 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHouse of Cards: Massive Weights in LLMs
Oct 02, 2024



Massive activations, which manifest in specific feature dimensions of hidden states, introduce a significant bias in large language models (LLMs), leading to an overemphasis on the corresponding token. In this paper, we identify that massive activations originate not from the hidden state but from the intermediate state of a feed-forward network module in an early layer. Expanding on the previous observation that massive activations occur only in specific feature dimensions, we dive deep into the weights that cause massive activations. Specifically, we define top-$k$ massive weights as the weights that contribute to the dimensions with the top-$k$ magnitudes in the intermediate state. When these massive weights are set to zero, the functionality of LLMs is entirely disrupted. However, when all weights except for massive weights are set to zero, it results in a relatively minor performance drop, even though a much larger number of weights are set to zero. This implies that during the pre-training process, learning is dominantly focused on massive weights. Building on this observation, we propose a simple plug-and-play method called MacDrop (massive weights curriculum dropout), to rely less on massive weights during parameter-efficient fine-tuning. This method applies dropout to the pre-trained massive weights, starting with a high dropout probability and gradually decreasing it as fine-tuning progresses. Through experiments, we demonstrate that MacDrop generally improves performance across zero-shot downstream tasks and generation tasks.
BAPO: Base-Anchored Preference Optimization for Personalized Alignment in Large Language Models
Jun 30, 2024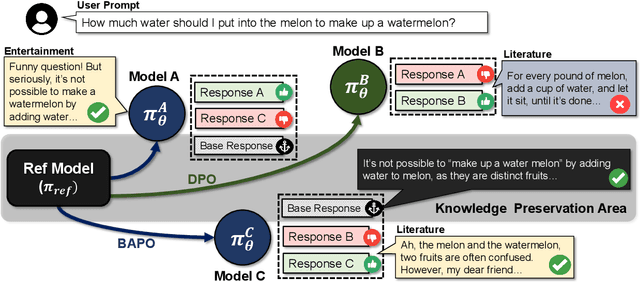
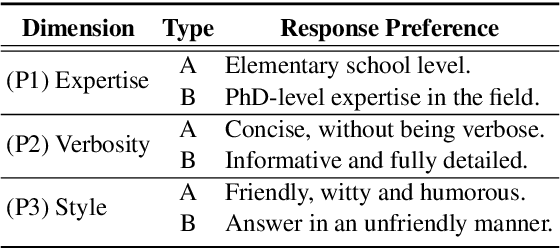
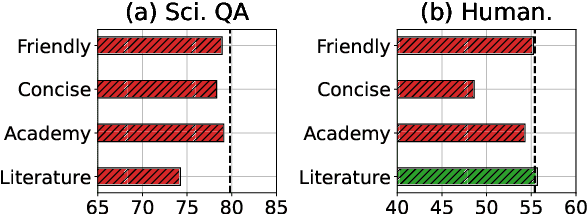
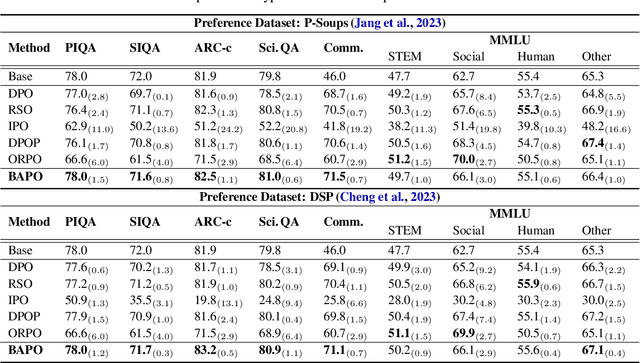
While learning to align Large Language Models (LLMs) with human preferences has shown remarkable success, aligning these models to meet the diverse user preferences presents further challenges in preserving previous knowledge. This paper examines the impact of personalized preference optimization on LLMs, revealing that the extent of knowledge loss varies significantly with preference heterogeneity. Although previous approaches have utilized the KL constraint between the reference model and the policy model, we observe that they fail to maintain general knowledge and alignment when facing personalized preferences. To this end, we introduce Base-Anchored Preference Optimization (BAPO), a simple yet effective approach that utilizes the initial responses of reference model to mitigate forgetting while accommodating personalized alignment. BAPO effectively adapts to diverse user preferences while minimally affecting global knowledge or general alignment. Our experiments demonstrate the efficacy of BAPO in various setups.
