 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Summarize from LLM-generated Feedback
Oct 17, 2024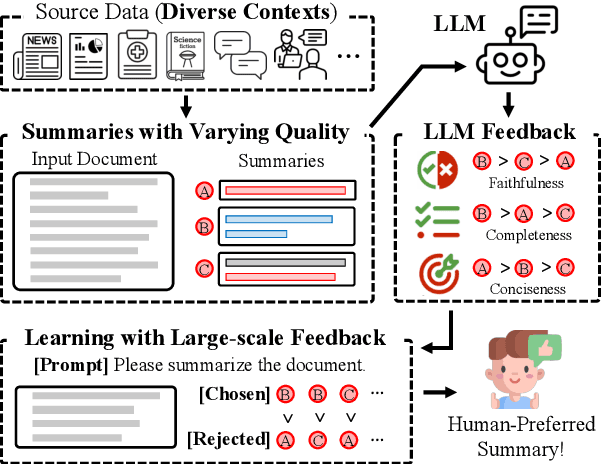


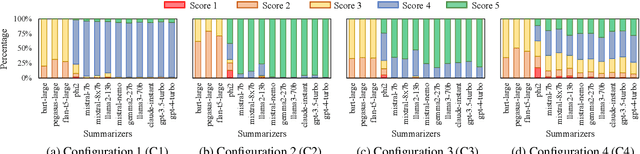
Developing effective text summarizers remains a challenge due to issues like hallucinations, key information omissions, and verbosity in LLM-generated summaries. This work explores using LLM-generated feedback to improve summary quality by aligning the summaries with human preferences for faithfulness, completeness, and conciseness. We introduce FeedSum, a large-scale dataset containing multi-dimensional LLM feedback on summaries of varying quality across diverse domains. Our experiments show how feedback quality, dimensionality, and granularity influence preference learning, revealing that high-quality, multi-dimensional, fine-grained feedback significantly improves summary generation. We also compare two methods for using this feedback: supervised fine-tuning and direct preference optimization. Finally, we introduce SummLlama3-8b, a model that outperforms the nearly 10x larger Llama3-70b-instruct in generating human-preferred summaries, demonstrating that smaller models can achieve superior performance with appropriate training. The full dataset will be released soon. The SummLlama3-8B model is now available at https://huggingface.co/DISLab/SummLlama3-8B.
BAPO: Base-Anchored Preference Optimization for Personalized Alignment in Large Language Models
Jun 30, 2024While learning to align Large Language Models (LLMs) with human preferences has shown remarkable success, aligning these models to meet the diverse user preferences presents further challenges in preserving previous knowledge. This paper examines the impact of personalized preference optimization on LLMs, revealing that the extent of knowledge loss varies significantly with preference heterogeneity. Although previous approaches have utilized the KL constraint between the reference model and the policy model, we observe that they fail to maintain general knowledge and alignment when facing personalized preferences. To this end, we introduce Base-Anchored Preference Optimization (BAPO), a simple yet effective approach that utilizes the initial responses of reference model to mitigate forgetting while accommodating personalized alignment. BAPO effectively adapts to diverse user preferences while minimally affecting global knowledge or general alignment. Our experiments demonstrate the efficacy of BAPO in various setups.
FedFN: Feature Normalization for Alleviating Data Heterogeneity Problem in Federated Learning
Nov 22, 2023Federated Learning (FL) is a collaborative method for training models while preserving data privacy in decentralized settings. However, FL encounters challenges related to data heterogeneity, which can result in performance degradation. In our study, we observe that as data heterogeneity increases, feature representation in the FedAVG model deteriorates more significantly compared to classifier weight. Additionally, we observe that as data heterogeneity increases, the gap between higher feature norms for observed classes, obtained from local models, and feature norms of unobserved classes widens, in contrast to the behavior of classifier weight norms. This widening gap extends to encompass the feature norm disparities between local and the global models. To address these issues, we introduce Federated Averaging with Feature Normalization Update (FedFN), a straightforward learning method. We demonstrate the superior performance of FedFN through extensive experiments, even when applied to pretrained ResNet18. Subsequently, we confirm the applicability of FedFN to foundation models.
