 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVarDrop: Enhancing Training Efficiency by Reducing Variate Redundancy in Periodic Time Series Forecasting
Jan 24, 2025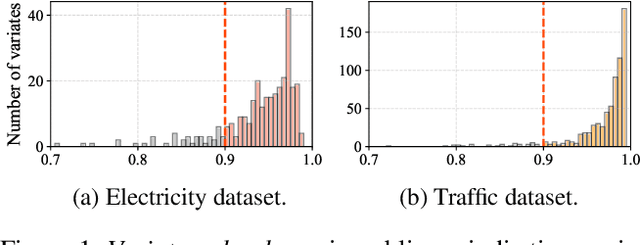
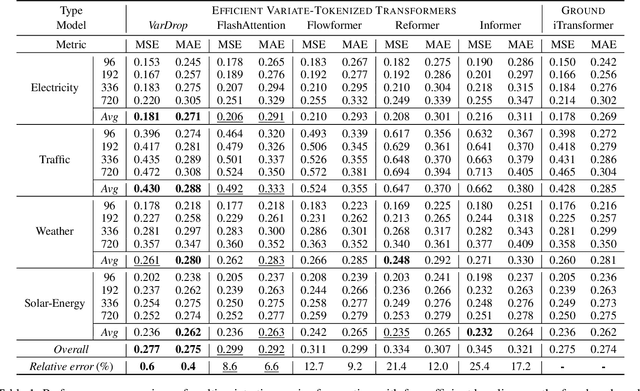
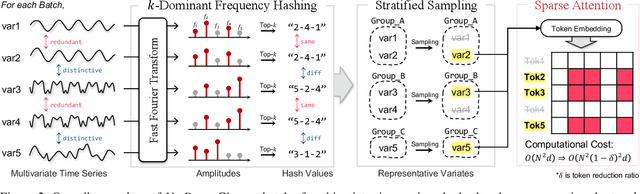
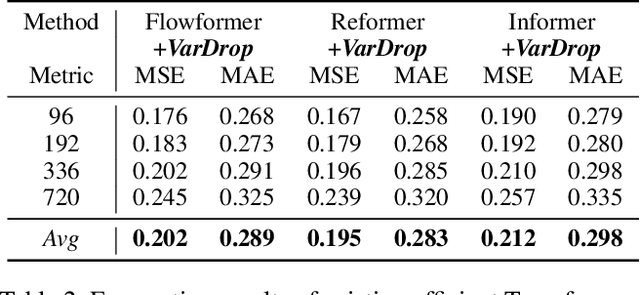
Variate tokenization, which independently embeds each variate as separate tokens, has achieved remarkable improvements in multivariate time series forecasting. However, employing self-attention with variate tokens incurs a quadratic computational cost with respect to the number of variates, thus limiting its training efficiency for large-scale applications. To address this issue, we propose VarDrop, a simple yet efficient strategy that reduces the token usage by omitting redundant variate tokens during training. VarDrop adaptively excludes redundant tokens within a given batch, thereby reducing the number of tokens used for dot-product attention while preserving essential information. Specifically, we introduce k-dominant frequency hashing (k-DFH), which utilizes the ranked dominant frequencies in the frequency domain as a hash value to efficiently group variate tokens exhibiting similar periodic behaviors. Then, only representative tokens in each group are sampled through stratified sampling. By performing sparse attention with these selected tokens, the computational cost of scaled dot-product attention is significantly alleviated. Experiments conducted on public benchmark datasets demonstrate that VarDrop outperforms existing efficient baselines.
Universal Time-Series Representation Learning: A Survey
Jan 08, 2024



Time-series data exists in every corner of real-world systems and services, ranging from satellites in the sky to wearable devices on human bodies. Learning representations by extracting and inferring valuable information from these time series is crucial for understanding the complex dynamics of particular phenomena and enabling informed decisions. With the learned representations, we can perform numerous downstream analyses more effectively. Among several approaches, deep learning has demonstrated remarkable performance in extracting hidden patterns and features from time-series data without manual feature engineering. This survey first presents a novel taxonomy based on three fundamental elements in designing state-of-the-art universal representation learning methods for time series. According to the proposed taxonomy, we comprehensively review existing studies and discuss their intuitions and insights into how these methods enhance the quality of learned representations. Finally, as a guideline for future studies, we summarize commonly used experimental setups and datasets and discuss several promising research directions. An up-to-date corresponding resource is available at https://github.com/itouchz/awesome-deep-time-series-representations.