FedFN: Feature Normalization for Alleviating Data Heterogeneity Problem in Federated Learning
Nov 22, 2023Federated Learning (FL) is a collaborative method for training models while preserving data privacy in decentralized settings. However, FL encounters challenges related to data heterogeneity, which can result in performance degradation. In our study, we observe that as data heterogeneity increases, feature representation in the FedAVG model deteriorates more significantly compared to classifier weight. Additionally, we observe that as data heterogeneity increases, the gap between higher feature norms for observed classes, obtained from local models, and feature norms of unobserved classes widens, in contrast to the behavior of classifier weight norms. This widening gap extends to encompass the feature norm disparities between local and the global models. To address these issues, we introduce Federated Averaging with Feature Normalization Update (FedFN), a straightforward learning method. We demonstrate the superior performance of FedFN through extensive experiments, even when applied to pretrained ResNet18. Subsequently, we confirm the applicability of FedFN to foundation models.
Cross-Modal Retrieval Meets Inference:Improving Zero-Shot Classification with Cross-Modal Retrieval
Aug 29, 2023
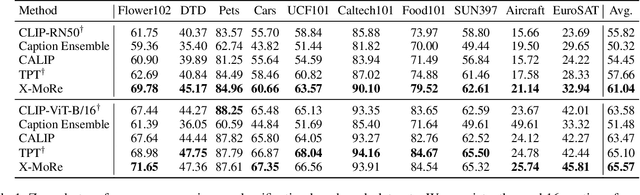
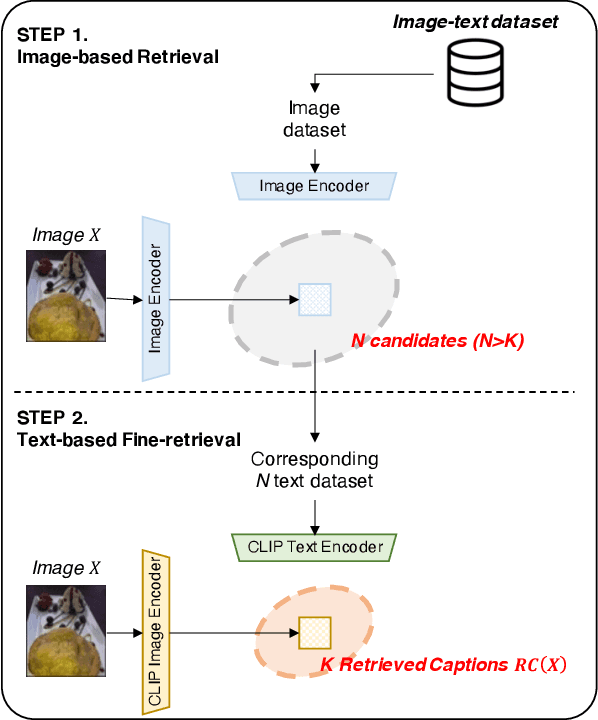

Contrastive language-image pre-training (CLIP) has demonstrated remarkable zero-shot classification ability, namely image classification using novel text labels. Existing works have attempted to enhance CLIP by fine-tuning on downstream tasks, but these have inadvertently led to performance degradation on unseen classes, thus harming zero-shot generalization. This paper aims to address this challenge by leveraging readily available image-text pairs from an external dataset for cross-modal guidance during inference. To this end, we propose X-MoRe, a novel inference method comprising two key steps: (1) cross-modal retrieval and (2) modal-confidence-based ensemble. Given a query image, we harness the power of CLIP's cross-modal representations to retrieve relevant textual information from an external image-text pair dataset. Then, we assign higher weights to the more reliable modality between the original query image and retrieved text, contributing to the final prediction. X-MoRe demonstrates robust performance across a diverse set of tasks without the need for additional training, showcasing the effectiveness of utilizing cross-modal features to maximize CLIP's zero-shot ability.