Distort, Distract, Decode: Instruction-Tuned Model Can Refine its Response from Noisy Instructions
Nov 01, 2023



While instruction-tuned language models have demonstrated impressive zero-shot generalization, these models often struggle to generate accurate responses when faced with instructions that fall outside their training set. This paper presents Instructive Decoding (ID), a simple yet effective approach that augments the efficacy of instruction-tuned models. Specifically, ID adjusts the logits for next-token prediction in a contrastive manner, utilizing predictions generated from a manipulated version of the original instruction, referred to as a noisy instruction. This noisy instruction aims to elicit responses that could diverge from the intended instruction yet remain plausible. We conduct experiments across a spectrum of such noisy instructions, ranging from those that insert semantic noise via random words to others like 'opposite' that elicit the deviated responses. Our approach achieves considerable performance gains across various instruction-tuned models and tasks without necessitating any additional parameter updates. Notably, utilizing 'opposite' as the noisy instruction in ID, which exhibits the maximum divergence from the original instruction, consistently produces the most significant performance gains across multiple models and tasks.
FedSoL: Bridging Global Alignment and Local Generality in Federated Learning
Aug 24, 2023



Federated Learning (FL) aggregates locally trained models from individual clients to construct a global model. While FL enables learning a model with data privacy, it often suffers from significant performance degradation when client data distributions are heterogeneous. Many previous FL algorithms have addressed this issue by introducing various proximal restrictions. These restrictions aim to encourage global alignment by constraining the deviation of local learning from the global objective. However, they inherently limit local learning by interfering with the original local objectives. Recently, an alternative approach has emerged to improve local learning generality. By obtaining local models within a smooth loss landscape, this approach mitigates conflicts among different local objectives of the clients. Yet, it does not ensure stable global alignment, as local learning does not take the global objective into account. In this study, we propose Federated Stability on Learning (FedSoL), which combines both the concepts of global alignment and local generality. In FedSoL, the local learning seeks a parameter region robust against proximal perturbations. This strategy introduces an implicit proximal restriction effect in local learning while maintaining the original local objective for parameter update. Our experiments show that FedSoL consistently achieves state-of-the-art performance on various setups.
The Multi-modality Cell Segmentation Challenge: Towards Universal Solutions
Aug 10, 2023Cell segmentation is a critical step for quantitative single-cell analysis in microscopy images. Existing cell segmentation methods are often tailored to specific modalities or require manual interventions to specify hyperparameters in different experimental settings. Here, we present a multi-modality cell segmentation benchmark, comprising over 1500 labeled images derived from more than 50 diverse biological experiments. The top participants developed a Transformer-based deep-learning algorithm that not only exceeds existing methods, but can also be applied to diverse microscopy images across imaging platforms and tissue types without manual parameter adjustments. This benchmark and the improved algorithm offer promising avenues for more accurate and versatile cell analysis in microscopy imaging.
