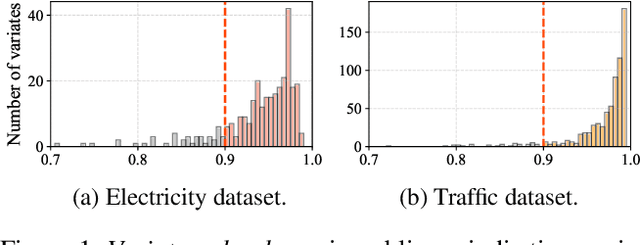
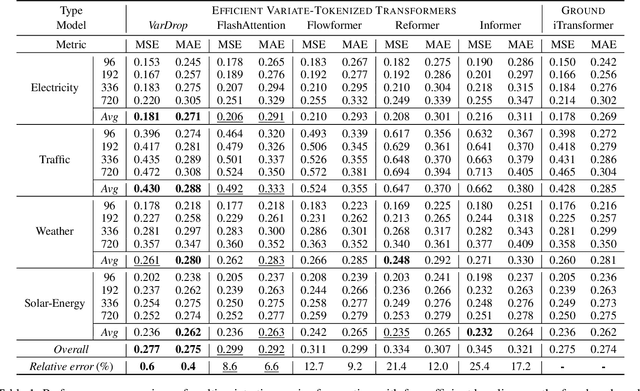
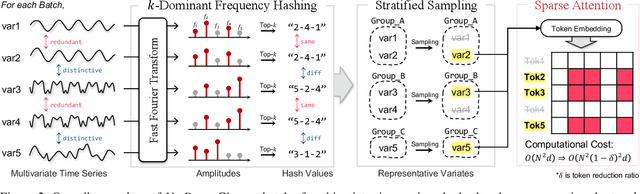
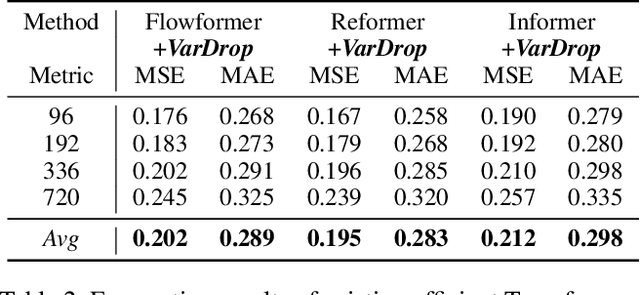
Variate tokenization, which independently embeds each variate as separate tokens, has achieved remarkable improvements in multivariate time series forecasting. However, employing self-attention with variate tokens incurs a quadratic computational cost with respect to the number of variates, thus limiting its training efficiency for large-scale applications. To address this issue, we propose VarDrop, a simple yet efficient strategy that reduces the token usage by omitting redundant variate tokens during training. VarDrop adaptively excludes redundant tokens within a given batch, thereby reducing the number of tokens used for dot-product attention while preserving essential information. Specifically, we introduce k-dominant frequency hashing (k-DFH), which utilizes the ranked dominant frequencies in the frequency domain as a hash value to efficiently group variate tokens exhibiting similar periodic behaviors. Then, only representative tokens in each group are sampled through stratified sampling. By performing sparse attention with these selected tokens, the computational cost of scaled dot-product attention is significantly alleviated. Experiments conducted on public benchmark datasets demonstrate that VarDrop outperforms existing efficient baselines.
Active Learning for Continual Learning: Keeping the Past Alive in the Present
Jan 24, 2025



Continual learning (CL) enables deep neural networks to adapt to ever-changing data distributions. In practice, there may be scenarios where annotation is costly, leading to active continual learning (ACL), which performs active learning (AL) for the CL scenarios when reducing the labeling cost by selecting the most informative subset is preferable. However, conventional AL strategies are not suitable for ACL, as they focus solely on learning the new knowledge, leading to catastrophic forgetting of previously learned tasks. Therefore, ACL requires a new AL strategy that can balance the prevention of catastrophic forgetting and the ability to quickly learn new tasks. In this paper, we propose AccuACL, Accumulated informativeness-based Active Continual Learning, by the novel use of the Fisher information matrix as a criterion for sample selection, derived from a theoretical analysis of the Fisher-optimality preservation properties within the framework of ACL, while also addressing the scalability issue of Fisher information-based AL. Extensive experiments demonstrate that AccuACL significantly outperforms AL baselines across various CL algorithms, increasing the average accuracy and forgetting by 23.8% and 17.0%, respectively, in average.
Continuous-Time Linear Positional Embedding for Irregular Time Series Forecasting
Sep 30, 2024
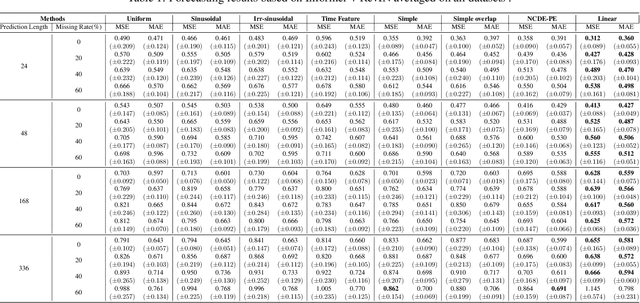


Irregularly sampled time series forecasting, characterized by non-uniform intervals, is prevalent in practical applications. However, previous research have been focused on regular time series forecasting, typically relying on transformer architectures. To extend transformers to handle irregular time series, we tackle the positional embedding which represents the temporal information of the data. We propose CTLPE, a method learning a continuous linear function for encoding temporal information. The two challenges of irregular time series, inconsistent observation patterns and irregular time gaps, are solved by learning a continuous-time function and concise representation of position. Additionally, the linear continuous function is empirically shown superior to other continuous functions by learning a neural controlled differential equation-based positional embedding, and theoretically supported with properties of ideal positional embedding. CTLPE outperforms existing techniques across various irregularly-sampled time series datasets, showcasing its enhanced efficacy.