FedSoL: Bridging Global Alignment and Local Generality in Federated Learning
Aug 24, 2023



Federated Learning (FL) aggregates locally trained models from individual clients to construct a global model. While FL enables learning a model with data privacy, it often suffers from significant performance degradation when client data distributions are heterogeneous. Many previous FL algorithms have addressed this issue by introducing various proximal restrictions. These restrictions aim to encourage global alignment by constraining the deviation of local learning from the global objective. However, they inherently limit local learning by interfering with the original local objectives. Recently, an alternative approach has emerged to improve local learning generality. By obtaining local models within a smooth loss landscape, this approach mitigates conflicts among different local objectives of the clients. Yet, it does not ensure stable global alignment, as local learning does not take the global objective into account. In this study, we propose Federated Stability on Learning (FedSoL), which combines both the concepts of global alignment and local generality. In FedSoL, the local learning seeks a parameter region robust against proximal perturbations. This strategy introduces an implicit proximal restriction effect in local learning while maintaining the original local objective for parameter update. Our experiments show that FedSoL consistently achieves state-of-the-art performance on various setups.
Synergy with Translation Artifacts for Training and Inference in Multilingual Tasks
Oct 18, 2022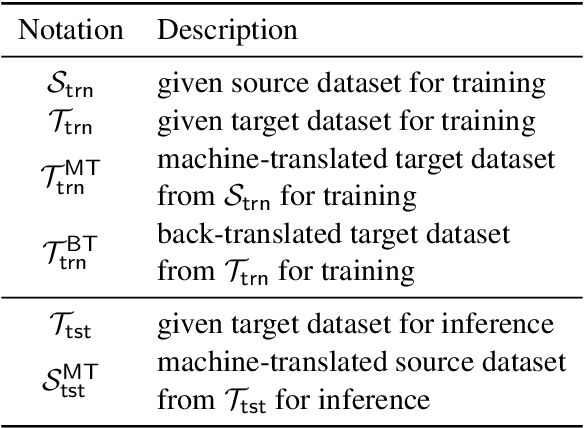



Translation has played a crucial role in improving the performance on multilingual tasks: (1) to generate the target language data from the source language data for training and (2) to generate the source language data from the target language data for inference. However, prior works have not considered the use of both translations simultaneously. This paper shows that combining them can synergize the results on various multilingual sentence classification tasks. We empirically find that translation artifacts stylized by translators are the main factor of the performance gain. Based on this analysis, we adopt two training methods, SupCon and MixUp, considering translation artifacts. Furthermore, we propose a cross-lingual fine-tuning algorithm called MUSC, which uses SupCon and MixUp jointly and improves the performance. Our code is available at https://github.com/jongwooko/MUSC.
Demystifying the Base and Novel Performances for Few-shot Class-incremental Learning
Jun 18, 2022

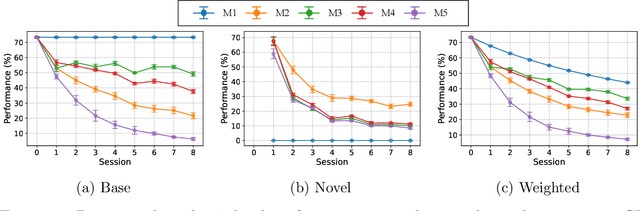

Few-shot class-incremental learning (FSCIL) has addressed challenging real-world scenarios where unseen novel classes continually arrive with few samples. In these scenarios, it is required to develop a model that recognizes the novel classes without forgetting prior knowledge. In other words, FSCIL aims to maintain the base performance and improve the novel performance simultaneously. However, there is little study to investigate the two performances separately. In this paper, we first decompose the entire model into four types of parameters and demonstrate that the tendency of the two performances varies greatly with the updated parameters when the novel classes appear. Based on the analysis, we propose a simple method for FSCIL, coined as NoNPC, which uses normalized prototype classifiers without further training for incremental novel classes. It is shown that our straightforward method has comparable performance with the sophisticated state-of-the-art algorithms.