MEDIAR: Harmony of Data-Centric and Model-Centric for Multi-Modality Microscopy
Dec 07, 2022



Cell segmentation is a fundamental task for computational biology analysis. Identifying the cell instances is often the first step in various downstream biomedical studies. However, many cell segmentation algorithms, including the recently emerging deep learning-based methods, still show limited generality under the multi-modality environment. Weakly Supervised Cell Segmentation in Multi-modality High-Resolution Microscopy Images was hosted at NeurIPS 2022 to tackle this problem. We propose MEDIAR, a holistic pipeline for cell instance segmentation under multi-modality in this challenge. MEDIAR harmonizes data-centric and model-centric approaches as the learning and inference strategies, achieving a 0.9067 F1-score at the validation phase while satisfying the time budget. To facilitate subsequent research, we provide the source code and trained model as open-source: https://github.com/Lee-Gihun/MEDIAR
Self-Contrastive Learning
Jul 14, 2021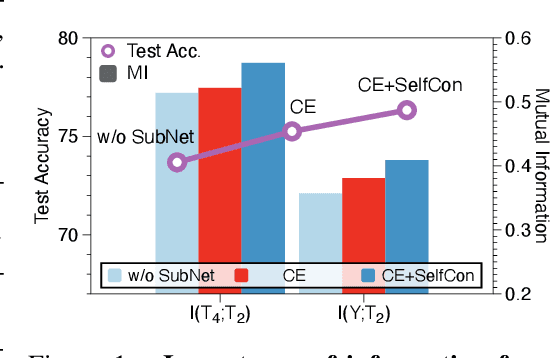
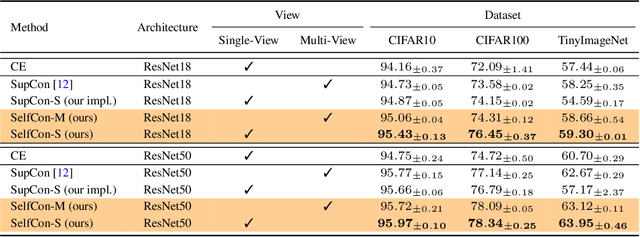
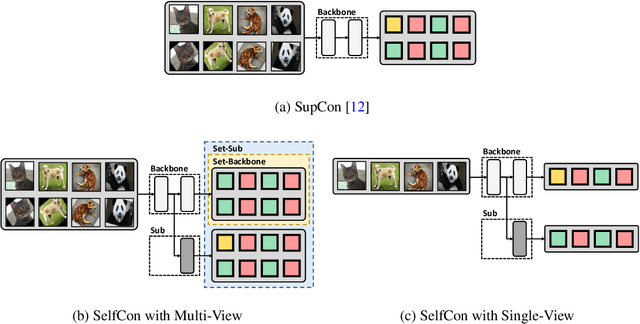
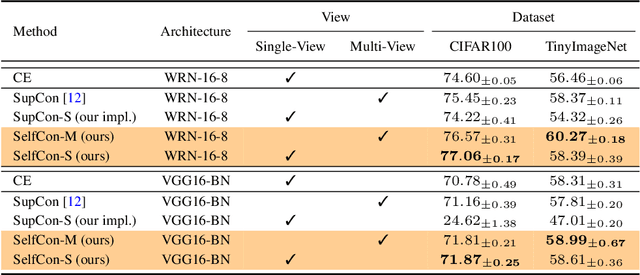
This paper proposes a novel contrastive learning framework, coined as Self-Contrastive (SelfCon) Learning, that self-contrasts within multiple outputs from the different levels of a network. We confirmed that SelfCon loss guarantees the lower bound of mutual information (MI) between the intermediate and last representations. Besides, we empirically showed, via various MI estimators, that SelfCon loss highly correlates to the increase of MI and better classification performance. In our experiments, SelfCon surpasses supervised contrastive (SupCon) learning without the need for a multi-viewed batch and with the cheaper computational cost. Especially on ResNet-18, we achieved top-1 classification accuracy of 76.45% for the CIFAR-100 dataset, which is 2.87% and 4.36% higher than SupCon and cross-entropy loss, respectively. We found that mitigating both vanishing gradient and overfitting issue makes our method outperform the counterparts.