Adaptive Shortcut Debiasing for Online Continual Learning
Dec 14, 2023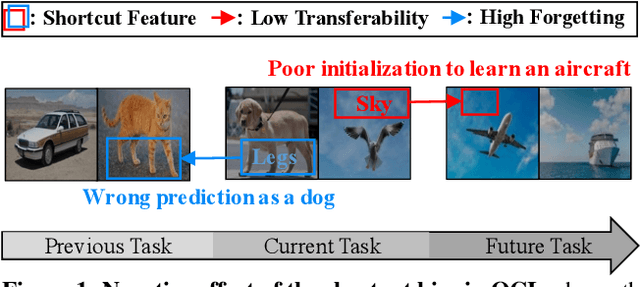
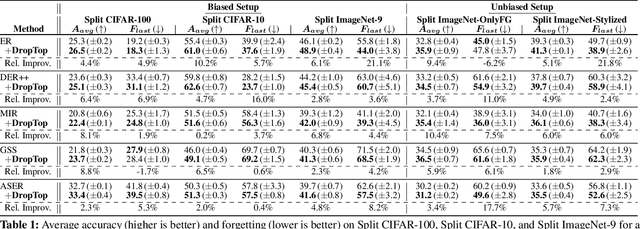
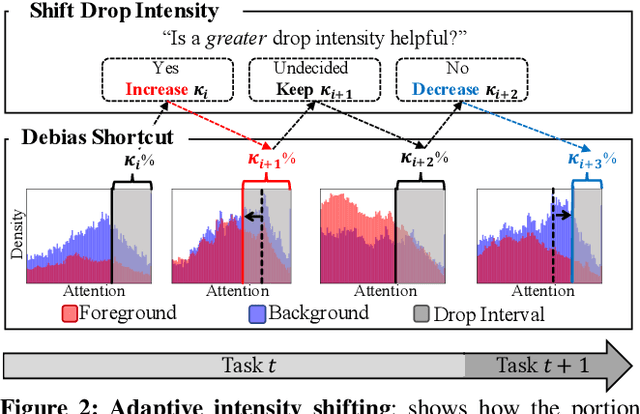

We propose a novel framework DropTop that suppresses the shortcut bias in online continual learning (OCL) while being adaptive to the varying degree of the shortcut bias incurred by continuously changing environment. By the observed high-attention property of the shortcut bias, highly-activated features are considered candidates for debiasing. More importantly, resolving the limitation of the online environment where prior knowledge and auxiliary data are not ready, two novel techniques -- feature map fusion and adaptive intensity shifting -- enable us to automatically determine the appropriate level and proportion of the candidate shortcut features to be dropped. Extensive experiments on five benchmark datasets demonstrate that, when combined with various OCL algorithms, DropTop increases the average accuracy by up to 10.4% and decreases the forgetting by up to 63.2%.