Revisiting the Updates of a Pre-trained Model for Few-shot Learning
May 13, 2022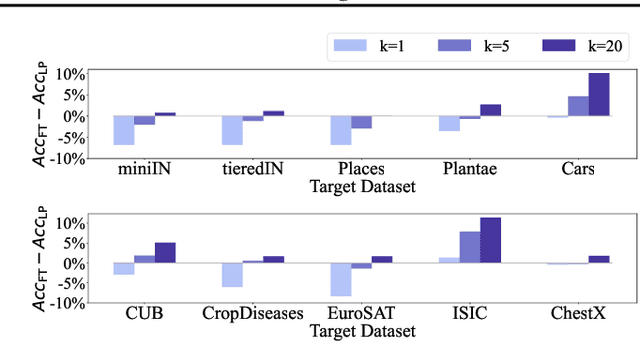
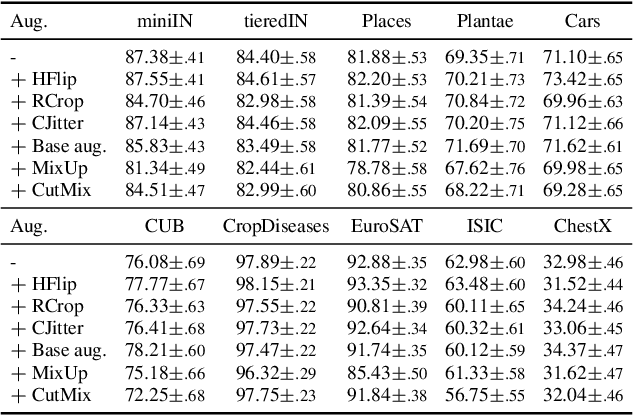
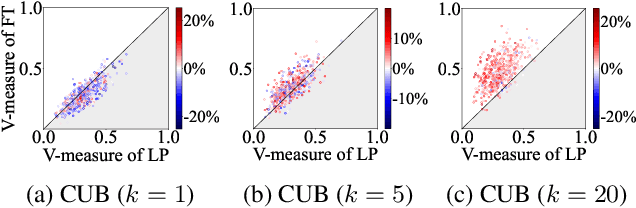
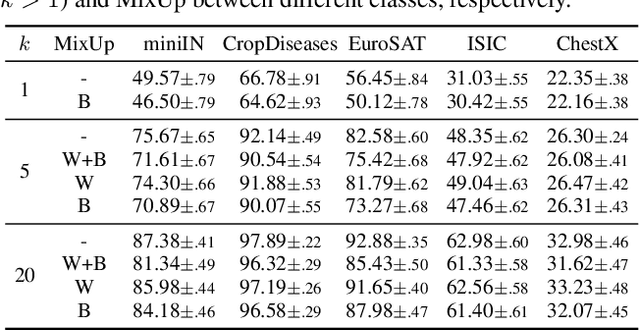
Most of the recent few-shot learning algorithms are based on transfer learning, where a model is pre-trained using a large amount of source data, and the pre-trained model is updated using a small amount of target data afterward. In transfer-based few-shot learning, sophisticated pre-training methods have been widely studied for universal and improved representation. However, there is little study on updating pre-trained models for few-shot learning. In this paper, we compare the two popular updating methods, fine-tuning (i.e., updating the entire network) and linear probing (i.e., updating only the linear classifier), considering the distribution shift between the source and target data. We find that fine-tuning is better than linear probing as the number of samples increases, regardless of distribution shift. Next, we investigate the effectiveness and ineffectiveness of data augmentation when pre-trained models are fine-tuned. Our fundamental analyses demonstrate that careful considerations of the details about updating pre-trained models are required for better few-shot performance.