Preservation of the Global Knowledge by Not-True Self Knowledge Distillation in Federated Learning
Jun 06, 2021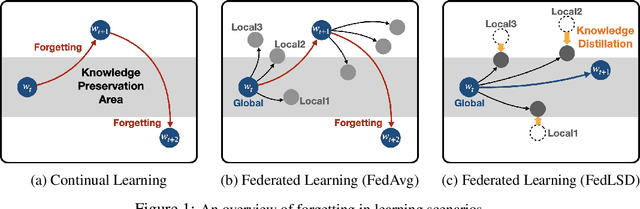


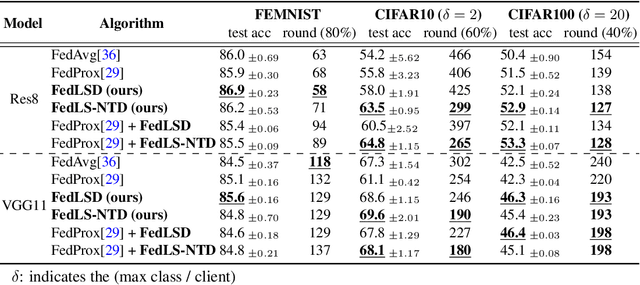
In Federated Learning (FL), a strong global model is collaboratively learned by aggregating the clients' locally trained models. Although this allows no need to access clients' data directly, the global model's convergence often suffers from data heterogeneity. This paper suggests that forgetting could be the bottleneck of global convergence. We observe that fitting on biased local distribution shifts the feature on global distribution and results in forgetting of global knowledge. We consider this phenomenon as an analogy to Continual Learning, which also faces catastrophic forgetting when fitted on the new task distribution. Based on our findings, we hypothesize that tackling down the forgetting in local training relives the data heterogeneity problem. To this end, we propose a simple yet effective framework Federated Local Self-Distillation (FedLSD), which utilizes the global knowledge on locally available data. By following the global perspective on local data, FedLSD encourages the learned features to preserve global knowledge and have consistent views across local models, thus improving convergence without compromising data privacy. Under our framework, we further extend FedLSD to FedLS-NTD, which only considers the not-true class signals to compensate noisy prediction of the global model. We validate that both FedLSD and FedLS-NTD significantly improve the performance in standard FL benchmarks in various setups, especially in the extreme data heterogeneity cases.
MixCo: Mix-up Contrastive Learning for Visual Representation
Oct 13, 2020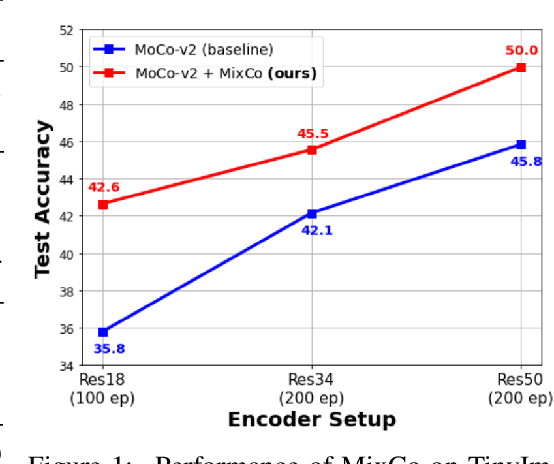
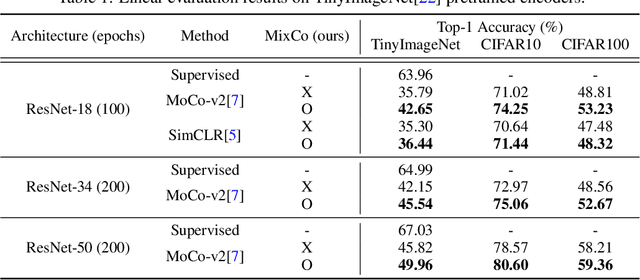


Contrastive learning has shown remarkable results in recent self-supervised approaches for visual representation. By learning to contrast positive pairs' representation from the corresponding negatives pairs, one can train good visual representations without human annotations. This paper proposes Mix-up Contrast (MixCo), which extends the contrastive learning concept to semi-positives encoded from the mix-up of positive and negative images. MixCo aims to learn the relative similarity of representations, reflecting how much the mixed images have the original positives. We validate the efficacy of MixCo when applied to the recent self-supervised learning algorithms under the standard linear evaluation protocol on TinyImageNet, CIFAR10, and CIFAR100. In the experiments, MixCo consistently improves test accuracy. Remarkably, the improvement is more significant when the learning capacity (e.g., model size) is limited, suggesting that MixCo might be more useful in real-world scenarios.