Meta-Query-Net: Resolving Purity-Informativeness Dilemma in Open-set Active Learning
Oct 13, 2022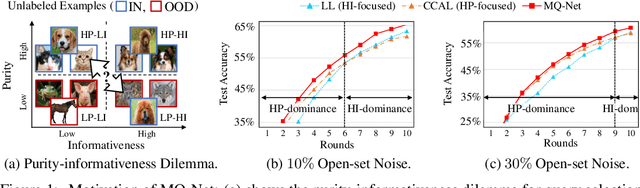
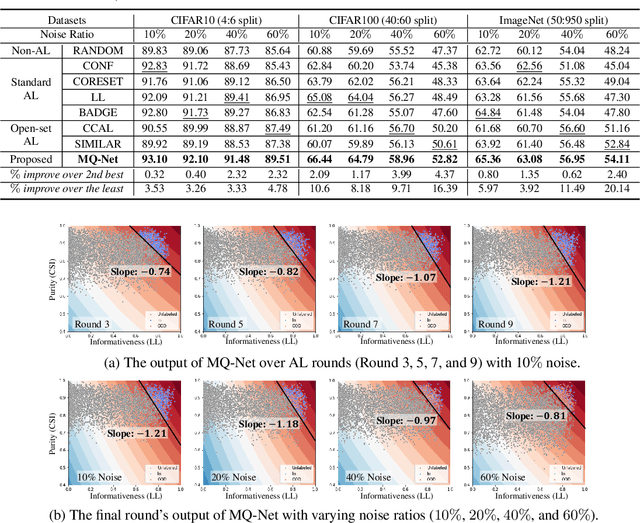
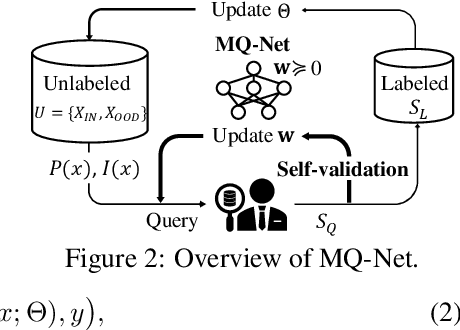
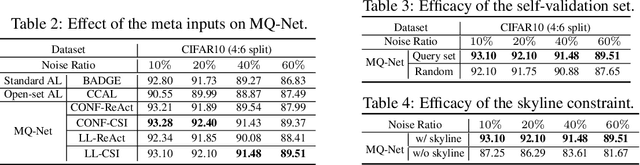
Unlabeled data examples awaiting annotations contain open-set noise inevitably. A few active learning studies have attempted to deal with this open-set noise for sample selection by filtering out the noisy examples. However, because focusing on the purity of examples in a query set leads to overlooking the informativeness of the examples, the best balancing of purity and informativeness remains an important question. In this paper, to solve this purity-informativeness dilemma in open-set active learning, we propose a novel Meta-Query-Net,(MQ-Net) that adaptively finds the best balancing between the two factors. Specifically, by leveraging the multi-round property of active learning, we train MQ-Net using a query set without an additional validation set. Furthermore, a clear dominance relationship between unlabeled examples is effectively captured by MQ-Net through a novel skyline regularization. Extensive experiments on multiple open-set active learning scenarios demonstrate that the proposed MQ-Net achieves 20.14% improvement in terms of accuracy, compared with the state-of-the-art methods.
Meta-Learning for Online Update of Recommender Systems
Mar 19, 2022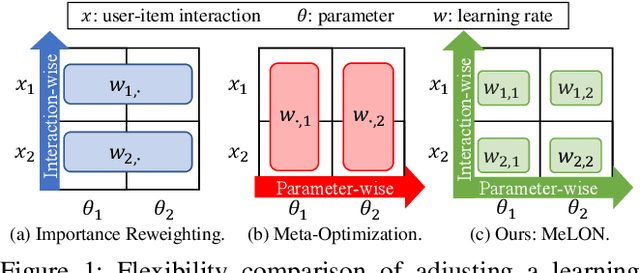
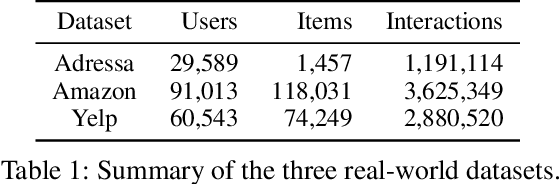
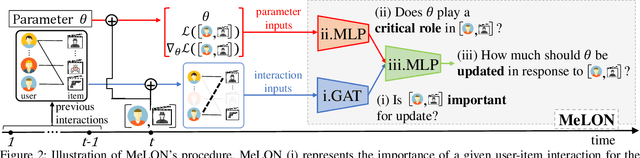
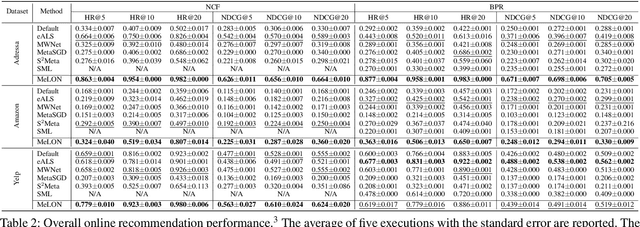
Online recommender systems should be always aligned with users' current interest to accurately suggest items that each user would like. Since user interest usually evolves over time, the update strategy should be flexible to quickly catch users' current interest from continuously generated new user-item interactions. Existing update strategies focus either on the importance of each user-item interaction or the learning rate for each recommender parameter, but such one-directional flexibility is insufficient to adapt to varying relationships between interactions and parameters. In this paper, we propose MeLON, a meta-learning based novel online recommender update strategy that supports two-directional flexibility. It is featured with an adaptive learning rate for each parameter-interaction pair for inducing a recommender to quickly learn users' up-to-date interest. The procedure of MeLON is optimized following a meta-learning approach: it learns how a recommender learns to generate the optimal learning rates for future updates. Specifically, MeLON first enriches the meaning of each interaction based on previous interactions and identifies the role of each parameter for the interaction; and then combines these two pieces of information to generate an adaptive learning rate. Theoretical analysis and extensive evaluation on three real-world online recommender datasets validate the effectiveness of MeLON.