ReFine: Re-randomization before Fine-tuning for Cross-domain Few-shot Learning
May 11, 2022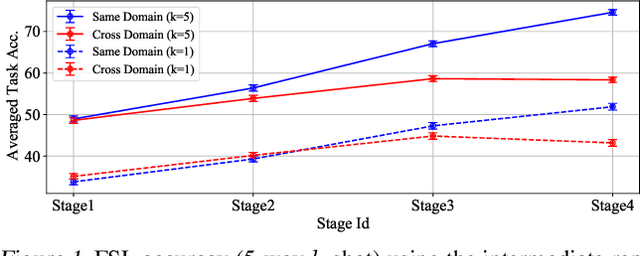
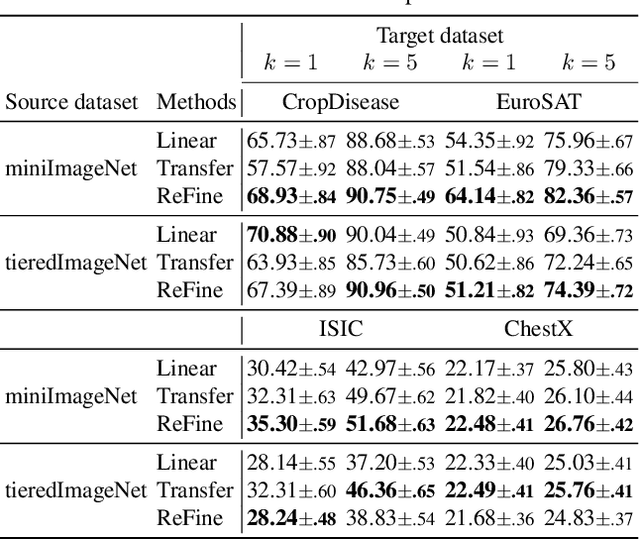
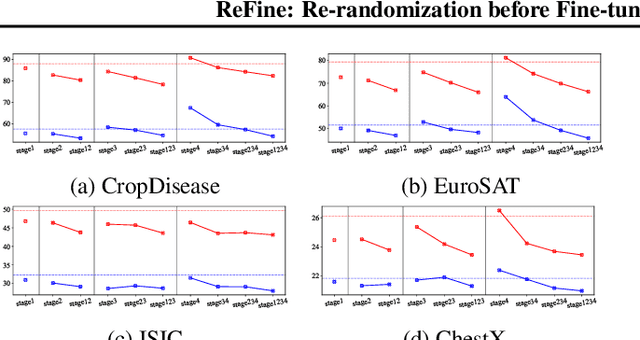
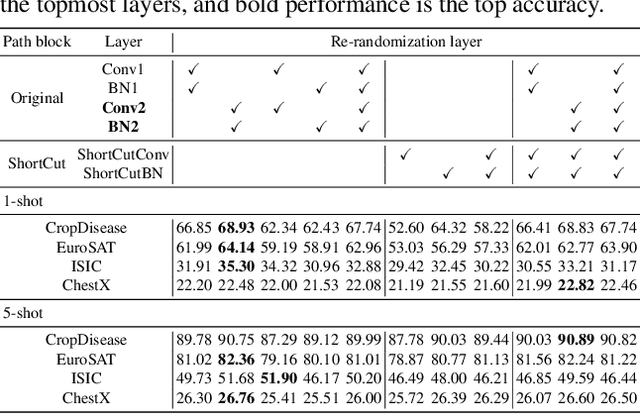
Cross-domain few-shot learning (CD-FSL), where there are few target samples under extreme differences between source and target domains, has recently attracted huge attention. For CD-FSL, recent studies generally have developed transfer learning based approaches that pre-train a neural network on popular labeled source domain datasets and then transfer it to target domain data. Although the labeled datasets may provide suitable initial parameters for the target data, the domain difference between the source and target might hinder the fine-tuning on the target domain. This paper proposes a simple yet powerful method that re-randomizes the parameters fitted on the source domain before adapting to the target data. The re-randomization resets source-specific parameters of the source pre-trained model and thus facilitates fine-tuning on the target domain, improving few-shot performance.
