 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Contrastive Learning
Jul 14, 2021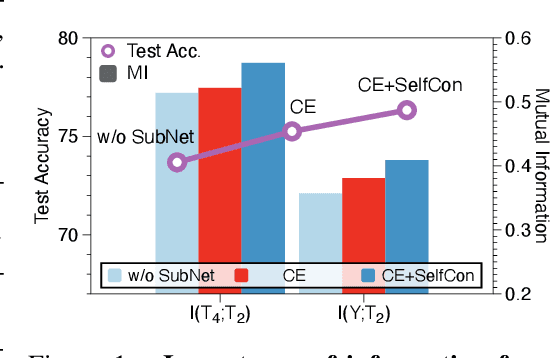
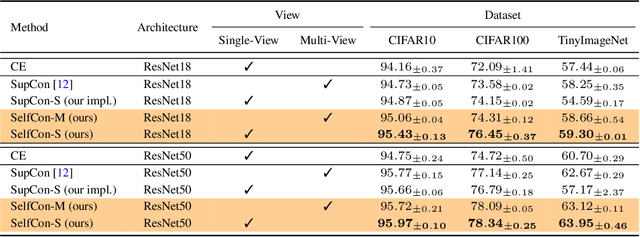
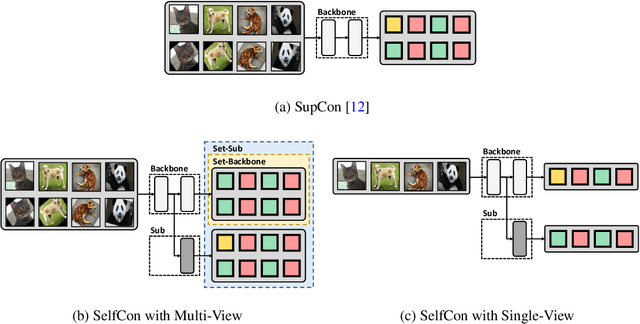
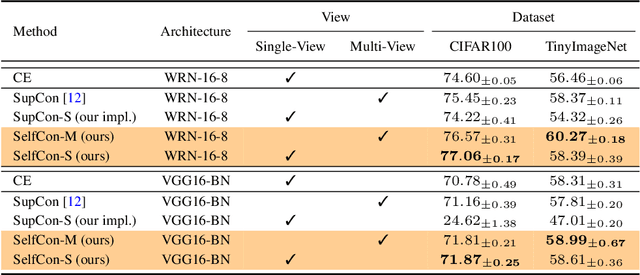
This paper proposes a novel contrastive learning framework, coined as Self-Contrastive (SelfCon) Learning, that self-contrasts within multiple outputs from the different levels of a network. We confirmed that SelfCon loss guarantees the lower bound of mutual information (MI) between the intermediate and last representations. Besides, we empirically showed, via various MI estimators, that SelfCon loss highly correlates to the increase of MI and better classification performance. In our experiments, SelfCon surpasses supervised contrastive (SupCon) learning without the need for a multi-viewed batch and with the cheaper computational cost. Especially on ResNet-18, we achieved top-1 classification accuracy of 76.45% for the CIFAR-100 dataset, which is 2.87% and 4.36% higher than SupCon and cross-entropy loss, respectively. We found that mitigating both vanishing gradient and overfitting issue makes our method outperform the counterparts.