* 11 pages, 6 figures
Accurate and Fast Federated Learning via IID and Communication-Aware Grouping
Dec 09, 2020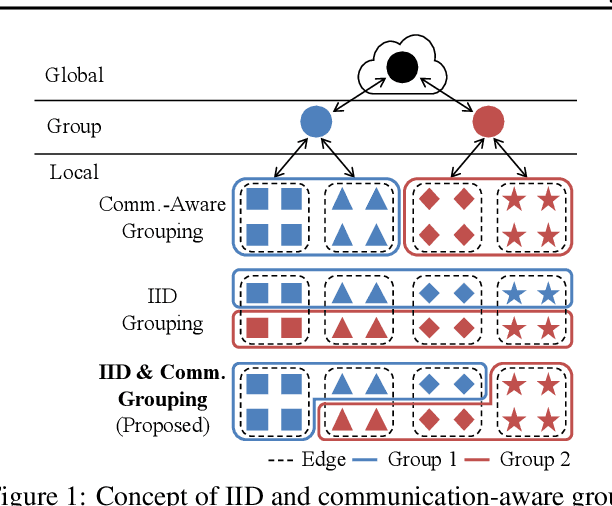

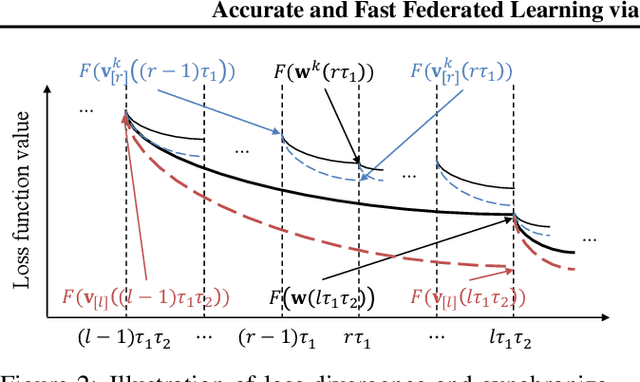
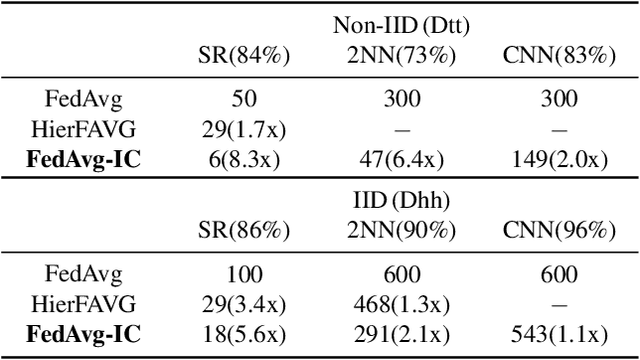
Federated learning has emerged as a new paradigm of collaborative machine learning; however, it has also faced several challenges such as non-independent and identically distributed(IID) data and high communication cost. To this end, we propose a novel framework of IID and communication-aware group federated learning that simultaneously maximizes both accuracy and communication speed by grouping nodes based on data distributions and physical locations of the nodes. Furthermore, we provide a formal convergence analysis and an efficient optimization algorithm called FedAvg-IC. Experimental results show that, compared with the state-of-the-art algorithms, FedAvg-IC improved the test accuracy by up to 22.2% and simultaneously reduced the communication time to as small as 12%.