Understanding Cross-Domain Few-Shot Learning: An Experimental Study
Feb 08, 2022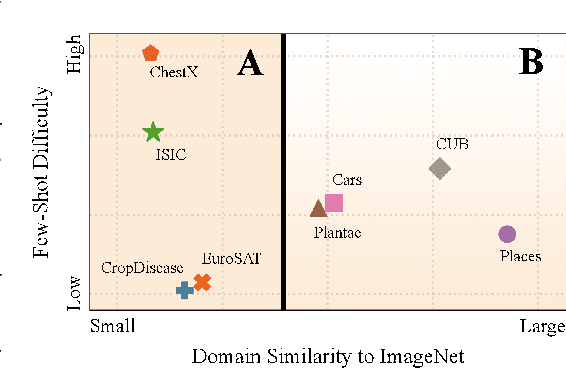
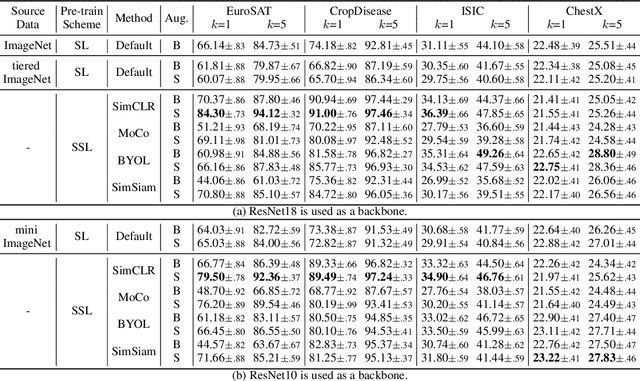
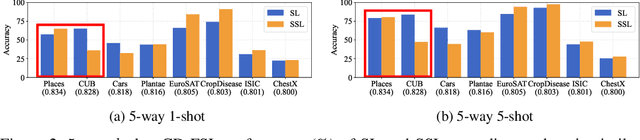
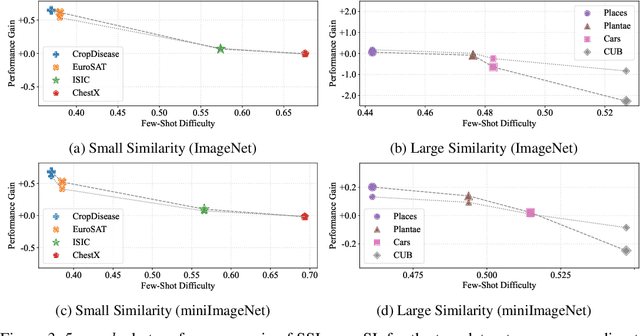
Cross-domain few-shot learning has drawn increasing attention for handling large differences between the source and target domains--an important concern in real-world scenarios. To overcome these large differences, recent works have considered exploiting small-scale unlabeled data from the target domain during the pre-training stage. This data enables self-supervised pre-training on the target domain, in addition to supervised pre-training on the source domain. In this paper, we empirically investigate scenarios under which it is advantageous to use each pre-training scheme, based on domain similarity and few-shot difficulty: performance gain of self-supervised pre-training over supervised pre-training increases when domain similarity is smaller or few-shot difficulty is lower. We further design two pre-training schemes, mixed-supervised and two-stage learning, that improve performance. In this light, we present seven findings for CD-FSL which are supported by extensive experiments and analyses on three source and eight target benchmark datasets with varying levels of domain similarity and few-shot difficulty. Our code is available at https://anonymous.4open.science/r/understandingCDFSL.